

Let's start...
Graphs Algorithms For Interview Preparation
Table of Content :
- BFS
- DFS
- Detect A Cycle in Undirected graph
- Using BFS
- Using DFS
- Detect A Cycle in Directed graph
- Using BFS (Toposort)
- Using DFS
- Topological sort
- Using Queue + BFS (Kahn's Algo)
- Using Stack + DFS
- Bipartite Graph
- Using BFS
- Using DFS
- Number of connected components
- Using BFS (Do in Grid and Graph Both)
- Using DFS (Do in Grid and Graph Both)
- Kosarajus For SCC (2 times DFS)
- Dijkstra's Algorithm [single source shortest path algorithm (SSSP)]
- Bellman Ford Algorithm [single-source shortest path algorithm (SSSP)]
- Floyd-warshall Algorithm [multisource shortest path algorithm]
- MST using Prim's Algo
- Disjoint set (Union-Find)
- Union by Rank
- Union by size
- MST using Kruskal's Algo
- Tarjans For SCC (1 time DFS only)
- Bridges in graph
- Articulation Point/vertex
1. BFS (Breadth First Search)
BFS code [ C++ Code ]
Time Complexity : O(N) + O(2E) ~ O(V + E), N for each node is enqueued and dequeued once and for each node, edges are traversed once. For undirected graph each edge is considered twice. Where N = Nodes, 2E is for total degrees as we traverse all adjacent nodes.
Space Complexity : O(3N) ~ O(N), Space for queue data structure, visited array and an adjacency list.
#include<bits/stdc++.h>
using namespace std;
void BFS_Traversal(unordered_map<int, set<int>>&g, int src, int V, vector<int>&vis,vector<int>&ans)
{
queue<int>q;
// The task is to do Breadth First Traversal of this graph starting from 0.
q.push(src);
vis[src]=1;
while(!q.empty())
{
auto cur = q.front();
ans.push_back(cur);
q.pop();
// explore neighbour
for(auto nbr : g[cur])
{
if(vis[nbr]==0){
vis[nbr]=1;
q.push(nbr);
}
}
}
}
vector<int> BFS(int V, vector<pair<int, int>> edges)
{
vector<int>ans; // bfs traversal for graph
// unordered_map<int, vector<int>>g; we did not take vector because we want to visit node in
// sorted order
unordered_map<int, set<int>>g;
vector<int>vis(V,0); // no. of vetices
for(auto &e : edges){
g[e.first].insert(e.second);
g[e.second].insert(e.first);
}
// handle for disconnected graphs as well
for(int i=0;i<V;i++){
if(vis[i]==0){
BFS_Traversal(g,i,V,vis,ans);
}
}
return ans;
}Clone Graph using BFS (Practice problem) [ C++ Code ]
Practice problem link : https://leetcode.com/problems/clone-graph/description/
Practice problem link : https://leetcode.com/problems/word-ladder/description/
Practice problem link : https://leetcode.com/problems/word-ladder-ii/
class Solution {
public:
Node* cloneGraph(Node* node) {
if (node == NULL)
return node;
unordered_map<Node*, Node*> mp;
queue<Node*> q;
q.push(node);
mp[node] = new Node(node->val); // map's key is old node and value is clone counter parts of that node
while (!q.empty()) {
Node* cur = q.front();
q.pop();
for (auto& nbr : cur->neighbors) {
if (mp.find(nbr) == mp.end()) { //copy not present means lets create the copy for this neighbor also
mp[nbr] = new Node(nbr->val);
q.push(nbr);
}
// Establish new connection for new graph
mp[cur]->neighbors.push_back(mp[nbr]); // have to update the neighbours for the clone counter parts as well
}
}
return mp[node];
}
};2. DFS (Depth First Search)
DFS code [ C++ Code ]
Time Complexity : For an undirected graph, O(N) + O(2E), For a directed graph, O(N) + O(E), Because for every node we are calling the recursive function once, the time taken is O(N) and 2E is for total degrees as we traverse for all adjacent nodes.
Space Complexity : O(3N) ~ O(N), Space for dfs stack space, visited array and an adjacency list.
#include<bits/stdc++.h>
using namespace std;
void dfs(int src, unordered_map<int, vector<int>>g, vector<int>&vis, vector<int>&dfsForComponent)
{
vis[src] = 1;
dfsForComponent.push_back(src);
for(auto &x : g[src])
{
if(vis[x] == 0)
{
dfs(x,g,vis,dfsForComponent);
}
}
}
vector<vector<int>> depthFirstSearch(int V, int E, vector<vector<int>> &edges)
{
vector<int>vis(V,0);
vector<vector<int>>ans; // max connected components = when all are single
unordered_map<int, vector<int>>g;
for(auto &e : edges){
g[e[0]].push_back(e[1]);
g[e[1]].push_back(e[0]);
}
for(int i=0;i<V;i++)
if(vis[i]==0){
vector<int>dfsForComponent;
dfs(i,g,vis,dfsForComponent);
ans.push_back(dfsForComponent);
}
return ans;
}Clone Graph using DFS (Practice problem) [ C++ Code ]
Practice problem link : https://leetcode.com/problems/clone-graph/description/
class Solution {
public:
void dfs(Node* node, unordered_map<Node*, Node*> &mp) {
Node* copy = new Node(node->val);
mp[node] = copy; // map's key is old node and value is clone counter parts of that node
for (auto nbr : node->neighbors) {
if (mp.find(nbr) == mp.end()) {
dfs(nbr, mp);
}
copy->neighbors.push_back(mp[nbr]); // have to update the neighbours for the clone counter parts as well
}
}
Node* cloneGraph(Node* node) {
if (node == NULL) return NULL;
if (node->neighbors.size() == 0) {
Node* clone = new Node(node->val);
return clone;
}
unordered_map<Node*, Node*> mp;
dfs(node, mp);
return mp[node];
}
};3. Detect A cycle in Undirected Graph :
Intuition : each any node that has been previously visited in the past; it means there's a cycle.
BFS Code [ C++ Code ]
Practice : you can solve this problem on gfg.
Time Complexity : O(V+2E) ~ O(V+E), As for each vertex we are traversing the edge, Each edge is considered twice (once from each vertex it connects).
Space Complexity : O(N) + O(N) ~ O(N), space for queue data structure and visited array.
class Solution {
public:
bool checkForCycle(int src, vector<int>& vis, vector<vector<int>>& adj) {
queue<pair<int,int>>q; // {node, parent}
q.push({src, -1});
vis[src] = 1;
while(!q.empty()) {
int node = q.front().first;
int parent = q.front().second;
q.pop();
for (auto &nbr: adj[node]) {
if (!vis[nbr]) {
vis[nbr] = 1;
q.push({nbr, node});
} else if (parent != nbr) {
// already visited but not a parent node
// visited nbr is not equal to parent, it means
// we have node which is adjacent of node but visited previously via some other node.
return true;
}
}
}
return false;
}
bool isCycle(vector<vector<int>>& adj) {
int n = adj.size();
vector<int>vis(n,0);
for(int i=0;i<n;i++) { // check for all the components
if(!vis[i]) {
if (checkForCycle(i, vis, adj)) return true; // yes, cycle exist
}
}
return false;
}
};DFS Code [ C++ Code ]
Practice : you can solve this problem on gfg.
Time Complexity : O(V+2E) ~ O(V+E), For each vertex we are traversing the edge, Each edge is considered twice (once from each vertex it connects).
Space Complexity : O(N) + O(N) ~ O(N), space for recursive stack space and visited array.
class Solution {
public:
bool checkForCycle(int src, int parent, vector<int>& vis, vector<vector<int>>& adj) {
vis[src] = 1; // marking this as visited
// iterate through all its neighbours
for(auto &nbr : adj[src]) {
if(!vis[nbr]) {
if (checkForCycle(nbr, src, vis, adj)) return true;
} else if (parent != nbr) {
// already visited but not a parent node
return true;
}
}
return false;
}
bool isCycle(vector<vector<int>>& adj) {
int n = adj.size();
vector<int>vis(n,0);
for(int i=0;i<n;i++) { // check for all the components
if(!vis[i]) {
// taking parent for new starting node of a component as -1
if (checkForCycle(i, -1, vis, adj)) return true; // yes, cycle exist
}
}
return false;
}
};4. Detect A cycle in Directed Graph :
BFS Code (Using Toposort) [ C++ Code ]
Using Kahn's Algorithm for topological sort.
Toposort possible for DAG, so if there is cycle in directed graph toposort is not possible.
Practice : you can solve this problem on gfg.
