

I'm writing for the sole purpose of my system design interview preparation. Read it at your own discretion. Well, comments and discussion regarding this topic are always appreciated.
Gathering requirements
The problem description is intended to be ambigious as the interviewer wants to check if we're able to ask reasonable questions, collect requirements and define a core set of features for a minimum viable product (MVP) that we can start to work with.
In this case, I'd like to ask a few questions to make things clear, including
- Q: What are main features of the video sharing platform?
- A: The system will be a public platform that users can watch and upload videos.
- Q: Who will be the users of the system?
- A: Users will be around the world.
- Q: How are they going to use it?
- A: Users will use various kinds of devices to visit our service.
- Q: Is there any external dependencies? What are the upstream and downstream system?
- A: The system will leverage existing authentication system.
Once I get answers for above questions, I'd confirm with the interviewer that I'll design a video platform that enables users to watch and upload videos. Authentication is out of the scope of this problem.
Based on information that I gathered so far, I come up with a bunch of functional and non-functional requirements below and confirm with interviewer.
Functional requirements
- Users can watch videos on the platform
- Users can upload their own videos
Non-functional requirements
- The platform should be highly available
- The response time for users in different regions should be at the same level
- The platform should scale while userbase is increasing
Estimation
The goal of this step is to come up with estimated numbers of how scalable our system should be.
We have two types of requests, read and write. Write request(upload videos) will take much longer time and is ususally much less than read requests (recall how often you watch videos on Youtue and the times you upload videos).
So, let's focus on read request firstly. As an easy start, assume our service receives and completes 1000 request per second (RPS). I use request to reflect common server requirements rather than functionality specific requirements eg. Tweets, Views ... because it's business independent. Functionality specific requirements will be eventually mapped to server requirements anyway.
For one day, we'll have 1000 * 24 * 60 * 60 ~= 1000 * 30 * 3000 = 90 million = 90 M requests
For one year, we'll hvae 90M * 12 * 30 = 90 M * 360 ~= 100 M * 300 = 30 billion = 30 B requests
For five years, we'll have 30B * 5 = 150 billion = 150 B requests in total.
The next assumption I'm going to make is the response time. Assume our response time SLA is 200ms.
Then I need to have 1000 / (1s / 200ms) = 200 threads in total to handle 1000 RPS. So, the next question will be how many servers do I need to have 200 threads. One simple formula for estimating ideal Java thread pool size is
Number of threads = Number of Available Cores * Target CPU utilization * (1 + Wait time / Service time)
- Waiting time - is the time spent waiting for IO bound tasks to complete, say waiting for HTTP response from remote service.
- Service time - is the time spent being busy, say processing the HTTP response, marshaling/unmarshaling, etc.
Because our video sharing web service is not computing-intensive application(though it can be, considering video encoding, compression), I assume the Wait time / Service time ratio will be relatively large, say 50. And also assume our server has 2 CPU cores running at 50% utilization.
Then, each of this kind of server can support 2 * 0.5 * (1 + 50) ~= 50 threads and since we need to have 200 threads to handle 1000 RPS, so we need 200 / 50 = 4 servers to handle 1000 RPS.
Let's switch to write requests (upload video). Assume the read / write or say watch / upload ratio is 100. So, we're expecting 1000 / 100 = 10 write requests per second. Please note that the uploading time varies because the video size and network speed play important roles here. So, the estimate is even more subjective.
Assume average video size is 500 MB and network bandwidth on customer side is 100 mbps. Then,
- each video would take
500 MB / (100 mbps / 8) = 40 secondsto upload - since we have 10 upload request per second, we have
40 * 10 = 400concurrent uploading, the bandwidth requirement on our side will be400 * 100 mbps = 40000 mbps - total memory usage will be
40000 mbps / 8 = 5000 MB = 5GB, if our server has2GB RAM, then we need to have 3 servers for uploading. However, because we have 400 concurrent uploading, it requires 400 threads to serve. This time theWait time / Service timeratio is close to 1, and if we still use 2 CPU cores server running at 50% utilization, each server could support2 * 0.5 * (1+1) = 2 threads. So, we need400 / 2 = 200servers for video uploading.
