

- Dynamic programming is simple
- Dynamic programming is simple #2 (this article)
- Dynamic programming is simple #3 (multi-root recursion)
In the previous article I explained how to solve DP problems via the easiest example. In this article, I want to go through the template I've given before to solve a more complicated problem.
The problem is the following https://leetcode.com/problems/edit-distance/. This one is quite famous, so you likely have already seen it (or will see).
Let's try to follow our script again (assuming we have already determined this is a DP problem from the description).
What do we do each step
Task description says it clearly.
We either
Insert a character
Delete a character
Replace a character
Keep the character (in case it matches the character from the second word)
What does it mean in terms of recursive function?
Let's say we have two pointers pointing to some positions in each string. We assume again that the current state is correct, so we don't care for now how we ended up here.
Let's consider an example:
h o r s e
^- ptr1
r o s
^- ptr2Characters under the pointers don't match. So we have the following options:
Let's illustrate it another way, so it'll be simpler to understand.
Insert (virtual "o" inserted, so the characters now match, move the second pointer to continue matching process)
h o r s e h o [o] r s e
^ -> ^
r o s r o s
^ ^Delete ("r" is virtually deleted, move the first pointer)
h o r s e h o _ s e
^ -> ^
r o s r o s
^ ^Replace (replace "r" by "o", so we have a match and can move both pointers)
h o r s e h o o s e
^ -> ^
r o s r o s
^ ^So now, when you get the idea, we can quickly write the recursive function skeleton that performs those operations. I'll remind you again that we don't care about the correctness of our solution at this stage. We build the foundation for the solution to think only of one thing at any given moment. You can think of it as a higher level of abstraction if you wish.
class Solution:
def minDistance(self, word1: str, word2: str) -> int:
def dp(ptr1: int, ptr2: int) -> int:
# Match
if word1[ptr1] == word2[ptr2]:
dp(ptr1 + 1, ptr2 + 1)
# Insert
dp(ptr1, ptr2 + 1)
# Delete
dp(ptr1 + 1, ptr2)
# Replace
dp(ptr1 + 1, ptr2 + 1)
return dp(0, 0)I generally prefer going over tasks layer by layer like this. Now you know for sure your set of recursive calls is perfectly correct. So you don't need to return to that anymore. You just add the missing layers on the top.
Construct the next optimal solution from the subsequent recursive calls
Here we need to add two extensions to our code:
- Given the results of all subsequent recursive calls and assuming they are correct, construct the optimal solution for this set of arguments.
- Add base case(s) to complete the solution and make it valid (by mathematical induction).
First of all, let's notice that when we perform insert/delete/replace operations, we increase an edit distance by one. And if we have a match, edit distance stays the same. Given that, we can construct the next optimal solution like that (no base case yet):
class Solution:
def minDistance(self, word1: str, word2: str) -> int:
def dp(ptr1: int, ptr2: int) -> int:
min_edit_distance = len(word1) + len(word2) # just a big enough number, assuming no int overflow
# Match
if word1[ptr1] == word2[ptr2]:
min_edit_distance = min(min_edit_distance, dp(ptr1 + 1, ptr2 + 1))
# Insert
min_edit_distance = min(min_edit_distance, dp(ptr1, ptr2 + 1) + 1)
# Delete
min_edit_distance = min(min_edit_distance, dp(ptr1 + 1, ptr2) + 1)
# Replace
min_edit_distance = min(min_edit_distance, dp(ptr1 + 1, ptr2 + 1) + 1)
return min_edit_distance
return dp(0, 0)We can make this code much shorter, but I'll leave it verbose for the sake of comprehensibility.
The code above must make perfect sense for you if you've been following my description so far.
Now let's think about the base cases. There are two of them here:
ptr1runs over theword1length.ptr2runs over theword2length.
In the first case, we can either:
- Insert the same characters as left in
word2afterptr2intoword1. - Delete the rest of the characters from
word2(all characters afterptr2).
For the second case, we do the same but another way around.