Time Complexity : O(V+E), Similar to BFS.
Space Complexity : O(2N), N for queue data structure for storing nodes, and another N for indegree array.
int detectCycleInDirectedGraph(int n, vector < pair < int, int >> & edges)
{
unordered_map<int, vector<int>>g;
vector<int>indegree(n+1,0);
for(auto &e : edges){
g[e.first].push_back(e.second); // directed graph
indegree[e.second]++;
}
queue<int>q;
for(int i=1;i<=n;i++){
if(indegree[i]==0)
q.push(i);
}
int cnt=0;
while(!q.empty())
{
auto cur = q.front();
q.pop();
cnt++;
for(auto &nbr : g[cur]){
indegree[nbr]--;
if(indegree[nbr]==0)
q.push(nbr);
}
}
if(cnt==n) return false;
return true;
}DFS Code [ C++ Code ]


Explanation :
If in the same recursive call, vis and dfsVis both shows as visited it means in the same movement we have reached a node for the 2nd time. it means there is a cycle in directed graph.
e.g
start dfs from node 1 - you will not found any cycle
start dfs from node 7 - you will found a cycle (i.e vis[7] = 1, dfsVis[7] = 1)
Practice : you can solve this problem on gfg.
Time Complexity : O(V+E), Similar to DFS.
Space Complexity : O(2N), N for visited array, and another N for dfsVis array.
#include<bits/stdc++.h>
using namespace std;
bool checkForCycle(int node, unordered_map<int, vector<int>>&g, vector<int>&vis, vector<int>&dfsvis)
{
vis[node] = 1;
dfsvis[node] = 1;
for (auto it : g[node])
{
if(!vis[it])
{
if(checkForCycle(it, g, vis, dfsvis))
return true;
}
else if (dfsvis[it])
return true;
}
dfsvis[node] = 0; // make unvisited
return false;
}
int detectCycleInDirectedGraph(int n, vector < pair < int, int >> & edges)
{
unordered_map<int, vector<int>>g;
for(auto &e : edges){
g[e.first].push_back(e.second); // directed graph
}
vector<int> vis(n+1, 0);
vector<int> dfsvis(n+1, 0);
for (int i=1;i<=n;i++)
{
if (!vis[i])
{
if (checkForCycle(i, g, vis, dfsvis))
return true;;
}
}
return false;
}5. Topological Sort : Linear ordering of vertices. Sort the vertices on the basis of their Finishing Time.
(a) Toposort using Queue + BFS (Kahn's algorithm) [ C++ Code ]
Practice problems :
- https://leetcode.com/problems/course-schedule/
- https://leetcode.com/problems/course-schedule-ii/
- https://leetcode.com/problems/find-eventual-safe-states/
- https://leetcode.com/problems/alien-dictionary/description/
Time Complexity : O(N + E)
Space Complexity : O(N) + O(N) ~ O(N), for queue data structure and indegree array.
#include<bits/stdc++.h>
using namespace std;
vector<int> topologicalSort(vector<vector<int>> &edges, int n, int e) {
unordered_map<int, vector<int>>g;
vector<int>indegree(n,0);
for(auto &e : edges){
g[e[0]].push_back(e[1]); // directed graph
indegree[e[1]]++;
}
queue<int>q;
for(int i=0;i<n;i++){
if(indegree[i]==0)
q.push(i);
}
vector<int>topo;
while(!q.empty())
{
auto cur = q.front();
q.pop();
topo.push_back(cur);
for(auto &nbr : g[cur]){
indegree[nbr]--;
if(indegree[nbr]==0)
q.push(nbr);
}
}
return topo;
}(b) TopoSort using Stack + DFS [ C++ Code ]
Time Complexity : O(N + E)
Space Complexity : O(N) + O(N) ~ O(N), for auxiliary recursive stack space and visited array.
void dfs(int node, vector<int>&vis, stack<int>&st, unordered_map<int, vector<int>>&g) {
vis[node] = 1;
for (auto it: g[node]) {
if (!vis[it]) {
dfs(it, vis, st, g);
}
}
st.push(node); // important line
}
vector<int> topologicalSort(vector<vector<int>> &edges, int n, int e) {
unordered_map<int, vector<int>>g;
for(auto &e : edges){
g[e[0]].push_back(e[1]); // directed graph
}
stack<int>st; // stack stores toposort
vector<int>vis(n, 0);
for (int i = 0; i < n; i++){
if (vis[i] == 0) {
dfs(i, vis, st, g);
}
}
vector<int>topo;
while (!st.empty()) {
topo.push_back(st.top());
st.pop();
}
return topo;
}6. Bipartite Graph : A bipartite graph is a graph which can be coloured using 2 colours such that no adjacent nodes have the same colour. Any linear graph with no cycle is always a bipartite graph. With a cycle, any graph with an even cycle length can also be a bipartite graph. So, any graph with an odd cycle length can never be a bipartite graph.
Problem : Check if there is a cycle with odd length in a graph.
Practice problem link : https://leetcode.com/problems/is-graph-bipartite/
Bipartite's check using DFS [ C++ Code ]
Intuition : The intuition is the brute force of filling colours using any traversal technique, just make sure no two adjacent nodes have the same colour. If at any moment of traversal, we find the adjacent nodes to have the same colour, it means that there is an odd cycle, or it cannot be a bipartite graph.
Time Complexity : O(V + 2E), Where V = Vertices, 2E is for total degrees as we traverse all adjacent nodes.
Space Complexity : O(3V) ~ O(V), Space for DFS stack space, colour array and an adjacency list.
// Acyclic/Linear - yes a bipartite graph
// Cyclic - even length (yes a bipartite graph)
// Cyclic - odd length (Not a bipartite graph)
class Solution {
public:
bool DFS(int src, int col, vector<vector<int>>& g, vector<int>& color) {
color[src] = col;
// traverse adjacent nodes
for (auto& nbr : g[src]) {
// if uncoloured
if (color[nbr] == -1) {
if (DFS(nbr, !col, g, color) == false)
return false;
}
// if previously coloured and have the same colour as the parent
else if (color[nbr] == color[src])
return false;
}
return true;
}
bool isBipartite(vector<vector<int>>& g) {
int n = g.size(); // no. of nodes
vector<int> color(n, -1); // color array works as the visited array for the DFS, initially no one is coloured
// The graph may not be connected, meaning there may be two nodes u and
// v such that there is no path between them. so check for all the components of graph.
for (int i = 0; i < n; i++) {
if (color[i] == -1) {
if (DFS(i, 0, g, color) == false) {
return false;
}
}
}
return true;
}
};Bipartite's check using BFS [ C++ Code ]
Time Complexity : O(V + 2E), Where V = Vertices, 2E is for total degrees as we traverse all adjacent nodes.
Space Complexity : O(3V) ~ O(V), Space for DFS stack space, colour array and an adjacency list.
class Solution {
public:
bool BFS(int src, vector<vector<int>>& g, vector<int>& color) {
int n = g.size(); // no. of nodes
queue<int> q;
q.push(src);
color[src] = 0; // initial color for src
while (!q.empty()) {
auto cur = q.front();
q.pop();
for (auto& nbr : g[cur]) {
// if it is unvisited
if (color[nbr] == -1) {
color[nbr] = color[cur] ? 0 : 1;
q.push(nbr);
}
// if previously coloured and have the same colour as the parent
else if (color[nbr] == color[cur])
return false;
}
}
return true;
}
bool isBipartite(vector<vector<int>>& g) {
int n = g.size(); // no. of nodes
vector<int> color(n, -1);
// The graph may not be connected, meaning there may be two nodes u and
// v such that there is no path between them. so check for all the components of graph.
for (int i = 0; i < n; i++) {
if (color[i] == -1) {
if (BFS(i, g, color) == false) {
return false;
}
}
}
return true;
}
};7. Number of connected components :
BFS Code (generic template) [ C++ Code ]
Practice problem link : https://leetcode.com/problems/number-of-islands/
Practice problem link : https://leetcode.com/problems/flood-fill/
Practice problem link : https://leetcode.com/problems/pacific-atlantic-water-flow/
Practice problem link : https://leetcode.com/problems/max-area-of-island/
Practice problem link : https://leetcode.com/problems/making-a-large-island/
Practice problem link : https://leetcode.com/problems/detonate-the-maximum-bombs/
Practice problem link : https://leetcode.com/problems/surrounded-regions/
Practice problem link : https://leetcode.com/problems/number-of-enclaves/
Practice problem link : https://leetcode.com/problems/shortest-path-in-binary-matrix/
Practice problem link : https://leetcode.com/problems/number-of-operations-to-make-network-connected/
Practice problem link : https://leetcode.com/problems/path-with-minimum-effort/
Practice problem link : https://leetcode.com/problems/unique-paths-iii/
Time Complexity : O(N*M), total visited cells of matrix at once.