Design Goals
Latency - Is our service latency sensitive (Or in other words, Are requests with high latency and a failing request, equally bad?)
Yes, to provide great customer experience, latency is very important for video service
Consistency - Does our service require tight consistency?
Not really, it's okay if things are eventually consistent.
Availability - Does this problem require 100% availability?
Yes
System interface definition
At this step, I'm designing the APIs that our service exposes to clients. Based on features and requirements I gathered at the first step, the video platform I'm going to design is apparently a web application. The best practice is to decouple the frontend and backend so that the frontend and backend can evolve independently as long as they obey the contract(backend service provides API and clients consume the API).
There are different API design style, SOAP, REST, and graphQL. I'll create a set of RESTful API as it's lightweight compared with SOAP and it's the broadly supported and the most popular one among developers.
Designing RESTful API requires us to first identity resources and then map HTTP methods to operations.
Apparently, we have at least two resources, video and user.
Our service supports operations including upload video, play video, create user, get user info. So, we can have following APIs.
Upload video API
POST /v1/videos
Request header
Content-Type: multipart/form-data
Request body
userID
videoTitle
videoDescription
language
videoFile binary data
Response body
videoProcessingJobIDThe upload API uses HTTP POST method and v1/videos endpoint to upload a video file with videoTitle, videoDescription...... metadata passed in the request body. Wheter adding API versioning like "v1" in the API is still controversal but I think it'll help us evolve APIs freely. So, I use it in my design.
Using HTTP POST to upload a bianry file is not as simple as we expect. The Content-Type has to be multipart/form-data and the video file binary data will be included between boundary parameters. I'm not going to cover technical details at here. And also, we can even split the big video file and upload chunks in parallel. Again, that's implementation details.
Please note that the response of video uploading request will return a videoProcessingJobID that clients can use to check processing status. The reason is that once video is uploaded to our service, we'll do a series of time-consuming operations like deduplication, compression and create copies with different resolutions, etc.. I'd like to do them in an asynchronous way to provide a good customer experience. Client can polling with the videoProcessingJobID to check the progress later on.
The watch API is also straight forward and it's like
GET /v1/videos/<videoID>
Request header
access_token
Response body
videoURLAs we learned earlier, authentication and authorization is out of the scope of this problem. I simply add the access_token to the request header. Idealy, once the user is done authentication during login, an id_token or access_token (depends on the OIDC flow that the authentication flow is using) would be issued to the user and it'll be passed to backend, decoded and validated there.
At here, I just ignore the access control part for videos. In reality, the returned videoURL has to be either short lived or has some authorzation mechanism to prevent undesired access.
Next is the user creation and fetching user info API
POST /v1/users
Request body
userName
region
age
Response body
userIDGET /v1/users/<userID>
Request header
access_token
Response body
userID
userName
region
ageData Model
After APIs are ready, let's talk about data model. We have two entities, video and user. One user can have multiple videos and one video can only belong to one user.
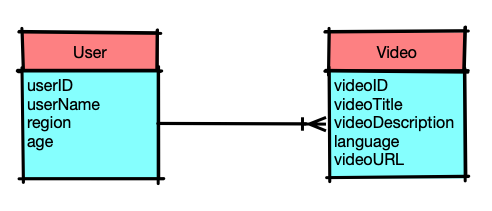
High Level Design
Before we jump into the high level design, we need to have workflows in mind.
- upload video
- user upload video, once the upload is done, create a job and put it into the video post processing queue and return the job id to client for future progress checking
- our service picks up job from the queue and conducts a serise processing, e.g. check duplication, compression
- once post-processign is done, persist video in object storage (e.g. AWS S3 bucket)
- persist video metadata (including video URL in S3 bucket)
- watch video
- user sends request to access a video by videoID
- server return the URL of the requested video
Now, let's consider the database for user info and video metadata. Considering the scalability requirement of our service and relatively simple data model, I'm going to use NoSQL database, more specifically, AWS DynamoDB for our user info and video metadata. Using AWS S3 as the video storage.
