

PLEASE UPVOTE IF YOU LIKE THIS CONTENT
All in one place to FAANG
starting with algorithms
There are many algorithms used in computer science and programming. Here are explanations of some algorithms:
Sorting algorithms: Sorting algorithms are used to arrange a list of items in a specific order. Some common sorting algorithms include:
Bubble sort: This algorithm repeatedly swaps adjacent elements if they are in the wrong order until the list is sorted.
Selection sort: This algorithm repeatedly selects the smallest element in the unsorted portion of the list and moves it to the beginning of the sorted portion.
Insertion sort: This algorithm builds the sorted list one element at a time by inserting each element into its correct position in the sorted portion of the list.
Merge sort: This algorithm divides the list into smaller sublists, sorts each sublist recursively, and then merges the sorted sublists back together.
Quick sort: This algorithm selects a pivot element, partitions the list into elements smaller than the pivot and elements larger than the pivot, and then sorts the two partitions recursively.
Search algorithms: Search algorithms are used to find a specific item in a list or data structure. Some common search algorithms include:
Linear search: This algorithm checks each element in the list sequentially until the target element is found.
Binary search: This algorithm works on a sorted list by repeatedly dividing the list in half and checking whether the target element is in the left or right half.
Depth-first search (DFS): This algorithm traverses a graph in depth-first order, visiting all the vertices in a path before backtracking and visiting other paths.
Breadth-first search (BFS): This algorithm traverses a graph in breadth-first order, visiting all the vertices at a given distance from the starting vertex before moving on to vertices at a greater distance.
Dynamic programming (DP) algorithms: DP algorithms are used to solve complex problems by breaking them down into smaller subproblems and solving each subproblem only once. Some common DP algorithms include:
Memoization: This algorithm stores the results of expensive function calls and returns the cached result when the same inputs occur again.
Tabulation: This algorithm builds a table of solutions to subproblems and uses the table to solve the larger problem.
Longest common subsequence (LCS): This algorithm finds the longest subsequence that is common to two sequences.
Knapsack problem: This algorithm finds the maximum value that can be obtained by selecting a subset of items with a given weight limit.
Graph algorithms: Graph algorithms are used to operate on graphs, which are mathematical structures that represent a set of objects (vertices or nodes) and the connections between them (edges). Some common graph algorithms include:
Dijkstra's algorithm: This algorithm finds the shortest path between two vertices in a weighted graph with non-negative edge weights.
Bellman-Ford algorithm: This algorithm finds the shortest path between two vertices in a weighted graph with negative edge weights.
Prim's algorithm: This algorithm finds the minimum spanning tree of a weighted graph.
Kruskal's algorithm: This algorithm finds the minimum spanning tree of a weighted graph by adding edges in increasing order of weight.
The ArrayDeque class in Java is a doubly-ended queue (Deque) that supports element insertion and removal at both the front and the rear of the deque. The ArrayDeque class is similar to the LinkedList class, but it is implemented using an array, which makes it more efficient for operations that involve accessing elements near the beginning or end of the deque.
The following are the methods of the ArrayDeque class:
addFirst(E e): Adds the specified element to the front of the deque.
addLast(E e): Adds the specified element to the rear of the deque.
clear(): Removes all elements from the deque.
contains(Object o): Returns true if the specified element is contained in the deque.
element(): Returns the element at the front of the deque without removing it.
getFirst(): Returns the element at the front of the deque.
getLast(): Returns the element at the rear of the deque.
offerFirst(E e): Adds the specified element to the front of the deque, if possible.
offerLast(E e): Adds the specified element to the rear of the deque, if possible.
peek(): Returns the element at the front of the deque without removing it.
pollFirst(): Removes and returns the element at the front of the deque.
pollLast(): Removes and returns the element at the rear of the deque.
removeFirst(): Removes and returns the element at the front of the deque.
removeLast(): Removes and returns the element at the rear of the deque.
size(): Returns the number of elements in the deque.
toArray(): Returns an array containing all of the elements in the deque.