With those base cases, the code will look like this:
class Solution:
def minDistance(self, word1: str, word2: str) -> int:
def dp(ptr1: int, ptr2: int) -> int:
# Base cases
if ptr1 == len(word1):
return len(word2) - ptr2
if ptr2 == len(word2):
return len(word1) - ptr1
min_edit_distance = len(word1) + len(word2)
# Match
if word1[ptr1] == word2[ptr2]:
min_edit_distance = min(min_edit_distance, dp(ptr1 + 1, ptr2 + 1))
# Insert
min_edit_distance = min(min_edit_distance, dp(ptr1, ptr2 + 1) + 1)
# Delete
min_edit_distance = min(min_edit_distance, dp(ptr1 + 1, ptr2) + 1)
# Replace
min_edit_distance = min(min_edit_distance, dp(ptr1 + 1, ptr2 + 1) + 1)
return min_edit_distance
return dp(0, 0)And once again, we got a valid backtracking solution. This solution gives the correct answer. However, it is suboptimal. Let's check its call graph.
As you see, there are lots of duplicating calls again.
Top-Down DP solution
This part is fairly straightforward in python, as you remember from the previous article. Just add the lru_cache decorator.
from functools import lru_cache
class Solution:
def minDistance(self, word1: str, word2: str) -> int:
@lru_cache(None)
def dp(ptr1: int, ptr2: int) -> int:
# Base cases
if ptr1 == len(word1):
return len(word2) - ptr2
if ptr2 == len(word2):
return len(word1) - ptr1
min_edit_distance = len(word1) + len(word2)
# Match
if word1[ptr1] == word2[ptr2]:
min_edit_distance = min(min_edit_distance, dp(ptr1 + 1, ptr2 + 1))
# Insert
min_edit_distance = min(min_edit_distance, dp(ptr1, ptr2 + 1) + 1)
# Delete
min_edit_distance = min(min_edit_distance, dp(ptr1 + 1, ptr2) + 1)
# Replace
min_edit_distance = min(min_edit_distance, dp(ptr1 + 1, ptr2 + 1) + 1)
return min_edit_distance
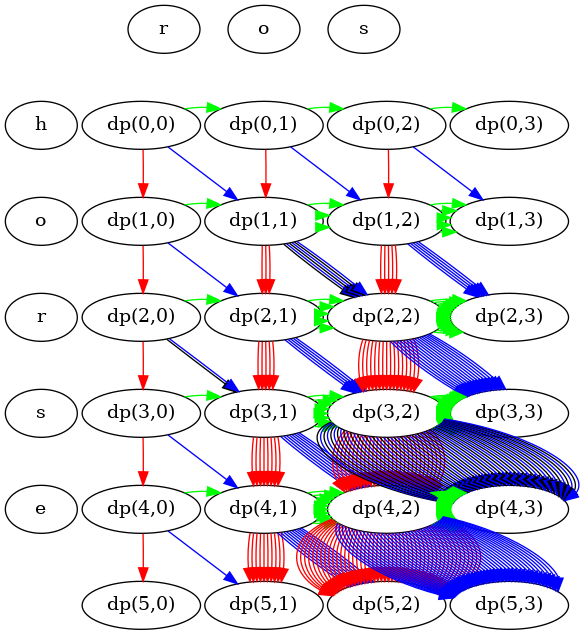
return dp(0, 0)The call graph for the Top-Down solution looks much better:

Also, as you see, the recursive calls form a nice grid. I made it like this to highlight that we can build a table to cache all the results of the recursive calls. I hope it is obvious if you look at the illustration above.
Bottom-Up solution
Now the last part is left. We want to construct a Bottom-Up solution.