Designing schema for NoSQL database is quite different from that of SQL database. In SQL schema, we first identify entites, denormalize them and put into tables. The relation between entities is expressed through foreign keys and the query flexibility is provided by SQL query language.
For NoSQL database, especially DynamoDB, we first identify access patterns. And then, design database schema and denormalize data if it's necessary. DynamoDB provides excellent scalability at the the cost of less access flexibility. DynamoDB recommends putting all entites into one table with carefully designed partition key and optional sort key. In case we want to support new access pattern in future, we can add GSI (Global Secondary Index) to DynamoDB, we do have flexibility to some extent.
The access patterns we'll support are
- given a videoID, access the video
- given a userID, access the user info
- given a userID, access all videos that are uploaded by the user
So, I design the DynamoDB schema as below
*Entity* *Partition Key* *Sort Key*
Video #VIDEO#<VideoID> #METADATA#<VideoID>
User #USER#<UserID> #METADATA#<UserID>
UserVideoMapping #USER#<VideoID> #VIDEO#<VideoID>The #USER and #VIDEO are like name space that avoid to have collisons between entities.
Recall that we have to use at least 4 servers to support 1000 RPS, the high level design is like below
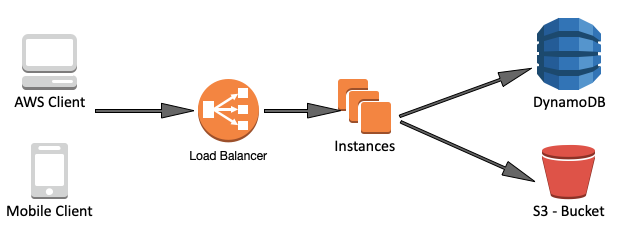
Detailed Design
How to scale the architecture? Ideally, before making any decisions about scaling, we should first do performance tests against our system, monitor CPU and memory usage and latency and find the bottleneck. At here, I just assume our services will be running into common problems as other data intensive application scales.
Servers and database are usually bottlenecks while visitors are increasing. Cahce can significantly reduce the presessure to servers and databases; hence, improve the scalability
- use CDN (AWS Cloudfront) to serve static resources, including videos, video thumbnails ...
- use cache (AWS DAX) for user info and video metadata access
Besides that, since I'm using DynamoDB, a managed service, as the database storage, it does all the heavy lifting for us, e.g. master-slave replication, multi-master writes, etc.. All we need to do is to setup proper auto scale settings.
The next part we want to change is the "Instances" in the above diagram. Our service is now a monolithic service, all functions are coupled together. Even though, we have multiple instances running, each functions can't scale individually. For example, the video deduplication and video compression are apparently computing intensive and require hardware with powerful CPU while the web serving part could be potentially memory intensive as it needs more RAM to serve incoming requests.
The solution is to break monolithic service into micro-services. Micro-services expose APIs to outside and they use APIs to communicate with others. As the number of services and hence, APIs increased, it's impossbile to ask clients to call each fine-grained APIs directly and we actually only want to expose stable coarse-grained APIs to clients so that client applications don't need to update their code frequently. To solve this problem, we introduce API gateway into our system. API gateway will encapsulate fine-grained APIs provided by each micro-services and provide APIs to clients.

Please note that I only drew two micro-services above; it's over-simplified. In reality, it'll definitely have more services and orchestrators that aggregate responses from subsets of micro-services. Anyway, it at least shows the basic idea that each micro-service can scale independently.
Summary
I just write up a skeleton of the design. There can be numerous details to dive deep, like
- Add more features
- how to add view count to a video
- how to add user interaction, "Like", "+1", to a video,
- how to follow a user
- System implementation details, with and without leveraging AWS
- load balancing strategy, health check, service high availability
- database sharding, fault tolerance
- large volume of uploading requests, how to queueing them
Once again, thanks for reading, comments are appreciated.