The following are some examples of how to use the ArrayDeque class:
// Create a new ArrayDeque
ArrayDeque deque = new ArrayDeque<>();
// Add some elements to the deque
deque.addFirst(1);
deque.addLast(2);
deque.addLast(3);
// Print the elements in the deque
System.out.println(deque);
// Remove the first element from the deque
int firstElement = deque.removeFirst();
// Print the first element that was removed
System.out.println(firstElement);
// Check if the deque contains a specific element
boolean containsElement = deque.contains(2);
// If the deque contains the element, print "true"
if (containsElement) {
System.out.println("true");
}
// Get the element at the front of the deque without removing it
int elementAtFront = deque.element();
// Print the element at the front of the deque
System.out.println(elementAtFront);
// Get the size of the deque
int size = deque.size();
// Print the size of the deque
System.out.println(size);
// Get the elements in the deque as an array
Integer[] array = deque.toArray(new Integer[0]);
// Print the elements in the deque as an array
System.out.println(array);
PriorityQueue is a class that implements the Queue interface. It is a heap-based data structure, which means that the elements are stored in a way that the smallest element is always at the top of the queue.
The PriorityQueue class has the following methods:
add(element): Adds the specified element to the queue.
offer(element): Adds the specified element to the queue, but does not throw an exception if the queue is full.
peek(): Returns the smallest element in the queue without removing it.
poll(): Returns the smallest element in the queue and removes it.
remove(): Removes the smallest element from the queue.
size(): Returns the number of elements in the queue.
clear(): Removes all elements from the queue.
The PriorityQueue class has the following properties:
Comparator: The comparator used to compare elements in the queue. If no comparator is specified, the elements are compared using their natural ordering.
Capacity: The maximum number of elements that can be stored in the queue.
Size: The number of elements currently stored in the queue.
The PriorityQueue class has the following pros and cons:
Pros:
It is a very efficient data structure for storing and retrieving elements in sorted order.
It is thread-safe, so multiple threads can access the queue without causing any problems.
It is a generic class, so it can be used to store any type of object.
Cons:
It is not a very efficient data structure for storing and retrieving elements in random order.
It can be difficult to implement custom comparators for the queue.
It is not a very efficient data structure for storing a large number of elements.
Here are some examples of how to use the PriorityQueue class:
Java
// Create a priority queue
PriorityQueue queue = new PriorityQueue<>();
// Add elements to the queue
queue.add(1);
queue.add(2);
queue.add(3);
// Get the smallest element in the queue
int smallestElement = queue.peek();
// Remove the smallest element from the queue
queue.poll();
// Check the size of the queue
int size = queue.size();
// Clear the queue
queue.clear();
A linked list is a data structure that consists of a collection of nodes which together represent a sequence. Each node contains data and a reference (or link) to the next node in the sequence. The first node in the sequence is called the head and the last node is called the tail.
The Java LinkedList class implements the List interface and provides a linked list implementation of the List data structure. It allows for the storage and retrieval of elements in a doubly-linked list data structure, where each element is linked to its predecessor and successor elements.
The following are the methods of the Java LinkedList class:
add(E e): Adds the specified element to the end of the list.
addFirst(E e): Adds the specified element to the beginning of the list.
addLast(E e): Adds the specified element to the end of the list.
addAll(Collection<? extends E> c): Adds all of the elements in the specified collection to the end of the list.
addAll(int index, Collection<? extends E> c): Adds all of the elements in the specified collection to the list, starting at the specified index.
clear(): Removes all of the elements from the list.
contains(Object o): Returns true if the list contains the specified element.
get(int index): Returns the element at the specified index in the list.
indexOf(Object o): Returns the index of the first occurrence of the specified element in the list, or -1 if the element is not found.
isEmpty(): Returns true if the list is empty.
iterator(): Returns an iterator over the elements in the list.
remove(int index): Removes the element at the specified index from the list.
remove(Object o): Removes the first occurrence of the specified element from the list.
set(int index, E element): Replaces the element at the specified index in the list with the specified element.
size(): Returns the number of elements in the list.
subList(int fromIndex, int toIndex): Returns a view of the specified portion of the list.
