

PhonePe Interview Experience: PhonePe | SDE 2 (3-5 Years) | Bangalore | Aug 2023 [Reject]
Problem Statement
The problem was presented as a feature use-case in existing product. We have an in-house browser [like Chrome, FireFox] to serve customers, and a data analytics team. Data analytics team frequently produces files with list of websites that are malicious and should not be visited due to security concerns. We need to build a System to consume and process the data from data analystics team, and let the browser know if a website is malicious or not for any given URL.
Malicious URL Service Design
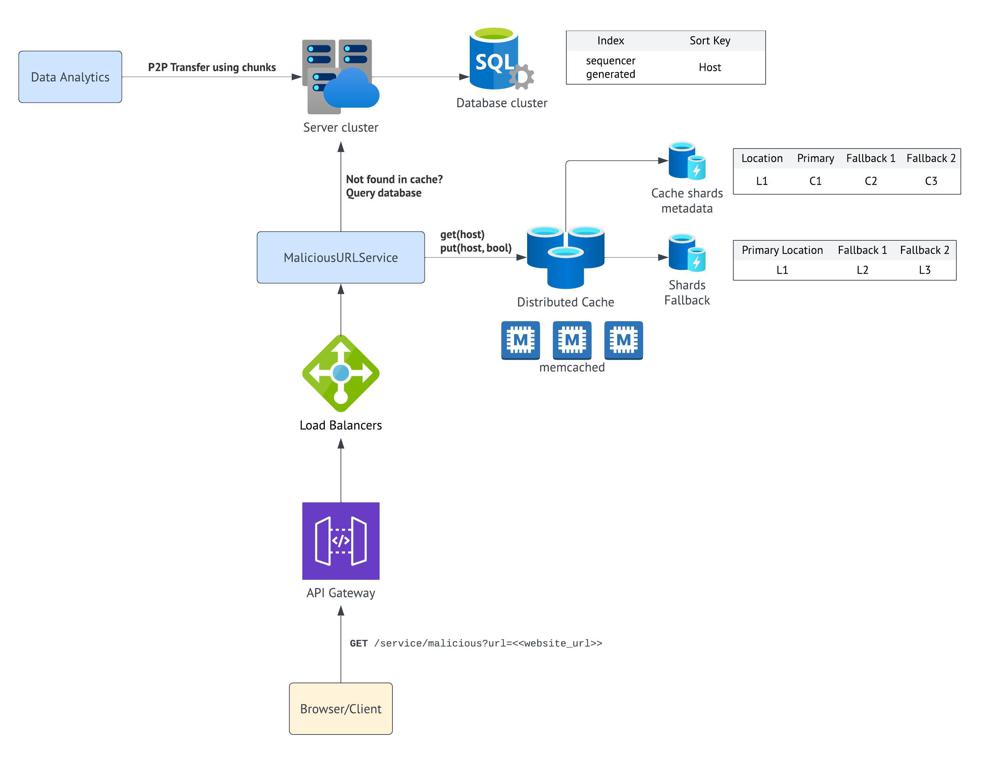
This is a rough representation of what I designed since we used a basic online portal for design and wasn't this organised in first go. This is for reference only.
We started off the discussion in parts after finialising how would be break-down the problem.
The problem can be broken down into "Data Analystics" team as data provider who has data over shared server for distribution. That data will be consumed by a sevrice we create, and finally expose that service to client (browser) through API.
1. Transfer the file to the distribution server
Started of with simple file transfers (eg FTP) but the issue will arise as files get larger which the intervier hinted on by mentioning average file size (> 2GB) which should be resilient to network disruption, hence I thought in terms of data packet transfers rather than whole file.
Basically similar to a P2P (peer-to-peer) transfer, we divide the file into fixed blocks of chunks and transfer those sequentially. Since size of file is known and fixed, we can send that data to distribution server which will reserve the amount of space for incoming file and send acknowledgement for each chunk recieved, hence if a chunk is missed we can straight away continue to send missed packet and then next.
In event of network disruption, we can see how many packets have reached. Or of we are using multiple P2P trasnfer the same file (like BitTorrent), we can use binary hash to represent the presence of chunk and the convert to Hex and send back to uploading peers to see which chunks needs to be sent.
2. Storage solutions on distribution server
Since our requirement is to protect against malicious websites as whole not just warning that sub-pages might be malicious, we assume if a host has a malicious webpage then it could have another sub-pages with same intent too and we add complete host to the list.
The reduces the storage significantly since we don't need to store complete URLs, and in future even if we did, we can map the host to sub-pages saving space and joins.
We make the host as SortKey and using sequencer to generate index since we need to keep design open to extension. This way we can also have searching a host easier by indexing on host name.
3. Service consuming the data and its optimisiation for distributed network
Firstly, we needed to process how we are going to process the incoming request with URL, for which we basically trimmed the improtant variable down to host, and then send a "search existence" query to distributed database if output is not already stored in cache, which can easily be parallised due to it's exlusive nature.
Then we store the outcome of it in a local cache with an appropriate TTL. The requests would look something like:
get(host) : bool
put(host, bool)We had to pick an appropriate caching tool, I thought of 2 choices "Redis" and "Memcached" as they are pretty standard but picked "Memcached" since it is optimised for simple string storages as opposed to complex structure storage in Redis which we don't need hence giving faster read/write times. We would have to implement replication and fallabacks by ourselves.
For distributed system, and for it to be available and consistent we create shards of cache which can have Primary-Secondary replication algorithm where we first write to primary, which has responsibilty to replicate to next 2 fallback cache shards. This data of primary and falllback cache shards is stored as metadata.
For having Fault tolerance, we can have location fallbacks as well. Let's say a complete cache shard cluster fails (like in event of disasters - this was asked by interviwer), we can have pre-generated metadata of current cluster location and closest fallabck locations.
We had pretty in-depth discussion on the distributed cache solution, and in the end I was asked how would we optimise for space in cache since we are using too many replications at all lcoations. I didn't have any strong defense for it so we didn't pursue it further.
4. Exposing API
This was pretty straight-foward, we use a single API call through API Gateway, which is bounded to cluster of load balancers to manage incoming requests.
GET /service/malicious?url=<<website url>>We didn't get more time to discuss further since we already had reached time limit of 1hr, but we had good enough discussion on HLD.