Space Complexity : O(N*M), space for visited array.
class Solution {
public:
void bfs(vector<vector<char>>& grid, vector<vector<int>>& vis, int i, int j, int m, int n) {
int dx[4] = {-1, 0, 1, 0};
int dy[4] = {0, -1, 0, 1};
queue<pair<int, int>> q;
q.push({i, j}); // source
vis[i][j] = 1;
while (!q.empty()) {
auto p = q.front();
q.pop();
for (int i = 0; i < 4; i++) // check for all four directions
{
int nr = p.first + dx[i];
int nc = p.second + dy[i];
if (nr >= 0 && nr < m && nc >= 0 && nc < n && vis[nr][nc] == 0 && grid[nr][nc] == '1') {
vis[nr][nc] = 1;
q.push({nr, nc}); // push until we are able to find the land or connected components
}
}
}
}
int numIslands(vector<vector<char>>& grid) {
int m = grid.size();
int n = grid[0].size();
vector<vector<int>> vis(m, vector<int>(n, 0));
int components = 0; // number of islands
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (vis[i][j] == 0 && grid[i][j] == '1') {
bfs(grid, vis, i, j, m, n);
components++;
}
}
}
return components;
}
};DFS Code (generic template) [ C++ Code ]
Practice problem link : https://leetcode.com/problems/number-of-islands/
Practice problem link : https://leetcode.com/problems/flood-fill/
Time Complexity : O(N*M), total visited cells of matrix at once.
Space Complexity : O(N*M), space for visited array.
class Solution {
public:
void dfs(int i, int j, int m, int n, vector<vector<int>>& vis, vector<vector<char>>& grid) {
if (i < 0 || i >= m || j < 0 || j >= n)
return;
if (vis[i][j] == 1 || grid[i][j] == '0')
return;
vis[i][j] = 1;
dfs(i - 1, j, m, n, vis, grid);
dfs(i, j - 1, m, n, vis, grid);
dfs(i + 1, j, m, n, vis, grid);
dfs(i, j + 1, m, n, vis, grid);
}
int numIslands(vector<vector<char>>& grid) {
int m = grid.size();
int n = grid[0].size();
vector<vector<int>> vis(m, vector<int>(n, 0));
int components = 0; // number of islands
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (vis[i][j] == 0 && grid[i][j] == '1') {
dfs(i, j, m, n, vis, grid);
components++;
}
}
}
return components;
}
};DFS Code (when graph is given as 0,1 matrix) [ C++ Code ]
Practice problem link : https://leetcode.com/problems/number-of-provinces/
// matrix of 0, 1 given
// 1 - there is an edge
// 0 - there is no edge
class Solution {
public:
void DFS(int src, vector<int>& vis, unordered_map<int, vector<int>>& g) {
vis[src] = 1; // mark as visited
// iterate all the neighbours
for (auto& nbr : g[src]) {
if (!vis[nbr]) {
DFS(nbr, vis, g);
}
}
}
int findCircleNum(vector<vector<int>>& isConnected) {
int n = isConnected.size();
unordered_map<int, vector<int>> g; // graph (adjacency list)
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
if (isConnected[i][j] == 1) {
// no need to add reverse edge because matrix loop will take care of this.
g[i + 1].push_back(j + 1);
}
}
}
vector<int> vis(n + 1, 0); // 1 based node values
int components = 0;
for (int i = 1; i <= n; i++) { // loop from (1 -> n) instead of (0 to n-1)
if (!vis[i]) {
DFS(i, vis, g);
components++;
}
}
return components;
}
};
// Follow - up : Without creating unordered map, use same matrix as graph.
class Solution {
public:
void dfs(int src, vector<int>& vis, vector<vector<int>>& isConnected) {
vis[src] = 1;
for (int j = 0; j < isConnected.size(); j++) {
if (isConnected[src][j] == 1 && !vis[j]) {
dfs(j, vis, isConnected);
}
}
}
// Bidirectional graph is given => isConnected[i][j] == isConnected[j][i]
int findCircleNum(vector<vector<int>>& isConnected) {
int n = isConnected.size(); // nxn matrix
vector<int> vis(n, 0);
int components = 0;
for (int i = 0; i < n; i++) {
if (!vis[i]) {
dfs(i, vis, isConnected);
components++;
}
}
return components;
}
};Steps by Knight Problem (BFS on grid) [ C++ Code ]
class Solution {
public:
// Function to find out minimum steps Knight needs to reach target position.
// nxn chessboard given - Using BFS
int minStepToReachTarget(vector<int>&KnightPos, vector<int>&TargetPos, int n)
{
// initial position
int x1 = KnightPos[0];
int y1 = KnightPos[1];
// target position
int x2 = TargetPos[0];
int y2 = TargetPos[1];
if(x1 == x2 and y1 == y2) return 0; // already at target position
vector<vector<int>>vis(n+1, vector<int>(n+1, 0));
/*
// 8 places possible where Knight can move
1 2
🟩🟩🟩
8 🟩 🟩 🟩 3
🟩🟩🟥🟩🟩
7 🟩 🟩 🟩 4
🟩🟩🟩
6 5
*/
vector<vector<int>>dir = {{-2,-1},{-2,1},
{-1,2}, {1,2},
{2,-1},{2,1},
{-1,-2},{1,-2}};
queue<pair<int,int>>q;
q.push({x1-1,y1-1}); // convert into 0th based indexing
vis[x1-1][y1-1]=1; // mark it as visited
int steps=0;
while(!q.empty())
{
int sz = q.size();
while(sz--)
{
auto cur = q.front();
int i = cur.first;
int j = cur.second;
q.pop();
if(x2-1==i and y2-1==j) return steps;
for(auto &d : dir)
{
int ni = i+d[0];
int nj = j+d[1];
if(ni>=0 and ni<n and nj>=0 and nj<n and vis[ni][nj]==0){
q.push({ni,nj});
vis[ni][nj]=1;
}
}
}
steps++;
}
return -1;
}
};8. Kosaraju's Algorithm [Strongly connected components are only valid for directed graphs]
3 steps for Kosaraju's Algo - Used to find SCC (Strongly Connected Components) :
(i) Do DFS : Sort all the nodes in order of their finishing time (It not a Toposort but it's like that, BFS will not work because we have no nodes with indegree zero)
(ii) Transpose/reverse the graph (Reverse all the edges of the entire graph)
(iii) Do DFS according to the Finishing time and count the no. of different DFS calls to get the no. of SCCs.
Note : components are strongly connected when every node can be reachable via each node in that component.
Problem 1 : No. of scc
Problem 2 : Print the all scc
Kosaraju's code [ C++ Code ]
Its not a DAG, so its not toposort we are just getting nodes in sorted order of their finishing time. BFS wil not work.

Time Complexity : O(V+E) + O(V+E) + O(V+E) ~ O(V+E) , where V = no. of vertices, E = no. of edges. The first step is a simple DFS, so the first term is O(V+E). The second step of reversing the graph and the third step, containing DFS again, will take O(V+E) each.
Space Complexity : O(V)+O(V)+O(V+E), where V = no. of vertices, E = no. of edges. Two O(V) for the visited array and the stack we have used. O(V+E) space for the reversed graph.
#include<bits/stdc++.h>
using namespace std;
void toposort_dfs(int node, stack<int> &st, vector<int> &vis, vector<vector<int>>&g) {
vis[node] = 1;
for(auto it: g[node]) {
if(!vis[it]) {
toposort_dfs(it, st, vis, g);
}
}
st.push(node);
}
void revDfs(int node, vector<int> &vis, vector<vector<int>>&transpose, vector<int>&ans) {
ans.push_back(node);
vis[node] = 1;
for(auto it: transpose[node]) {
if(!vis[it]) {
revDfs(it, vis, transpose, ans);
}
}
}
vector<vector<int>> stronglyConnectedComponents(int n, vector<vector<int>>&edges)
{
// two graphs one is normal and other is transpose
vector<vector<int>>g(n,vector<int>{});
vector<vector<int>>transpose(n, vector<int>{});
for(auto &e:edges){
g[e[0]].push_back(e[1]);
}
vector<int>vis(n,0);
stack<int>st;
// step-1
for(int i=0;i<n;i++){
if(!vis[i])
toposort_dfs(i, st, vis, g);
}
// step-2
for(auto &e:edges){
transpose[e[1]].push_back(e[0]);
}
// step-3
vis = vector<int>(n,0);
vector<vector<int>>fans;// final answer
while(!st.empty())
{
int i = st.top();
st.pop();
if(!vis[i])
{
vector<int>ans;
revDfs(i, vis, transpose, ans);
fans.push_back(ans);
}
}
return fans;
}9. Dijkstra's Algorithm
Dijkstra's Algorithm for shortest path from "src" to "every node". Also known as "single source shortest path (SSSP)" algorithm.
