

Hi,
I'll be covering the system design of TrueCaller.
Overview of TrueCaller
TrueCaller application provides caller details such as name and location (SIM registration) for an incoming call.
It can show details such as business, telemarketer, etc. category for a number as well as suggest if an incoming call is a possible spam call.
Also, lookup against as phone number or a name can be performed.
High Level Design
Functional Requirements
- Directory lookup via PhoneNumber
- Directory lookup via Name
- Spam detection
- Mark as spam
- User registration
Good to have functional requirements
- Classification as Business and business details
- Call block service
- Verified tick mark for validated users
- User should be able to export details from their contacts to truecaller directory
- User should be able to enter prefix for a number or name and view top results
Non-functional requirements
- System should be highly available
- System should be able to perform lookup quickly
- System can be slow in propogating updates but should become consistent over time (Eventual consistency)
- System should be able to withstand power failure, system reboot and yet not lose stored data (Persistence)
- System should be easily scalable to store details of new phonenumber
APIs
On basis of above details, we can conclude that TrueCaller application should expose following APIs for interaction as SDK or over network (RPC/REST/SOAP).
- getUserDetails(PhoneNumber)
- getUserDetails(Name)
- isSpam(PhoneNumber)
- isSpam(Name)
- markAsSpam(ITrueCallerProfile)
- addContact(Contact)
- register(ITrueCallerProfile)
Back-of-the-envelope calculation
Among all APIs listed above, the most used API would be getUserDetails as mostly truecaller service is used to know caller details of an incoming call. Hence, we can use it for calculating bottle-neck of system.
Moreover, getUserDetails(PhoneNumber) or getUserDetails(Name) would function on User data comprising of basic details such as name, phonenumber and isSpam value.
isSpam function can internally call getUserDetail and fetch details of isSpam field value.
The current world population is approx 8 billion.
Assuming, this service is used by 1% of worlwide population and on average each person has 2 phone numbers
(some people have more than 2 phone numbers e.g. business users, while some have 0 e.g., school student),
the system needs to store details of approximately 800 * 0.01 * 2 = 160 million(M) unique phone numbers.
If we look from perspective of unique users, the number would be 800 * 0.01 = 80M users.
Assuming all registered users are using this service actively and 10 phone calls are received on average,
getUserDetails API would be called (80M * 10) = 800M times a day.
At peak usage, there could be 80M * 1 = 80M requests in a second!
However, the number of new users registration on the system would roughly be 10K per day.
These numbers indicate that system would be read heavy but there could be a sudden spike in write requests for a small time. Read/Write ratio = 800M/10K = 80000:1
In a simple case, each user detail would comprise of following information:
- PhoneNumber
- Name
- isSpam
Assuming, PhoneNumber is stored in 13 bytes (3 char for country code and 10 for phone number), Average name taking 15 bytes (15 characters) and isSpam (just a boolean).
The amount of data stored in system would be : 160M (unique phone numbers) * 29 Bytes = ~5GB
The amount of data transfered on daily basis : 800M * 29 Bytes = ~25 GB (Header data is probably more than 29 Bytes, so actual data transferred would be ~150GB)
Average request per second : 800M / (24 * 60 * 60) = 10K/s
Throughput : ~2MB/s
Peak throughput : ~2.5GB/s (~15GB/s data with header)
Data stored in system in next 5 years = 10K * 29B * 5 * 365 = ~1GB
Note: Above data is only rough estimate and can vary alot with real data / final system.
Back-of-the-envelope vs Database design
Should back-of-envelope calculation be done first or should database be designed first?
Back-of-envelope estimation helps to understand the usage pattern of service/platform and hence could suggest to use appropriate database on basis of estimated values.
However, back-of-envelope calculation isn't perfectly accurate in terms of values used by final system.
Database design can define the accurate values for use in back-of-envelope leading to improved understanding of estimated values, which in-turn can further suggest to redesign database.
The process should be an iterative approach to get more accurate results instead of choosing one of the process over another and just get done in first attempt.
Database
Database should be extremely fast with read requests.
Database should support eventual consistency.
Database should support quick lookups with prefix phone number or name (Specialized requirement).
Note: Generally, a system has clear data storage and usage pattern and mapping requirements with different database features provides a clear picture of database suitable to do the job.
