

My Other Article on Algorithmic techniques:
Line Sweep Algorithms | Solving kth kind of problems
Binary Index Tree Template and Problem Solving
BFS and its variations | Binary Lifting Technique
Where this technique applies:
In some class of problem, we are required to return k-th ancestor of a node in a tree multiple times for different nodes or LCA(Lowest Common Ancestor) we have compute repeatedly.
First we understand some building blocks.
Distance between two nodes in a tree
Consider this tree, suppose we are asked to find the distance between node 8 & 9, how do we find that ?
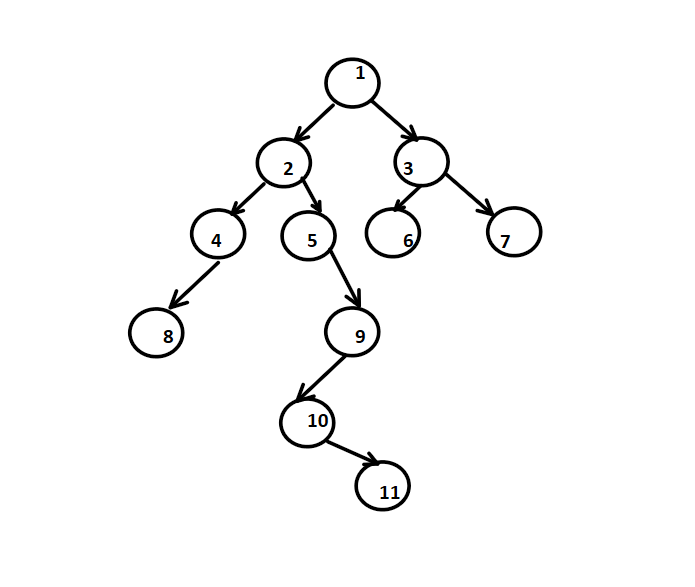
We can see that the distance is 4, But how to find this algorithimically?
LCA comes to help here
We can reach 9 from 8 via 8>4>2>5>9 which can be re-arranged and written as 1->2>4>8 + 1->2>5->9 and subtracting 1-2 (twice as this is not required)
More generically we can write as
distance (u, v) = depth[u] + depth[v] - 2 * depth [LCA(u,v)]
Kth Ancestor of a node
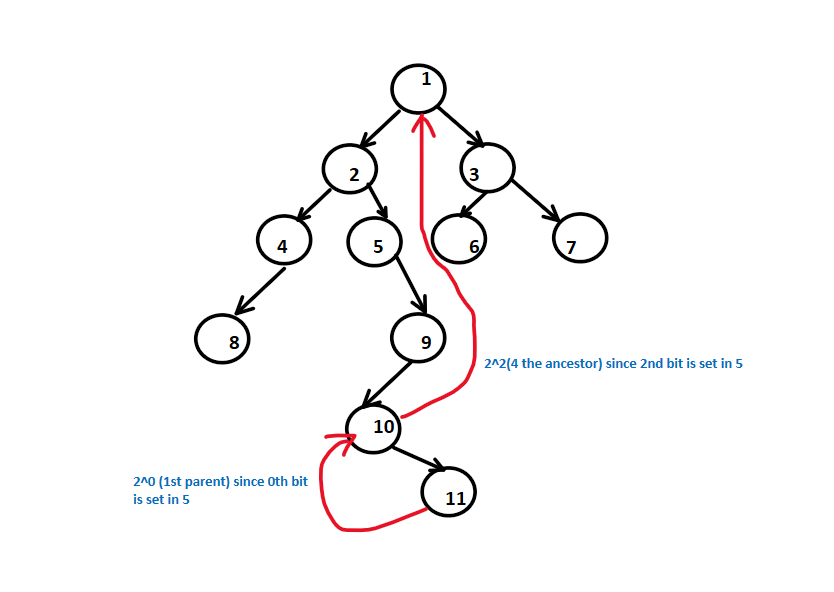
Any number can be written in form of binary representation for example 5 is 101, now consider a tree like below and we are asked to kind 5th ancestor of node 11 , which is 1
To locate this, we check if a bit is set in the number and leap accordingly. The jump magnitude corresponds to 2^i, aligned with the position of the set bit. This strategy involves precomputing the 2^i parent for each node, which proves instrumental in efficiently responding to subsequent queries. See this image to understand more clearly , how the below code works
How to calculate this precomputed array kthParent , we will see soon.
| Code | Description |
|---|---|
|
|
Now let's see how do we compute these building block i.e. depth , parent and kthParent for each node and then how to use these to find LCA for a given pair of node.
depth and parent can be found by performing DFS on the given tree.
Now to find kthParent for each node i.e. for each node we have to find [0,1,2,3..maxDepth] parent which would be [1, 2, 4, 8, 16] parent for each node.