The following are the properties of the Java LinkedList class:
Nodes: The nodes in a linked list are the individual elements that make up the list. Each node contains data and a reference to the next node in the sequence.
Head: The head of a linked list is the first node in the sequence.
Tail: The tail of a linked list is the last node in the sequence.
Size: The size of a linked list is the number of nodes in the list.
The following are the pros and cons of using a linked list:
Pros:
Linked lists are easy to implement.
Linked lists are efficient for inserting and deleting elements in the middle of the list.
Linked lists can be used to represent acyclic graphs.
Cons:
Linked lists are not as efficient for accessing elements at a specific index as arrays.
Linked lists can be slower than arrays for iterating over the elements in the list.
Linked lists can take up more memory than arrays.
Overall, linked lists are a versatile data structure that can be used for a variety of tasks. They are particularly well-suited for tasks that involve inserting and deleting elements in the middle of the list.
how to identify & solve any problem
Identifying the appropriate algorithm for a given problem is an important skill in competitive programming Here are some tips for identifying the algorithm that can be used to solve a problem:
Read the problem statement carefully: The problem statement often contains clues about the type of algorithm that can be used to solve the problem. For example, if the problem involves finding the shortest path between two points, Dijkstra's algorithm or Bellman-Ford algorithm may be appropriate.
Look for patterns in the input: The input to the problem may contain patterns that suggest a particular algorithm. For example, if the input is a sorted list, binary search may be appropriate.
Consider the time and space complexity: The time and space complexity of the problem can help narrow down the choice of algorithm. For example, if the problem involves finding all possible subsets of a set, a brute-force approach may have exponential time complexity, while a dynamic programming approach may have polynomial time complexity.
Consider the constraints of the problem: The constraints of the problem, such as the size of the input or the time limit, can help determine the appropriate algorithm. For example, if the input is very large, a brute-force approach may not be feasible, and a more efficient algorithm may be required.
Look for similar problems: If the problem is similar to a problem that has been solved before, the same algorithm may be applicable. It can be helpful to review past problems and solutions to identify common patterns and algorithms.
By considering these factors, you can identify the appropriate algorithm for a given problem and increase your chances of solving the problem efficiently and effectively.
DP
Dynamic programming (DP) is a technique used in computer programming to solve complex problems breaking them down into smaller subproblems and solving each subproblem only once. Here are some common ways that DP is used in competitive programming:
Memoization: This is a technique used to store the results of expensive function calls and return the cached result when the same inputs occur again. Memoization is often used in DP to avoid redundant calculations and improve the efficiency of the algorithm.
Tabulation: This is a technique used to build a table of solutions to subproblems and use the table to solve the larger problem. Tabulation is often used in DP when the subproblems can be solved in a specific order and the solution to each subproblem depends only on the solutions to smaller subproblems.
Top-down DP: This is a technique used to solve a problem recursively by breaking it down into smaller subproblems and solving each subproblem recursively. Top-down DP often uses memoization to avoid redundant calculations.
Bottom-up DP: This is a technique used to solve a problem iteratively by building up the solution to larger subproblems from the solutions to smaller subproblems. Bottom-up DP often uses tabulation to store the solutions to subproblems in a table.
State compression: This is a technique used to reduce the memory usage of a DP algorithm by compressing the state space of the problem. State compression is often used in DP problems where the state space is large and the solutions to subproblems can be computed using only a small subset of the state.
Bitmask DP: This is a technique used to represent the state space of a DP problem using a bit vector and perform operations on the state space using bitwise operations. Bitmask DP is often used in DP problems where the state space is a set of binary choices and the solutions to subproblems can be computed using only the current state and the choices made so far.
Dynamic programming is a powerful technique used to solve a wide range of problems. Here is list of some common variations of dynamic programming:
Memoization: This is a technique used to optimize recursive algorithms by storing the results of expensive function calls and returning the cached result when the same inputs occur again.
Tabulation: This is a technique used to build a table of solutions to subproblems and use those solutions to solve the larger problem.
Longest Common Subsequence: This variation finds the longest subsequence that is common to two sequences.
Longest Increasing Subsequence: This variation finds the longest subsequence of an array of integers that is in increasing order.