Condition check before using Dijkstra's Algo : Dijkstra's algorithm works for both directed and undirected graphs, provided that all edge weights are non-negative. Dijkstra can't work for graphs which has negative weights, it will stuck in infinite loop, it will go and keep reducing the distance -2...-4....-82737..... Everytime it will find lesser distance.
Approach - 1 : Using Priority queue (Standard) [ C++ Code ]
Practice problem link : https://leetcode.com/problems/cheapest-flights-within-k-stops/
Practice problem link : https://leetcode.com/problems/find-the-city-with-the-smallest-number-of-neighbors-at-a-threshold-distance/
Practice problem link : https://leetcode.com/problems/network-delay-time/
IMP Note : Why Priority Queue and not a Queue ?
- Because in that case we will be doing unneccessary iterations or occurences/exploration of paths and we are going to each
path and finding the minimal of all. but in case of priority queue we will be only taking the path with only minimal distances.
- using a queue kind of doing brute force and it will take lots of time. Steps : Important points to remember regarding the code
(i) store {dist, node} in min heap
(ii) make distTo array for storing distances of all nodes from "src"
(iii) Update the shortest distance if it is found from "src" to that "node"
Time Complexity : O(ElogV)
Space Complexity : O(E) + O(V) { O(E) for priority queue and O(V) for dist array } Where E = Number of edges and V = Number of Nodes.
#include<bits/stdc++.h>
using namespace std;
typedef pair<int,int>ppi; // {dist, node}
class Solution{
public:
// using "unordered_map<int, vector<pair<int,int>>>graph" is also equivalent to "vector<vector<pair<int, int >>>graph"
// sometimes you will be given edges in this way -> "vec -> x->y,wt" i.e vector<vector<int>>&vec, then you need to create a graph in this case.
// undirected graph x --> y, wt
// unordered_map<int, vector<pair<int,int>>>g;
// for(auto&x:vec){
// g[x[0]].push_back({x[1], x[2]});
// g[x[1]].push_back({x[0], x[2]});
// }
vector <int> dijkstra(vector<vector<pair<int, int>>> &adj, int src) {
int n = adj.size(); // number of vertices
priority_queue<ppi, vector<ppi>, greater<ppi>> pq; // min heap
vector<int>distTo(n, INT_MAX);
pq.push({0, src}); // dist, node
distTo[src] = 0;
while(!pq.empty())
{
// Always pop node with minimum distance
int dist = pq.top().first;
int node = pq.top().second; // current node
pq.pop();
for(auto &nbr : adj[node]) {
int adjNode = nbr.first;
int edgeWeight = nbr.second;
if (dist + edgeWeight < distTo[adjNode]) {
distTo[adjNode] = dist + edgeWeight;
pq.push({distTo[adjNode], adjNode});
}
}
}
return distTo;
}
};Approach - 2 : Dijkstra using set (Exact Similar to Approach 1) [ C++ Code ]
Set stored everything in ascending order it means we always get the min element at the top.
Time Complexity : O(ElogV)
Space Complexity : O(E) + O(V) { O(E) for set data structure and O(V) for dist array } Where E = Number of edges and V = Number of Nodes.
class Solution{
public:
vector <int> dijkstra(vector<vector<pair<int, int>>> &adj, int src) {
int n = adj.size(); // number of vertices
set<pair<int,int>>st; // {dist, node}
vector<int>distTo(n, INT_MAX);
st.insert({0, src}); // dist, node
distTo[src] = 0;
while(!st.empty())
{
auto it = *(st.begin());
int dist = it.first;
int node = it.second; // current node
st.erase(it);
for(auto &nbr : adj[node]) {
int adjNode = nbr.first;
int edgeWeight = nbr.second;
if(dist + edgeWeight < distTo[adjNode]) {
// earse if it is existed
// it means someone reached this node in past previously, there is no point in keeping
// that pair, e.g {dist, node} = {10, 5}, but now we have found {8, 5}, then remove {10,5}
if(distTo[adjNode] != INT_MAX) {
st.erase({distTo[adjNode], adjNode}); // minor optimization
}
distTo[adjNode] = dist + edgeWeight;
st.insert({distTo[adjNode], adjNode});
}
}
}
return distTo;
}
};Print Shortest Path - Dijkstra's Algorithm [ C++ Code ]
Intuition : Need to store the path in parent array - need to remember from where I am coming from.
Time Complexity : O(ElogV) + O(V), O(ElogV) for normal dijkstra, and O(V) for backtracking and finding the shortest path.
Space Complexity : O(E) + O(V) { for priority queue and dist array } + O(V) { parent array for storing the final path } Where E = Number of edges and V = Number of Nodes.
class Solution {
public:
// Find the shortest weight path between the vertex 1 and the vertex n
vector<int> shortestPath(int n, int m, vector<vector<int>>& edges) {
// undirected graph x --> y, wt
unordered_map<int, vector<pair<int,int>>>g;
for(auto &e : edges){
g[e[0]].push_back({e[1], e[2]});
g[e[1]].push_back({e[0], e[2]});
}
priority_queue<pair<int, int>, vector<pair<int,int>>, greater<pair<int,int>>>pq; // min heap
vector<int>distTo(n+1, INT_MAX), parent(n+1);
for(int i=1;i<=n;i++) parent[i] = i;
int src = 1;
distTo[src] = 0;
pq.push({0, src});
while(!pq.empty())
{
// Always pop node with minimum distance
int dist = pq.top().first;
int node = pq.top().second; // current node
pq.pop();
for(auto &nbr : g[node])
{
int adjNode = nbr.first;
int edgeWeight = nbr.second;
if(dist + edgeWeight < distTo[adjNode]) {
distTo[adjNode] = dist + edgeWeight;
pq.push({distTo[adjNode], adjNode});
parent[adjNode] = node;
}
}
}
// find the shortest path between the vertex 1 and the vertex n and if path does not exist then return a
// list consisting of only -1.
if(distTo[n] == INT_MAX) return {-1}; // if you are not able to reach node 'n', in case of disconnected components.
vector<int>path;
int node = n; // destination node
// it will take O(N)
while(parent[node] != node) {
path.push_back(node);
node = parent[node];
}
path.push_back(src);
// path.push_back(distTo[n]); // return a list of integers whose first element is the weight of the path, and the rest consist of the nodes on that path
reverse(path.begin(), path.end());
return path;
}
};10. Bellman Ford Algorithm
Steps :
(i) Relax all the edges N-1 times using dist[u] + wt < dist[v]
(ii) If dist[u] + wt < dist[v] then set dist[v] = (dist[u] + wt). This process of updating the distance is called the relaxation of edges.
(iii) After relaxing n-1 times, relax for one more time, even if distance again reduced or updated it means there is Negative Weight Cycle, and if it is not updated means "distance" array have possible shortest path.
Bellman Ford's code [ C++ Code ]
Explanation !! And some famous follow up interview questions related to these algorithm.
Q.1 Bellman Vs Dijkstra ?
Ans. Dijkstra Algo will not be able to find the Shortest path when there is Negative Weight edges.
But Bellman Ford works for negative weight edges as well, but make sure there is not any "Negative Weight Cycle"
Q.2 Use of Bellman ford Algorithm ?
Ans. (i) It is used to detect "Negative Weight Cycle" in the Graph.
(ii) It is also used to find the shortest distance between source to destination.
Q.3 Will Bellman Ford works for both "Directed" and "Undirected" graphs ?
Ans. Bellman Ford Works for directed graph, but as a matter of fact any undirected graph is also a directed graph.You just have to specify any edges {u, v} twice (u, v) and (v, u).
But don't forget, that this also means any edge with a negative weight will count as a loop. As the Bellman-Ford algorithm ONLY works on graphs
that don't contain any cycles with negative weights this actually means your un-directed graph mustn't contain any edges with negative weight.
If it doesn't its pretty fine to use Bellmann-Ford.