1st parent for each node from DFS traversal which is there immediate parent.
We can use this information to iteratively find higher power parents of each node. This image for computing 2^1 parent(2nd parent) of node 11. As see this can be computed using previous node 2^0 parent.

So we can say
kthParent[j][i] = kthParent[ kthParent[j][i-1] ] [i-1];
Overall code would be , here maxD is maximum depth of tree, we can use 32 as well , based on given problem
for(int i = 0; i < maxD; ++i){
for(int j =0; j < n ; ++j){
if(!i) // immediate parent , this we know from DFS
kthParent[j][i] = parent[j];
else if(depth[j][i-1]!=-1) // just check if we arent suprassing
kthParent[j][i] = kthParent[depth[j][i-1]][i-1];
}
}
}Next lets see how to find LCA when we have pre-computed all these auxillary data structures.
LCA (u, v)
Steps :
1. First bring both the node to same depth level.
2. There could be a case where both u and v are same after Step 1, so check and return parent[u] .
3. If Step 2 is not the case then either iterativel or binary search find the last node, where both there parent are different.
4. return parent[u] // this we know from DFS
Let's see this with an example, suppose we have to find LCA (8, 11)
depth[8] = 3 , depth[11] =5 , so we have move node 11 2 level up ( 5 - 3), to do this we can use getKthParent subroutine described above.
Now we have LCA(8, 9)
Step 2 wont hit as both are different node,
Now we try to find out last node where there parent are not same and stop there.
For example 1st parent of kthParent [8][1] and kthParent [9][1] are same parent, every thing beyong 1 would also be same , so we have find lesser than 1. Finally we stop at 0, now our u and v are 4,5 repectively and we can return parent of any of it as that is the LCA of (8, 11)
There wont be much difference in run time of both approach.
| Iteratively | Binary Search |
|---|---|
|
|
Overall LCA code would look like this:
int getLCA(int u, int v){
if(depth[u] > depth[v])
swap(u, v);
int diff = depth[v] - depth[u];
v = getKth(v , diff) ; // v is on deeper ;evel, so we need to lift it up
if(u==v) // case where both node are originally in same subtree
return u;
for(int i = maxD; i>=0 ; --i){
int newU = kthParent[u][i];
int newV = kthParent[v][i];
if(newU==newV) // that means we are yet to find something not common,
continue;
u = newU;
v = newV;
}
// now here we have explored all the depth and now u and v parent is LCA
return parent[u];
}Problems:
1483. Kth Ancestor of a Tree Node
In this porblem we are given number of nodes n and parent array, so here we dont have to do DFS to calculate this. Moreover this problem doesnt asks for Lowest Common Ancestor , so need to calculate depth array as well. We just calculate kthParent array for each node by making using of parent array and answer queries.
class TreeAncestor {
vector<vector<int>> kthParent;
int maxD =0;
public:
TreeAncestor(int n, vector<int>& parent) {
// Max depth for n node would be LOGN
while ( (1<< maxD) <=n)
maxD++;
kthParent.resize(n, vector<int>(maxD, -1));
for(int i = 0; i < maxD; ++i){
for(int j =0; j < n ; ++j){
if(!i) // 2^0 means immediate parent, this we know as input
depth[j][i] = parent[j];
else if(kthParent[j][i-1]!=-1)
kthParent[j][i] = kthParent[kthParent[j][i-1]][i-1];
}
}
}
int getKthAncestor(int node, int k) {
for(int i = 0; i < maxD; ++i){
if( (1<<i) & k ){
node = kthParent[node][i];
if(node==-1)
break;
}
}
return node;
}
};
/**
* Your TreeAncestor object will be instantiated and called as such:
* TreeAncestor* obj = new TreeAncestor(n, parent);
* int param_1 = obj->getKthAncestor(node,k);
*/2836. Maximize Value of Function in a Ball Passing Game
Same as earlier problem, we are given parent and a value k which can go as large as 10^10 but on log scale can be maximum 35 as log (10^10) ~ 35
An extra thing here is with kthParent we also maintain sum for that kthParent , whenever we calculate kThParent , at that same time also calculate sum
Once we have this data computed, we can walk k times for each, this walk isnt costly as we will use logarithmic scale i.e. k can be written as sum of power of 2 and we jump those ancestor in our tree and also accumualte sum in a long long variable.