However, here, we've come across a requirement which isn't provided off-the-shelf in most databases and hence needs elaboarate discussion to determine suitable database.
The current system only contains basic details such as Name, Spam corresponding to phone number. As it evolves, it'd probably contain more details such
as business details or social media profiles, etc. The amount of extra information corresponding to each user would still be less to handle (approx 10KB),
however the schema should support evolution. Hence, we'd consider the entire UserInfo as a document corresponding to key phoneNumber or name. This structure
resembles with NoSQL databases such as Mongo, Redis, Cassandra, etc.
Most of the functionalities would be well served with a NoSQL database. However, we also want to provide a feature to lookup for a profile against a prefix phoneNumber
or Name. Three different ways to implement prefix match:
- Trie
- HashMap with guess based search to find next match
- Tree like structure with sorted child (keys) e.g. Red-black tree/ B+ Tree
- Inverted Index/Tokens
Before we dig further, we should keep in mind that number of prefix based search requests would be 1/100th fraction of complete phoneNumber or Name based search.
A trie structure has efficient storage and search algorithms for in-memory usage. However, no database support this off the shelf.
A graph database provides closest feature of creating nodes and links, still, the implementation would require considerable effort.
This structure could get results for prefix match on lesser number of disk seeks but might be slow for complete phoneNumber or name lookup.
A hashmap would often translate into direct reference to object of interest and hence should be fast for complete phoneNumber or name lookup. However, prefix
based search would require iterating over next key-set (i.e. 0-9) to get to next level and so on until final level. Also, the algorithm for this needs to be
managed by application.
A B+ tree based solution works great to minimize disk seeks to locate value of storage location for a given key. The performance for search over complete phoneNumber
or Name should be comparable with hashMap. Even this would require special algorithm to locate prefix based matches.
Inverted Index and token based search is simply an algorithm based on HashMap/Tree based design. It is used for regex based search and also has many use-cases in real
world for search related queries.
Given that write/updates are extremely less compared to read, my preference would be to use ElasticSearch which uses inverted-index solution for
achieveing both prefix search or complete search functionality. It also provides feature to create finite transducer (trie)
and stores it in memory for fast access.
Table / Data / Document
- UserInfo
- phoneNumber, preferredName, Set, isSpam
Index will be created on phoneNumber and names.
Note: It is possible that a single phoneNumber is associated with multiple names as different users might save it differently. Set is collection
of all names registered against a phoneNumber and preferredName is chosen using some algorithm as default name to be shown against a phoneNumber.
High level design
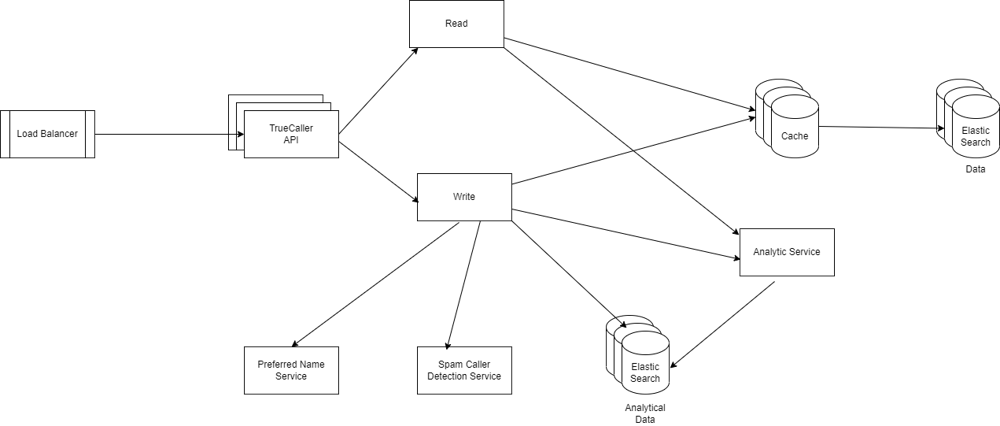
All read requests are performed using read-thorugh cache mechanism i.e. Application tries to read data from cache.
In case data doesn't exists in cache, cache fetches value from database and updates itself and returns same value back to user.