Bellman Ford Algorithm Does not work on undirected graph with negative weight, because an undirected edge {u, v} with negative weight
can be defined as 2 directed edge, (u, v) and (v, u) with negative weigh, which would be picked up as a negative cycle by Bellman Ford Algorithm.
Therefore, Bellman Ford would only work on "Positively Weighted Undirected" graph.
However in that case, it is preferred to use Dijkstra's algorithm instead as it is asymptotically faster.2 follow-up questions about the algorithm :
-
Why do we need exact N-1 iterations?
Ans : The algorithm will minimize the distance of theithnode in theithiteration likedist[1]will be updated in the1stiteration,dist[2]will be updated in the2nditeration, and so on. So we will need a total of N-1 iterations to minimize all the distances asdist[0]is already set to0. -
How to detect a negative cycle in the graph using bellman ford algorithm ?
Ans :
- We know if we keep on rotating inside a negative cycle, the path weight will be decreased in every iteration. But according to our intuition, we should have minimized all the distances within N-1 iterations(that means, after N-1 iterations no relaxation of edges is possible).
- In order to check the existence of a negative cycle, we will relax the edges one more time after the completion of N-1 iterations. And if in that Nth iteration, it is found that further relaxation of any edge is possible, we can conclude that the graph has a negative cycle. Thus, the Bellman-Ford algorithm detects negative cycles.
Time Complexity : O(VE), where V = no. of vertices and E = no. of Edges.
Space Complexity : O(V) for the distance array which stores the minimized distances.
#include<bits/stdc++.h>
using namespace std;
// Return the length of the shortest path from "src" to "dest". If no path is possible return 10^9
// It is guaranteed that graph does'nt contain any "Negative Weight Cycle" even though we will check for sake of completeness and robustness of the code.
int bellmonFord(int n, int m, int src, int dest, vector<vector<int>> &edges)
{
// node value based on 1-based indexing
vector<int>dist(n+1, INT_MAX);
dist[src] = 0;
// Relax n-1 times
for(int i=1;i<=n-1;i++){
for(auto &e : edges){
int u = e[0], v = e[1], wt = e[2];
if(dist[u]!=INT_MAX and dist[u] + wt < dist[v])
dist[v] = dist[u] + wt;
}
}
// After n-1 times, do relaxation one more time to check "Negative weight Cycle"
int flag=0;
for(auto &e : edges)
{
int u = e[0], v = e[1], wt = e[2];
if(dist[u]!=INT_MAX and dist[u] + wt < dist[v])
{
// cout<<"Negative Weight Cycle";
dist[v] = dist[u] + wt;
flag=1;
break;
}
}
if(!flag){
// shortest distance possible but, we need to check sometimes for INT_MAX
return (dist[dest]==INT_MAX) ? 1e9 : dist[dest];
}
return 1e9; // there is Negative weight Cycle, means shortest distance not possible
}Bellman Ford's code (gfg) [ C++ Code ]
Time Complexity : O(VE), where V = no. of vertices and E = no. of Edges.
Space Complexity : O(V) for the distance array which stores the minimized distances.
class Solution {
public:
vector<int> bellman_ford(int n, vector<vector<int>>& edges, int src) {
// node value based on 0-based indexing
vector<int>dist(n, 1e8);
dist[src] = 0;
// Relax n-1 times
for(int i=1;i<=n-1;i++){
for(auto &e : edges){
int u = e[0], v = e[1], wt = e[2];
if(dist[u] != 1e8 && dist[u] + wt < dist[v])
dist[v] = dist[u] + wt;
}
}
// After n-1 times, do relaxation one more time to check "Negative weight Cycle"
int flag=0;
for(auto &e : edges)
{
int u = e[0], v = e[1], wt = e[2];
if(dist[u] != 1e8 && dist[u] + wt < dist[v])
{
// cout<<"Negative Weight Cycle";
dist[v] = dist[u] + wt;
flag=1;
break;
}
}
if(flag){
return {-1};
}
return dist;
}
};11. Floyd Warshall Algorithm [Multisource shortest path algorithm]
Find shortest path between all the pairs, or the problem is to find shortest distances between every pair of vertices in a given edge weighted directed Graph.
Floyd Warshall code [ C++ Code ]
Practice problem link : https://leetcode.com/problems/find-the-city-with-the-smallest-number-of-neighbors-at-a-threshold-distance/
The intuition is to check all possible paths between every possible pair of nodes and to choose the shortest one. Checking all possible paths means going via each and every possible node.
we can derive the following formula :
matrix[i][j] = min(matrix[i][j], matrix[i][k]+matrix[k][j]), where i = source node, j = destination node, and k = the node via which we are reaching from i to j.
Dijkstra vs Bellman Ford vs Floyd Warshall :
-
Dijkstra's Shortest Path algorithm and Bellman-Ford algorithm are single-source shortest path algorithms where we are given a single source node and are asked to find out the shortest path to every other node from that given source. But in the Floyd Warshall algorithm, we need to figure out the shortest distance from each node to every other node.
-
Floyd Warshall algorithm is a multi-source shortest path algorithm and it helps to detect negative cycles as well. The shortest path between node
uandvnecessarily means the path(from u to v) for which the sum of the edge weights is minimum.
2 follow-up questions for interviews :
- How to detect a negative cycle using the Floyd Warshall algorithm?
Ans : If we find that the cost of reaching a node from itself is less than0, we can conclude that the graph has a negative cycle. we will run a loop and check if any cell having the row and column the same(i = j)contains a value less than0. - What will happen if we will apply Dijkstra’s algorithm for this purpose?
Ans :
case 1 : If the graph has a negative cycle : We cannot apply Dijkstra’s algorithm to the graph which contains a negative cycle. It will give TLE error in that case.
case 2 : If the graph does not contain a negative cycle : In this case, we will apply Dijkstra’s algorithm for every possible node to make it work like a multi-source shortest path algorithm like Floyd Warshall. The time complexity of Floyd Warshall is O(V3) whereas if we apply Dijkstra’s algorithm for the same purpose the time complexity reduces to O(V(ElogV)) (where V = no. of vertices).
Time Complexity : O(V3), as we have three nested loops each running for V times, where V = no. of vertices.
Space Complexity : O(V2), where V = no. of vertices. This space complexity is due to storing the adjacency matrix of the given graph.
#include<bits/stdc++.h>
using namespace std;
int floydWarshall(int n, int m, int src, int dest, vector<vector<int>> &edges)
{
// node value based on 1-based indexing
// used to find all pair shortest path so create dist array of nxn
vector<vector<int>>dist(n+1, vector<int>(n+1, INT_MAX));
for(auto &e : edges){
int u=e[0],v=e[1],wt=e[2];
dist[u][v] = wt;
}
// diagonal elements
int i = 1;
while(i <= n){
dist[i][i] = 0; // cost of reaching a node from itself must always be 0
i++;
}
// make all pair and find shortest path between them
for(int k=1;k<=n;k++){
for(int i=1;i<=n;i++){
for(int j=1;j<=n;j++){
if(dist[i][k]==INT_MAX or dist[k][j]==INT_MAX) continue;
if(dist[i][k] + dist[k][j] < dist[i][j])
dist[i][j] = dist[i][k] + dist[k][j];
// Also write in this way
// dist[i][j] = min(dist[i][j], dist[i][k] + dist[k][j]);
}
}
}
return (dist[src][dest] == INT_MAX) ? 1e9 : dist[src][dest];
}Floyd Warshall code (when we already have a cost matrix) [ C++ Code ]
Time Complexity : O(V3), as we have three nested loops each running for V times, where V = no. of vertices.
Space Complexity : O(V2), where V = no. of vertices. This space complexity is due to storing the adjacency matrix of the given graph.
class Solution {
public:
void shortestDistance(vector<vector<int>>& mat) {
int n = mat.size(); // cost matrix for the distance
for(int i=0;i<n;i++) {
for(int j=0;j<n;j++) {
if(mat[i][j] == -1) // -1 there is no edge from i to j, assign it to max value as infinity.
mat[i][j] = 1e9;
if(i == j) // if it is diagonal
mat[i][j] = 0; // distance from node to node is zero, or cost of reaching a node from itself must always be 0
}
}
for(int k=0;k<n;k++) {
for(int i=0;i<n;i++) {
for(int j=0;j<n;j++) {
mat[i][j] = min(mat[i][j], mat[i][k] + mat[k][j]);
}
}
}
// If we want to check for a negative cycle in the graph :
// for(int i=0;i<n;i++) {
// if(mat[i][i] < 0) {
// cout<< "Yes, Negative cycle exist"<<endl;
// }
// }
// revert back to previous state of the matrix as suggested in question
for(int i=0;i<n;i++) {
for(int j=0;j<n;j++) {
if(mat[i][j] == 1e9)
mat[i][j] = -1;
}
}
}
};12. MST using Prim's Algorithm : A tree in which we have N nodes and N-1 edges, all nodes are reachable from each other, known as Spanning tree. A single graph can have multiple spanning trees are possible but a tree with a minimum sum of edges known as minimum spanning tree.