class Solution {
public:
long long getMaxFunctionValue(vector<int>& receiver, long long k) {
// Any number can be formed using 2-powers
// here k is 10^10 , taking its log would be 35 , so maximum 2^35 if k is 10^10
int maxD = 35;
int n = receiver.size();
vector<vector<int>> kthParent(n, vector<int>(maxD));
vector<vector<long long>> cost(n, vector<long long>(maxD, 0));
for(int i =0; i < maxD; ++i){
for(int j =0; j < n ; ++j){
if(!i){
kthParent[j][i] = receiver[j];
cost[j][i] = receiver[j];
}
else{
kthParent[j][i] = kthParent[kthParent[j][i-1]][i-1];
cost[j][i] = cost[j][i-1] + cost[kthParent[j][i-1]][i-1]; // accumulate sum
}
}
}
long long ans = 0;
for(int i =0; i < n ; ++i){
long long sum = i;
int node = i;
for(long long j =0; j < maxD; ++j){
if( (1LL << j) & k){
sum += cost[node][j]; // use node not i because now the ith node is moved up because bit is set
node = kthParent[node][j];
}
}
ans = max(ans, sum);
}
return ans;
}
};2846. Minimum Edge Weight Equilibrium Queries in a Tree
Lets solve a simpler problem first: We are given an array and we have to return minium operation required to make all elements equal [2, 2, 2, 3, 4]
Answer is 2 , just convert 3 and 4 to 2 as 2 is most frequent element.
Anything else will incur more number of operations.
So what we have done is length of array - count of most frequent element
In this problem we have to do same i.e. maintain frequency of weight at each node. This weight can be maximum 26
Second part of the problem , we need to calculate the something similar to length of array, so how do we know length between any given pair of node. This I have explained at begining of article. So here we need to find the LCA
So for each query for nodes (u, v)
- Calculate LCA and using that calculate length of path between (u, v)
- Find out most frequent weight between (u,v) by iterating all 1 to 26 weight
- Answer would be
length - frequency of weight
class Solution {
vector<vector<pair<int, int>>> adj;
vector<int> depth;
vector<vector<int>> kthParent;
vector<unordered_map<int, int>> freq; // for each node, we will have frequency
vector<int> parent;
int maxD = 0;
void dfs(int node, int p, int d){
parent[node] = p;
for(auto& [nei, val] : adj[node]){
if(nei!= p){
depth[nei] = d + 1;
freq[nei] = freq[node];
freq[nei][val]++;
dfs(nei, node, d + 1);
}
}
}
int getKth(int u, int k){
for(int i =0; i < maxD; ++i){
if( (1<<i) & k)
u = kthParent[u][i];
}
return u;
}
int getLCA(int u, int v){
if(depth[u] > depth[v])
swap(u, v);
int diff = depth[v] - depth[u];
v = getKth(v , diff) ; // v is on deeper ;evel, so we need to lift it up
if(u==v) // case where both node are originally in same subtree
return u;
for(int i = maxD; i>=0 ; --i){
int newU = kthParent[u][i];
int newV = kthParent[v][i];
if(newU==newV) // that means we are yet to find something not common,
continue;
u = newU;
v = newV;
}
// now here we have explored all the depth and now u and v parent is LCA
return parent[u];
}
public:
vector<int> minOperationsQueries(int n, vector<vector<int>>& edges, vector<vector<int>>& queries) {
adj.resize(n);
depth.resize(n);
freq.resize(n);
parent.resize(n);
while ( (1 << maxD) <=n ){
++maxD;
}
depth[0] = 0;
kthParent.resize(n, vector<int>(maxD+1));
for(auto& e : edges){
adj[e[0]].push_back({e[1], e[2]});
adj[e[1]].push_back({e[0], e[2]});
}
dfs(0, -1, 0);
for(int i =0 ; i < maxD; ++i){
for(int j =0; j < n ; ++j){
if(!i)
kthParent[j][i] = parent[j];
else if(LCA[j][i-1]!=-1)
kthParent[j][i] = kthParent[kthParent[j][i-1]][i-1];
}
}
vector<int> ans;
for(int i =0; i < queries.size(); ++i){
int l = getLCA(queries[i][0], queries[i][1]);
int length = depth[queries[i][0]] + depth[queries[i][1]] - (2 * depth[l]);
int maxE = 0;
for(int j =0; j < 27; ++j){
int curr = freq[queries[i][0]][j] + freq[queries[i][1]][j] - (2 * freq[l][j]);
maxE = max(maxE, curr);
}
ans.push_back(length - maxE);
}
return ans;
}
};2509. Cycle Length Queries in a Tree
This is an interesting Hard problem, where the tree is complete binary tree and it can have 2^32 nodes , so if we go and store those depth or parent or even kthParent array , we would get MLE
Since this is a complete binary tree and nodes are number from 1 , we can calculate these information on the fly.