Knapsack Problem: This variation involves selecting a subset of items with maximum value, subject to a weight constraint.
Coin Change Problem: This variation involves finding the minimum number of coins required to make a given amount of change.
Edit Distance: This variation finds the minimum number of operations required to transform one string into another.
Matrix Chain Multiplication: This variation involves finding the most efficient way to multiply a sequence of matrices.
Maximum Subarray Sum: This variation finds the contiguous subarray within an array of integers that has the largest sum.
Traveling Salesman Problem: This variation involves finding the shortest possible route that visits every city in a given list exactly once and returns to the starting city.
These are just a few examples of the many variations of dynamic programming that exist.
dp on grids
Here are some common dynamic programming algorithms on grids with their corresponding pseudocode:
Grid Paths:
Given a grid of size n x n, find the number of paths from the top-left corner to the bottom-right corner, moving only right or down.
Pseudocode:
dp[0][0] = 1
for i from 1 to n:
dp[0][i] = 1
dp[i][0] = 1
for i from 1 to n:
for j from 1 to n:
dp[i][j] = dp[i-1][j] + dp[i][j-1]
return dp[n-1][n-1]
Minimum Path Sum:
Given a grid of size m x n, find the minimum sum of a path from the top-left corner to the bottom-right corner, moving only right or down.
Pseudocode:
for i from 1 to m:
grid[i][0] += grid[i-1][0]
for j from 1 to n:
grid[0][j] += grid[0][j-1]
for i from 1 to m:
for j from 1 to n:
grid[i][j] += min(grid[i-1][j], grid[i][j-1])
return grid[m-1][n-1]
Unique Paths with Obstacles:
Given a grid of size m x n with obstacles, find the number of unique paths from the top-left corner to the bottom-right corner, moving only right or down. Obstacles are represented by 1 and empty cells are represented by 0.
Pseudocode:
if grid[0][0] == 1:
return 0
dp[0][0] = 1
for i from 1 to m:
if grid[i][0] == 0:
dp[i][0] = dp[i-1][0]
for j from 1 to n:
if grid[0][j] == 0:
dp[0][j] = dp[0][j-1]
for i from 1 to m:
for j from 1 to n:
if grid[i][j] == 0:
dp[i][j] = dp[i-1][j] + dp[i][j-1]
return dp[m-1][n-1]
Maximal Square:
Given a grid of 0's and 1's, find the area of the largest square containing only 1's.
Pseudocode:
max_side = 0
for i from 0 to m:
for j from 0 to n:
if i == 0 or j == 0:
dp[i][j] = grid[i][j]
else if grid[i][j] == 1:
dp[i][j] = min(dp[i-1][j], dp[i][j-1], dp[i-1][j-1]) + 1
max_side = max(max_side, dp[i][j])
return max_side * max_side
These are just a few examples of dynamic programming algorithms on grids. There are many more variations and applications of dynamic programming on grids.
FAANG preparation
FAANG (Facebook, Amazon, Apple, Netflix, Google) are some the top technology companies in the world, and they often ask questions related to data structures and algorithms (DSA) in their interviews. Here are some common DSA topics and questions asked by FAANG companies:
Arrays and Strings:
Find the missing number in an array
Reverse a string
Check if a string is a palindrome
Find the longest common prefix in an array of strings
Linked Lists:
Reverse a linked list
Detect a cycle in a linked list
Merge two sorted linked lists
Remove duplicates from a linked list
Stacks and Queues:
Implement a stack using two queues
Implement a queue using two stacks
Evaluate a postfix expression using a stack
Implement a min stack that supports constant time minimum value retrieval
Trees and Graphs:
Implement a binary search tree
Find the lowest common ancestor of two nodes in a binary tree
Implement depth-first search and breadth-first search on a graph
Find the shortest path between two nodes in a graph
Dynamic Programming:
Find the maximum subarray sum
Find the longest increasing subsequence in an array
Find the minimum number of coins required to make change for a given amount
Find the maximum sum of non-adjacent elements in an array
To prepare for FAANG DSA questions, it is important to have a strong foundation in the above topics. Here are some tips for preparing:
Practice coding: The best way to prepare for DSA questions is to practice coding. Solve as many problems as you can on platforms like LeetCode, HackerRank, and Codeforces.