Prim's Algorithm code [ C++ Code ]


Note : Prim's algo will provide us
- minimum sum of weights of edges.
- Edges involved in minimum spanning tree.
Intuition:
The intuition of this algorithm is the greedy technique used for every node. If we carefully observe, for every node, we are greedily selecting its unvisited adjacent node with the minimum edge weight(as the priority queue here is a min-heap and the topmost element is the node with the minimum edge weight). Doing so for every node, we can get the sum of all the edge weights of the minimum spanning tree and the spanning tree itself(if we wish to) as well.
Time Complexity : O(E*logE), where E is the number of edges.
- The maximum size of the priority queue is E, so at most E iterations are required to empty it. Each pop operation takes
logEtime, resulting inO(ElogE). - For each node, traversing its adjacent edges (at most E) involves a push operation for unvisited nodes, each taking
logE. This adds anotherO(ElogE). Overall:O(ElogE) + O(ElogE)=O(ElogE).
Space Complexity : O(E) + O(V) + O(V-1)
O(E)for the priority queue.O(V)for the visited array.- An additional
O(V-1)for storing the edges of the MST.
class Solution {
public:
int spanningTree(int V, vector<vector<int>> adj[]) {
vector<pair<int, int>>mstEdges; // If we wish to store the minimum spanning tree(MST) of the graph, we need this array. This will store the edge information as a pair of starting and ending nodes of a particular edge.
vector<int>vis(V, 0);
priority_queue<vector<int>, vector<vector<int>>, greater<vector<int>>>pq; // [edW, node, parent]
int sum = 0;
// Note: We can start from any node of our choice. Here we have chosen node 0.
pq.push({0,0,-1}); // we can start with any starting node (e.g 0) initially - (wt, node, parent)
while(!pq.empty()) {
auto p = pq.top();
pq.pop();
int wt = p[0];
int node = p[1];
int parentNode = p[2];
if (vis[node] == 1) continue;
vis[node] = 1;
sum += wt;
mstEdges.push_back({parentNode, node});
for(auto &adjNode: adj[node]) {
int nbr = adjNode[0];
int edW = adjNode[1];
if(!vis[nbr]) {
pq.push({edW, nbr, node});
}
}
}
// parent of 0th node is not exist so start from 1
// for(int i=1;i<mstEdges.size();i++){
// cout<<"("<<mstEdges[i].first<<","<<mstEdges[i].second<<")"<<endl;
// }
return sum;
}
};
int main() {
int V = 5;
vector<vector<int>> edges = {{0, 1, 2}, {0, 2, 1}, {1, 2, 1}, {2, 3, 2}, {3, 4, 1}, {4, 2, 2}};
vector<vector<int>> adj[V];
for (auto it : edges) {
vector<int> tmp(2);
tmp[0] = it[1];
tmp[1] = it[2];
adj[it[0]].push_back(tmp);
tmp[0] = it[0];
tmp[1] = it[2];
adj[it[1]].push_back(tmp);
}
Solution obj;
int sum = obj.spanningTree(V, adj);
cout << "The sum of all the edge weights: " << sum << endl;
return 0;
}13. Disjoint Set Union
Path Compression : Optimization done by Path compression in findUPar() function. update parent of all descendents while recursion, this will save our time when I need to find the parent of same node again.
Concepts of DSU
Functionalities of Disjoint Set data structure :
The disjoint set data structure generally provides two types of functionalities :
- Finding the parent for a particular node (
findUPar()) - This function actually takes a single node as an argument and finds the ultimate parent for each node. - Union (in broad terms this method basically adds an edge between two nodes)
Union by rank
Union by size
(a) Union by rank
The rank of a node is the maximum number of nodes from the current node to its farthest leaf, including itself.
- rank array - The rank array basically stores the rank of each node, this array is initialized with zero.
- parent array - the parent array stores the ultimate parent for each node, the array is initialized with the value of nodes i.e.
parent[i] = i.
Observation 1 : why we need to find the ultimate parents ?.
Only the ultimate parent can confirm whether two nodes belong to the same component.
So, here comes the findUPar() function which will help us to find the ultimate parent for a particular node.
Observation 2 : Now, if we try to find the ultimate parent (typically using recursion) of each query separately, it will end up taking O(logN) time complexity for each case. But we want the operation to be done in a constant time. This is where the path compression technique comes in.
Using the path compression technique we can reduce the time complexity nearly to constant time.
Path compression technique : Connecting each node in a particular path to its ultimate parent is known as path compression.
How path compression reduces the time complexity :
- Before path compression, finding the ultimate parent required traversing up to logN nodes.
- Path compression reduces traversal to almost one step by directly linking nodes to their ultimate parent, improving time complexity.
- We cannot change the ranks while applying path compression. Ranks remain unchanged during path compression to maintain consistency.
Follow - up Question : In the union by rank method, why do we need to connect the smaller rank to the larger rank?
Ans : we should always connect a smaller rank to a larger one with the goal of
- shrinking the height of the graph.
- reducing the time complexity as much as we can.
(b) Union by size
Observation 3 : Now, if we again carefully observe, after applying path compression the rank of the graphs becomes distorted. So, rather than storing the rank, we can just store the size of the components for comparing which component is greater or smaller. So, here comes the concept of Union by size.
This is as same as the Union by rank method except this method uses the size to compare the components while connecting. That is why we need a size array of size N (no. of nodes) instead of a rank array. The size array will be storing the size for each particular node i.e. size[i] will be the size of the component starting from node i.
Typically, the size of a node refers to the number of nodes that are connected to it.
- size array: This array is initialized with
1. - parent array: The array is initialized with the value of nodes i.e.
parent[i] = i.
Note : It seems much more intuitive than union by rank as the rank gets distorted after path compression.
(1) Disjoint Set Union by Rank [ C++ Code ]
Easy practice question on DSU : https://leetcode.com/problems/redundant-connection/description/

Time Complexity : O(4) which is very small and close to 1. So, we can consider 4 as a constant.
Space Complexity : O(N) + O(N), O(N) for rank array and O(N) for parent array.
#include <bits/stdc++.h>
using namespace std;
class DisjointSet {
vector<int> rank, parent;
public:
DisjointSet(int n) {
rank.resize(n + 1, 0);
parent.resize(n + 1);
for (int i = 0; i <= n; i++) {
parent[i] = i;
}
}
int findUPar(int node) {
if (node == parent[node])
return node;
return parent[node] = findUPar(parent[node]);
}
void unionByRank(int u, int v) {
int ulp_u = findUPar(u);
int ulp_v = findUPar(v);
if (ulp_u == ulp_v) return;
if (rank[ulp_u] < rank[ulp_v]) {
parent[ulp_u] = ulp_v;
}
else if (rank[ulp_v] < rank[ulp_u]) {
parent[ulp_v] = ulp_u;
}
else {
parent[ulp_v] = ulp_u;
rank[ulp_u]++;
}
}
};
int main() {
DisjointSet ds(7);
ds.unionByRank(1, 2);
ds.unionByRank(2, 3);
ds.unionByRank(4, 5);
ds.unionByRank(6, 7);
ds.unionByRank(5, 6);
// if 3 and 7 same or not (check if 2 nodes are belong to the same component or not)
if (ds.findUPar(3) == ds.findUPar(7)) {
cout << "Same\n";
}
else cout << "Not same\n";
ds.unionByRank(3, 7);
if (ds.findUPar(3) == ds.findUPar(7)) {
cout << "Same\n";
}
else cout << "Not same\n";
return 0;
}(2) Disjoint Set Union by Size [ C++ Code ]
Time Complexity : O(4) which is very small and close to 1. So, we can consider 4 as a constant.
Space Complexity : O(N) + O(N), O(N) for rank array and O(N) for parent array.