depth : log(u)
parent : u / 2
kthAncestor : u >> k
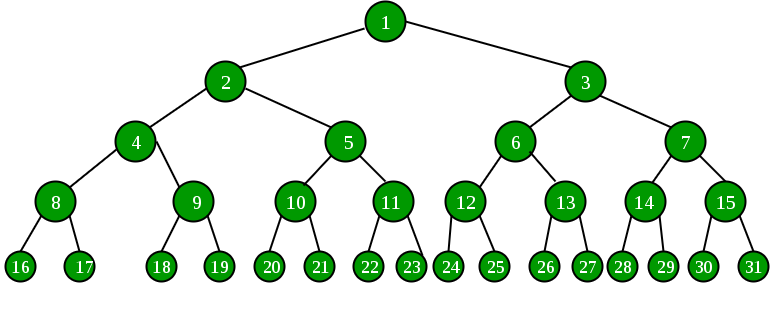
Check this compete binary tree picture and lets find out for u=19
depth = log (19) ~ 4
parent = 19 / 2 = 9
suppose we want to find 3rd ancestor of 19 19 >> 3 which is 2 and thats correct as can be seen in image.
class Solution {
int getK(int u, int k){
u = u >> k;
return u;
}
int depth(int u){
return (int)log2(u);
}
int getLCA(int u, int v){
if(depth(u) > depth(v))
swap(u, v);
int diff = depth(v) -depth(u);
v = getK(v, diff);
if(u==v)
return u;
int l = 0;
int r = 31;
while( l < r){
int mid = (l + r + 1) /2;
int newU = u >> mid;
int newV = v >> mid;
if(newU==newV){
r = mid -1;
}
else{
l = mid;
}
}
u = u >> l;
return u >> 1; // parent of u
}
public:
vector<int> cycleLengthQueries(int n, vector<vector<int>>& queries) {
// Since this is aperfeect binary tree , we can calculate depth, parent and LCA instead of storing
// depth : log(u)
// parent : u /2 ;
// kth ancenstor : u >> k
int Q = queries.size();
vector<int> ans(Q);
for(int i =0; i < Q; ++i){
int l = getLCA(queries[i][0], queries[i][1]);
int len = depth(queries[i][0]) + depth(queries[i][1]) - 2 * depth(l);
ans[i] = 1 + len;
}
return ans;
}
};So whatever problem we have discussed so far, we are either given parents array or edge list, what if we are given TreeNode* which has left and right pointers? How do we apply these techniques there.
For example this problem : 236. Lowest Common Ancestor of a Binary Tree
Approach 1 : Since we have to return TreeNode , one idea is to create a mapping from integer value to TreeNode* , all values are uniques , we can use a map for this and then use above mentioned algorithm.
Approach 2: During DFS call for calculating depth and parent , calculate all 2 power parent if that parent is not null.
Code for Approach 1
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
unordered_map<int, int> depth;
unordered_map<int, int> parent;
unordered_map<int, TreeNode*> numToNode;
unordered_map<int, unordered_map<int, int> > kthParent;
int M;
void dfs(TreeNode* root, int p=-1, int d = 0){
if(!root)
return;
// DO a mapping node value to pointer
numToNode[root->val] = root;
parent[root->val] = p;
depth[root->val] = d;
dfs(root->left, root->val, 1+d);
dfs(root->right, root->val, 1+d);
}
int getKth(int node, int k) {
for(int i = 0; i < M; ++i){
if( (1<<i) & k ){
node = kthParent[node][i];
if(node==-1)
break;
}
}
return node;
}
int getLCA(int u, int v){
if(depth[u] > depth[v])
swap(u, v);
int diff = depth[v] - depth[u];
v = getKth(v , diff) ; // v is on deeper ;evel, so we need to lift it up
if(u==v) // case where both node are originally in same subtree
return u;
for(int i = M; i>=0 ; --i){
int newU = kthParent[u][i];
int newV = kthParent[v][i];
if(newU==newV) // that means we are yet to find something not common,
continue;
u = newU;
v = newV;
}
// now here we have explored all the depth and now u and v parent is LCA
return parent[u];
}
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
// setup depth and parent
dfs(root);
// Now setup khParent
int N = numToNode.size();
M = log2(N) +1;
for(int i =0; i < M ; ++i){
for(auto& j : numToNode){
int u = j.first;
if(!i) // immediate parent
kthParent[u][i] = parent[u];
else if(kthParent[u][i-1]!=-1)
kthParent[u][i] = kthParent[kthParent[u][i -1]][i-1] ;
}
}
return numToNode [ getLCA(p->val, q->val) ];
}
};Time Complexity for most of the above problem:
For setting up the depth, parent array , we do DFS which take O(n),
For setting of kthParent array we need O(n . log n) time
For each query we need log(n) time, in some problem constant factor of depth is involved which I have ignored.
Space Complexity:
Since the kthParent array for each node need logn entry at most , O(n*logn)