The write requests are also handled through write-back mechanism. All write requests update cache and gets accumulated and updates database in batches.
Write API also uses Preferred Name Service to identify correct name to be displayed against a phoneNumber. To detect spam, analytics on caller is used
alongwith user reported spam reports and database is updated.
Cache
ElasticSearch is slow at write/update queries and hence we've added a cache mechanism to reflect updates quickly. ElasticSearch is fast with search queries,
however, it is handling lot more data and would have higher overhead compared to cache, thus cache addition benefits search queries as well.
We can use Redis/Memcache for caching.
Bloom Filter
Bloom Filter helps to further improve search performance by quickly responding to queries where a profile doesn't exist on system.
It reduced the latency of search queries and helps to free up occupied ports!
Note:
- Fetching an object from HashMap isn't actually an O(1) operation as once hash is calculated, the list of objects with equal hash needs to be iterated to fetch exact match.
- Red-Black tree uses logarithmic time to get to exact object.
- Bloom Filters are simple set of hash sets. Hash of an object can be computed once and its existence can be checked in family of hash set. Time complexity would be O(No. of HashSet)
Bottleneck
The current design accomplishes fast search/read but is slow at write. If there is a sudden user growth, there could be too many contacts addititon to handle,
leading to too many write queries.
The write request utilizes write-back cache so there could be chance of data loss. However, if Redis is used as cache, it could provide persistence at cost of slight overhead.
This service is provided to worlwide users; servers should be located at important geogrphical regions to serve clients with minimal latency. We should keep cache at
all locations, while database can be deployed in limited locations ensuring redundancy and saving cost. The initial target server can be chosen through DNS based
load-balancing and subsequent load-balancing can be done through a load-balancer or reverse proxy.
Additional Consideration
- It should be expected that nodes in the system can fail. System should fail fast and quickly recover.
- Logging and Telemetry should be added at important services.
- System should be benchmarked with different load tests to identify services/nodes requiring updates.
Low level Design
TrueCaller application requries a deployment on servers to manage the service as well as client (installed on phone) to interact with deployed services.
As part of HLD discussion, we discussed APIs and layout of services and database on server side. We can build a client to improve users interaction with cloud service
by utilizing resources available locally for storage and compute.
Services on server side would be exposed as public APIs and functions on client devices would execute them to achieve certain functionalities. We'll try to cache
data on client side to improve search/read queries while write requests would update client's local data as well as server (via network call).
We'll implement features required on both client and server client and omit certain parts like client requesting data from server or APIs on server.
Note: The following implementaion is one of the ways to implement TrueCaller like system. It is not a production ready design, rather
a skeletal implementaion with some functionalities. Algorithms and DataStructure should be replaced appropriately to tune system to achieve best result.
Features
- Search a caller using Phone Number
- Search for a profile using Name