#include <bits/stdc++.h>
using namespace std;
class DisjointSet {
vector<int> rank, parent, size;
public:
DisjointSet(int n) {
rank.resize(n + 1, 0);
parent.resize(n + 1);
size.resize(n + 1);
for (int i = 0; i <= n; i++) {
parent[i] = i;
size[i] = 1;
}
}
int findUPar(int node) {
if (node == parent[node])
return node;
return parent[node] = findUPar(parent[node]);
}
void unionByRank(int u, int v) {
int ulp_u = findUPar(u);
int ulp_v = findUPar(v);
if (ulp_u == ulp_v) return;
if (rank[ulp_u] < rank[ulp_v]) {
parent[ulp_u] = ulp_v;
}
else if (rank[ulp_v] < rank[ulp_u]) {
parent[ulp_v] = ulp_u;
}
else {
parent[ulp_v] = ulp_u;
rank[ulp_u]++;
}
}
void unionBySize(int u, int v) {
int ulp_u = findUPar(u);
int ulp_v = findUPar(v);
if (ulp_u == ulp_v) return;
if (size[ulp_u] < size[ulp_v]) {
parent[ulp_u] = ulp_v;
size[ulp_v] += size[ulp_u];
}
else {
parent[ulp_v] = ulp_u;
size[ulp_u] += size[ulp_v];
}
}
};
int main() {
DisjointSet ds(7);
ds.unionBySize(1, 2);
ds.unionBySize(2, 3);
ds.unionBySize(4, 5);
ds.unionBySize(6, 7);
ds.unionBySize(5, 6);
// if 3 and 7 same or not
if (ds.findUPar(3) == ds.findUPar(7)) {
cout << "Same\n";
}
else cout << "Not same\n";
ds.unionBySize(3, 7);
if (ds.findUPar(3) == ds.findUPar(7)) {
cout << "Same\n";
}
else cout << "Not same\n";
return 0;
}14. MST using Kruskal's Algorithm
Pre-requisite : Disjoint set (DSU by rank/size)
Kruskal's Algorithm code [ C++ Code ]
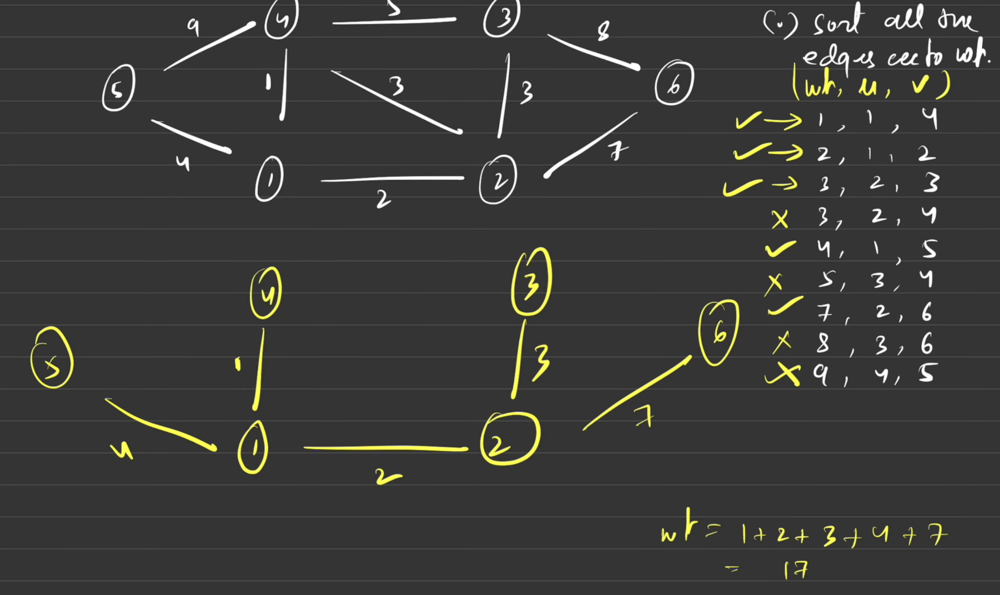
Approach :
We know Disjoint Set provides two methods named :
- findUPar() : This function helps to find the ultimate parent of a particular node.
- Union : This basically helps to add the edges between two nodes.
Short Steps :
- The array must be sorted in the ascending order of the weights so that while iterating we can get the edges with the minimum weights first.
- For each edge, check if the nodes
uandvbelong to different sets using thefindUPar()function of the Disjoint Set. - If they belong to the same set, skip the edge (as a path already exists).
- If they are in different sets, add the edge's weight to the MST weight and perform a union operation (
unionBySizeorunionByRank). so we have to include that edge betweenuandvalso, which leads touwill be reachable byvandvwill be reachable byu.
Time Complexity : O(N + E) + O(E logE) + O(E)
O(N + E): Extracting edge information from the adjacency list.O(E logE): Sorting the edge list.O(E): For E iterations, each disjoint set operation (find and union) takes O(α), so O(E * 4 * 2).
Space Complexity : O(E) + O(N)
O(E): For storing edge information.O(N) + O(N): For the parent and size arrays in the disjoint set.
Note : Points to remember if the graph is given as an adjacency list we must extract the edge information first. As the graph contains bidirectional edges we can get a single edge twice in our array (For example, (wt, u, v) and (wt, v, u), (5, 1, 2) and (5, 2, 1)). But we should not worry about that as the Disjoint Set data structure will automatically discard the duplicate one.
class DisjointSet {
vector<int> rank, parent, size;
public:
DisjointSet(int n) {
rank.resize(n + 1, 0);
parent.resize(n + 1);
size.resize(n + 1);
for (int i = 0; i <= n; i++) {
parent[i] = i;
size[i] = 1;
}
}
int findUPar(int node) {
if (node == parent[node])
return node;
return parent[node] = findUPar(parent[node]);
}
void unionByRank(int u, int v) {
int ulp_u = findUPar(u);
int ulp_v = findUPar(v);
if (ulp_u == ulp_v) return;
if (rank[ulp_u] < rank[ulp_v]) {
parent[ulp_u] = ulp_v;
}
else if (rank[ulp_v] < rank[ulp_u]) {
parent[ulp_v] = ulp_u;
}
else {
parent[ulp_v] = ulp_u;
rank[ulp_u]++;
}
}
void unionBySize(int u, int v) {
int ulp_u = findUPar(u);
int ulp_v = findUPar(v);
if (ulp_u == ulp_v) return;
if (size[ulp_u] < size[ulp_v]) {
parent[ulp_u] = ulp_v;
size[ulp_v] += size[ulp_u];
}
else {
parent[ulp_v] = ulp_u;
size[ulp_u] += size[ulp_v];
}
}
};
class Solution {
public:
int spanningTree(int V, vector<vector<int>> adj[]) {
// 1 - 2 wt = 5
/// 1 - > (2, 5)
// 2 -> (1, 5)
// 5, 1, 2
// 5, 2, 1
vector<pair<int, int>>mstEdges;
vector<pair<int, pair<int, int>>> edges;
for (int i = 0; i < V; i++) {
for (auto it : adj[i]) {
int adjNode = it[0];
int wt = it[1];
int node = i;
edges.push_back({wt, {node, adjNode}});
}
}
DisjointSet ds(V);
sort(edges.begin(), edges.end());
int mstWt = 0;
for (auto it : edges) {
int wt = it.first;
int u = it.second.first;
int v = it.second.second;
if (ds.findUPar(u) != ds.findUPar(v)) {
mstWt += wt;
mstEdges.push_back({u, v});
ds.unionBySize(u, v);
}
}
// start from 0th index, take all edges.