Let's use the set of rules from the previous article.
class Solution:
def minDistance(self, word1: str, word2: str) -> int:
# Construct the table
dp = [
[len(word1) + len(word2)] * (len(word2) + 1)
for _ in range(len(word1) + 1)
]
# Set values for base cases
for ptr1 in range(len(word1)):
dp[ptr1][len(word2)] = len(word1) - ptr1
for ptr2 in range(len(word2)):
dp[len(word1)][ptr2] = len(word2) - ptr2
dp[len(word1)][len(word2)] = 0
# Iterate over all the values
for ptr1 in reversed(range(len(word1))):
for ptr2 in reversed(range(len(word2))):
min_edit_distance = len(word1) + len(word2)
# Match
if word1[ptr1] == word2[ptr2]:
min_edit_distance = min(min_edit_distance, dp[ptr1 + 1][ptr2 + 1])
dp[ptr1][ptr2] = min_edit_distance
# Insert
min_edit_distance = min(min_edit_distance, dp[ptr1][ptr2 + 1] + 1)
# Delete
min_edit_distance = min(min_edit_distance, dp[ptr1 + 1][ptr2] + 1)
# Replace
min_edit_distance = min(min_edit_distance, dp[ptr1 + 1][ptr2 + 1] + 1)
dp[ptr1][ptr2] = min_edit_distance
return dp[0][0]The only tricky thing here is determining the order we go over ptr1 and ptr2 values. But it becomes quite apparent when you look at the call graph from the previous section. Also, if you look at the dp function calls in the code, you can see the same. It takes practice to choose the traversal order correctly, but as you can see, it is not that complicated.
Bottom-Up (optimized)
There is a way to optimize the code further memory-wise. While calculating the values for the row, you might notice that we need only a row below. So we can rewrite the code, so it'll have O(N) complexity, where N is the length of the second word.
class Solution:
def minDistance(self, word1: str, word2: str) -> int:
# Construct the table (just the last line)
dp = [len(word1) + len(word2)] * (len(word2) + 1)
# Set values for base cases
for ptr2 in range(len(word2)):
dp[ptr2] = len(word2) - ptr2
dp[len(word2)] = 0
# Iterate over all the values
for ptr1 in reversed(range(len(word1))):
dp_old = dp
# Create new table line
dp = [len(word1) + len(word2)] * (len(word2) + 1)
dp[len(word2)] = len(word1) - ptr1 # Base case
for ptr2 in reversed(range(len(word2))):
min_edit_distance = len(word1) + len(word2)
# Match
if word1[ptr1] == word2[ptr2]:
min_edit_distance = min(min_edit_distance, dp_old[ptr2 + 1])
dp[ptr2] = min_edit_distance
# Insert
min_edit_distance = min(min_edit_distance, dp[ptr2 + 1] + 1)
# Delete
min_edit_distance = min(min_edit_distance, dp_old[ptr2] + 1)
# Replace
min_edit_distance = min(min_edit_distance, dp_old[ptr2 + 1] + 1)
dp[ptr2] = min_edit_distance
return dp[0]Once again, I've just slightly modified the code, to use dp_old instead of dp[ptr1 + 1] (next line effectively) and dp instead of dp[ptr1] (same line).
Final thoughts
Now you see the same script applies to other problems as well. Try practicing it yourself, and you'll notice the pattern.
Problem-solving skill is all about noticing patterns. You see a new problem description, but at the same time, you realize that we can reduce this problem down to taking action each step and finding a minimum or maximum on each step. Then you remember how you solved similar problems and then use the same technique we described here for the new one.
The same happens, for example, when you realize we can transform the problem to the problem of finding the shortest path in a graph. In this case, you use Dijkstra (which you already know).
Problem-solving is the ability to recognize the problem you have already seen and know how to solve (or a combination of them) behind the vague description.
That was a typical DP problem (with a 2-dimensional table, instead of the Nx2 table we used last time). There are 3-dimensional "tables" as well, and even 4-dimensional. But the idea is the same. You get a recursive function with 3 or 4 arguments with a limited set of values, and you just cache the recursive calls in that "table". So it is not that different from the case with just two arguments we've seen today.
In the following articles, I'll show you techniques, which diverge a little bit from the ones we've seen before. Even though the idea stays the same, if you blindly apply the template from the previous article, you'll probably get stuck because it won't work. But those "special cases" are like 10% of the problems, and you can already solve 90% of them. It's time to celebrate that. Don't forget to treat yourself for learning hard. Get some rest, get some coffee, walk in the park, meet your friends.
Stay tuned!