- Register a profile
- Import existing contacts to True Caller Global Directory
- Allow blocking/unblocking of phoneNumber
- Lookup for a profile using prefix of a phoneNumber
- Lookup for a profile using prefix of a name
- Mark a caller as spam
Overview
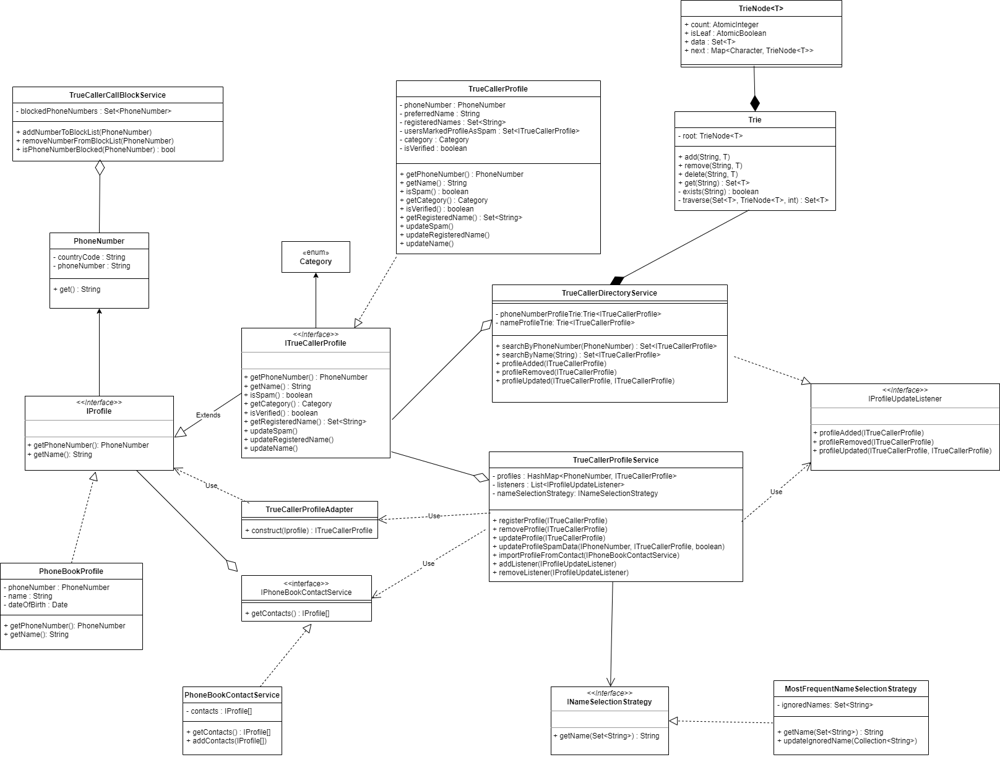
TrueCaller application can be broken down into Profile, Directory, Call Block Service broadly along with some helper classes.
Profile Service would manage profile and provide functionality to register new profile or import contacts from phoneBook to TrueCaller Directory.
Directory Service would manage all contacts and works as abstraction to get details based on phoneNumber or name.
Call Block Service would provide functionality to block callers.
Instead of creating concrete classes, we'd use interface to loosely couple classes and details such as Profiles and Listeners.
- IProfile : Profile with minimal information such as PhoneNumer and Name. A contact saved on SIM card usually has just a name and number.
- ITrueCallerProfile : Minimal set of details stored in TrueCaller directory. TrueCaller profile is more than a SIM contact and stores details such as spam, category (user, business, etc.) and can be made more feature rich at later stage.
- IPhoneBookContactService : Serves as interface to fetch details from contact directory stored on phone. This is provided by OS.
- INameSelectionStrategy : An abstraction for name selection service algorithm.
- IProfileUpdateListener : Serves as interface to allow true caller profile service to broadcast profile updates to listeners.
Design Principles
- TrueCaller profile should be extensible in future and hence interaction should be based on interface instead of concrete class.
- Handle logic to adapt phoneBook profile conversion to TrueCaller profile using an adapter to be able to support enhanced profiles from either component in future.
- Separate the logic for selecting most ideal name for a phone number while allowing selection of such service in a flexible manner. Users can create their own logic which could be used dynamically to select most approriate name on their phone against any contact.
- Internal storage and read pattern should be abstracted into true caller directory. Currently, this uses trie as data structure for storage and search but could be changed to any other structure without affecting any other component.
Main function documentation
- searchByPhoneNumber(PhoneNumber)
- Allows to search for TrueCaller profiles based on phoneNumber (complete or prefix)
- searchByName(String)
- Allows to search for TrueCaller profiles based on name (complete or prefix)
- registerProfile(ITrueCallerProfile)
- Stores TrueCallerProfile in persistent storage
- importProfileFromContact(IPhoneBookContactService)
- Imports all contacts from user local phone book to True Caller Directory
- addNumberToBlockList(PhoneNumber)
- Adds a phoneNumber to block list to automatically disconnect caller upon call
- removeNumberFromBlockList(PhoneNumber)
- Removes an existing phoneNumber from block list
Test Cases
Unit tests and Integration test verifies following functionality.
- Registration of new TrueCaller profile
- Searching for profiles using phoneNumber
- Searching for profiles using name
- Selection Strategy to choose most frequent user suggested name excluding Mom, Dad, etc.
- Block/Unblock a phoneNumber
- Update an existing profile
- Check if a caller is marked as spam
Code
Code is written in Java (17) and uses Gradle for build. SpringBoot framework is used to keep code simple and easily extend to use ORM/Database/APIs. Exception Handling/Logging/Telemetry is not included.