// for(int i=0;i<mstEdges.size();i++){
// cout<<"("<<mstEdges[i].first<<","<<mstEdges[i].second<<")"<<endl;
// }
return mstWt;
}
};
int main() {
int V = 5;
vector<vector<int>> edges = {{0, 1, 2}, {0, 2, 1}, {1, 2, 1}, {2, 3, 2}, {3, 4, 1}, {4, 2, 2}};
vector<vector<int>> adj[V];
for (auto it : edges) {
vector<int> tmp(2);
tmp[0] = it[1];
tmp[1] = it[2];
adj[it[0]].push_back(tmp);
tmp[0] = it[0];
tmp[1] = it[2];
adj[it[1]].push_back(tmp);
}
Solution obj;
int mstWt = obj.spanningTree(V, adj);
cout << "The sum of all the edge weights: " << mstWt << endl;
return 0;
}15. Tarjan's Algorithm For SCC/Bridges in a graph/Articulation Point
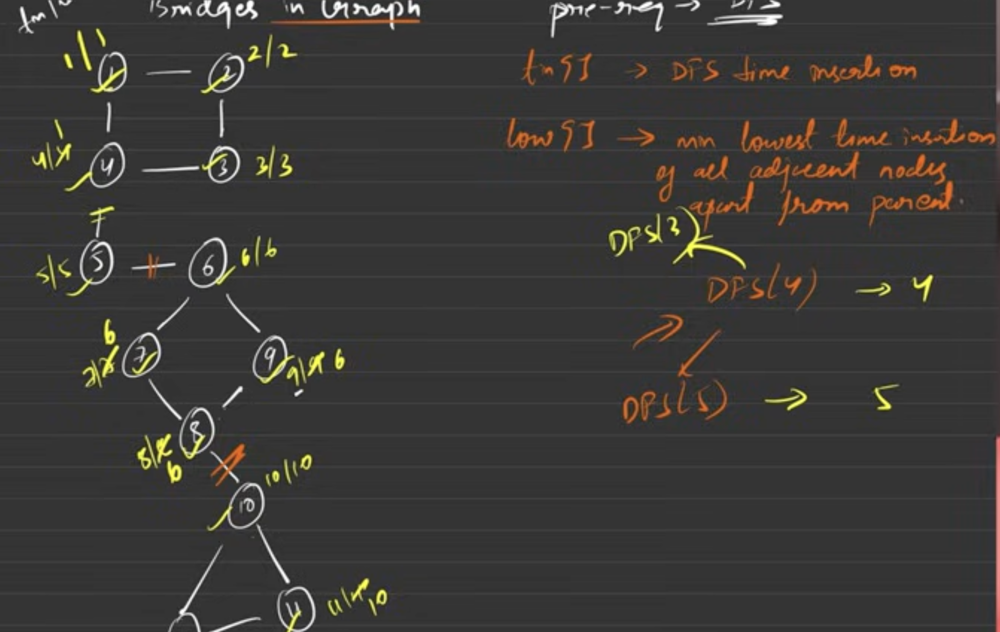
1) Bridges in Graph : Any Edge in a graph on whose removal the graph will broken down into 2 or more components it means that edge is a Bridge (Also known as critical/weak connections of a graph).
Problem : Print all the bridges in the graph.
Practice problem link : https://leetcode.com/problems/critical-connections-in-a-network/description/
Code [ C++ Code ]
Note :
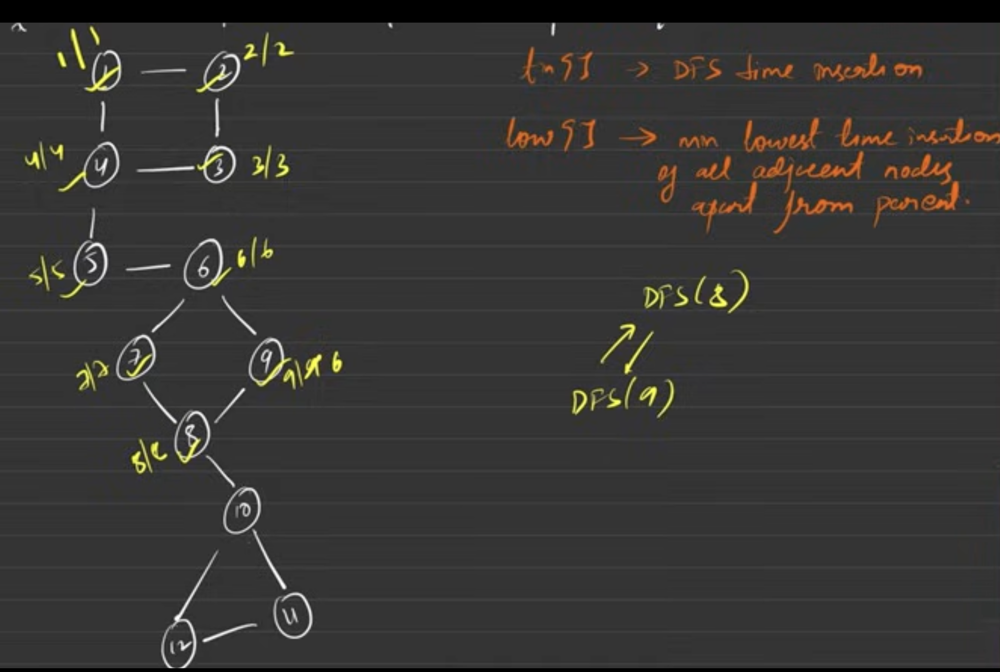
tin[]- time or step at which we reached the node is called as time of insertion. [DFS time insertion]low[]- minimum of lowest time of insertion of all adjacent nodes except parent. (intuition for why except parent, because if there is any way through which I get to the parent node it means that between edge is not a bridge.
Time Complexity : O(V + 2E) + O(3V)
Space Complexity : O(V+2E) ~ O(V+E)
class Solution {
public:
// Tarjan's Algo is used to find the bridges in a graph
void dfs(int node, int parent, vector<int>& tin, vector<int>& low, vector<int>& vis, vector<int> g[], vector<vector<int>>& bridges, int& timer) {
vis[node] = 1;
tin[node] = low[node] = timer; // when we visite node first time, current time and lowest time of insertion is equal
timer++; // increase the timer for the next step
for (auto nbr : g[node]) {
if (nbr == parent) continue; // except parent
// if node is not visited, call the dfs function
if (!vis[nbr]) {
dfs(nbr, node, tin, low, vis, g, bridges, timer);
// when it came back after finishing the dfs call
low[node] = min(low[node], low[nbr]);
// can this (node -> nbr) a bridge - check for bridge
if (low[nbr] > tin[node]) {
bridges.push_back({node, nbr});
}
}
else {
// if nbr is already visited, it cannot be a bridge but hey! nbr lets give me your lowest time
low[node] = min(low[node], tin[nbr]);
}
}
}
// SC - O(V + 2E) + O(3V)
// TC - O(V+2E) ~ O(V+E)
vector<vector<int>> criticalConnections(int n, vector<vector<int>>& connections) {
vector<int> g[n]; // stores connections in the form of graph
for (auto& it : connections) {
g[it[0]].push_back(it[1]);
g[it[1]].push_back(it[0]);
}
vector<int> vis(n, 0); // vis array used to mark the node
vector<int> tin(n, -1); // DFS time insertion of node
vector<int> low(n, -1); // lowest time out of all adjacent nodes except parent.
int timer = 1;
vector<vector<int>>bridges;
// call dfs function, single call because there is only one graph component.
dfs(0, -1, tin, low, vis, g, bridges, timer);
return bridges;
}
};2) Articulation Point/vertex in a graph : Any vertex in a graph on whose removal the graph will broken down into 2 or more components it means that vertex is a Articulation point/vertex (Also known as critical/weak vertex of a graph).
Problem : Print all the articulation points in the graph.
Practice problem link : pls solve it on gfg.
Code [ C++ Code ]
Note :
tin[]- time or step at which we reached the node is called as time of insertion. [time of insertion during DFS]low[]- minimum of lowest time of insertion of all adjacent nodes except parent & visited nodes.
Time Complexity : O(V+2E) + O(4V)
Space Complexity : O(V+E)
class Solution {
public:
int timer = 1;
void dfs(int node, int parent, vector<int> &vis, vector<int>&tin, vector<int>&low, vector<int> &mark, vector<int>adj[]) {
vis[node] = 1;
tin[node] = low[node] = timer;
timer++;
int child = 0;
for (auto it : adj[node]) {
if (it == parent) continue;
if (!vis[it]) {
dfs(it, node, vis, tin, low, mark, adj);
low[node] = min(low[node], low[it]);
if (low[it] >= tin[node] && parent != -1) { //
mark[node] = 1;
}
child++;
}
else {
low[node] = min(low[node], tin[it]);
}
}
if (child > 1 && parent == -1) { // when we remove start node and it has multiple childs, then it is
// definetely an articulation point.
mark[node] = 1;
}
}
vector<int> articulationPoints(int V, vector<int>adj[]) {
vector<int>vis(V,0);
// To avoid the storing of duplicate articulation nodes, we will store the nodes in a hash array(i.e. mark array used in the code) instead of directly inserting them in a simple array.
vector<int> mark(V, 0);
vector<int>tin(V,-1);
vector<int>low(V,-1);
// Run for all the components
for(int i=0;i<V;i++) {
if(!vis[i]) {
dfs(i, -1, vis, tin, low, mark, adj);
}
}
vector<int> ans; // articulation vertices
for (int i = 0; i < V; i++) {
if (mark[i] == 1) {
ans.push_back(i);
}
}
if (ans.size() == 0) return {-1};
return ans;
}
};Thanks for Upvoting !
🙂 Feel free to comment and suggest any improvements !! ✅