Review data structures and algorithms: Review the concepts of data structures and algorithms, and make sure you understand how they work and when to use them.
Learn from others: Read solutions to problems and learn from others' approaches. Attend coding competitions and participate in online forums to learn from other programmers.
Practice under time constraints: Practice solving problems under time constraints to simulate the pressure of a real interview.
Stay up-to-date: Stay up-to-date with the latest DSA trends and techniques by reading blogs, attending conferences, and following industry experts.
By following these tips and practicing regularly, you can improve your DSA skills and increase your chances of success in FAANG interviews.
Kadane's algorithm is a dynamic programming algorithm used to solve various problems related maximum subarray sum.
Here is a list of all the variations of Kadane's algorithm:
Maximum Subarray Sum: This is the most common variation of Kadane's algorithm. It finds the contiguous subarray within an array of integers that has the largest sum.
Maximum Subarray Product: This variation finds the contiguous subarray within an array of integers that has the largest product.
Maximum Subarray Sum with Indices: This variation not only finds the maximum subarray sum, but also returns the starting and ending indices of the subarray.
Maximum Subarray Sum with Wrap-Around: This variation allows the subarray to wrap around to the beginning of the array. For example, in the array [8, -1, 3, 4], the maximum subarray sum with wrap-around would be 15 (the subarray [3, 4, 8]).
Maximum Subarray Sum with K Elements: This variation finds the maximum subarray sum with exactly k elements. For example, in the array [1, 2, 3, 4, 5], the maximum subarray sum with 3 elements would be 12 (the subarray [3, 4, 5]).
Maximum Subarray Sum with Non-Adjacent Elements: This variation finds the maximum subarray sum where the selected elements are not adjacent. For example, in the array [2, 1, 5, 8, 4], the maximum subarray sum with non-adjacent elements would be 13 (the subarray [2, 5, 6]).
Maximum Subarray Sum with Negative Numbers: This variation allows the array to contain negative numbers. It finds the contiguous subarray within an array of integers that has the largest sum, even if the sum is negative.
Maximum Sum Increasing Subsequence: This variation finds the maximum sum of an increasing subsequence within an array of integers.
Maximum Sum Bitonic Subsequence: This variation finds the maximum sum of a bitonic subsequence within an array of integers.
Maximum Sum Circular Subarray: This variation finds the maximum sum of a circular subarray within an array of integers.
These are just a few examples of the many variations of Kadane's algorithm that exist.
graphs
Here is a list of some common variations of graphs:
Directed Graphs: In a directed graph, the edges have a direction associated with them. This means that the edges have a starting vertex and an ending vertex.
Undirected Graphs: In an undirected graph, the edges do not have a direction associated with them. This means that the edges can be traversed in both directions.
Weighted Graphs: In a weighted graph, each edge has a weight associated with it. This weight can represent a distance, cost, or any other metric.
Unweighted Graphs: In an unweighted graph, each edge does not have a weight associated with it. This means that all edges have the same weight.
Connected Graphs: A connected graph is a graph in which there is a path between any two vertices.
Disconnected Graphs: A disconnected graph is a graph in which there are one or more vertices that are not connected to any other vertices.
Complete Graphs: A complete graph is a graph in which there is an edge between every pair of vertices.
Bipartite Graphs: A bipartite graph is a graph in which the vertices can be divided into two disjoint sets such that every edge connects a vertex in one set to a vertex in the other set.
Cyclic Graphs: A cyclic graph is a graph that contains at least one cycle.
Acyclic Graphs: An acyclic graph is a graph that does not contain any cycles.
Tree: A tree is a connected acyclic graph.
Directed Acyclic Graphs (DAGs): A directed acyclic graph is a directed graph that does not contain any cycles.
These are just a few examples of the many variations of graphs that exist.
Graph problems can be approached using a variety of techniques, depending on the specific and its constraints. Here are some common approaches to solving graph problems:
Breadth-First Search (BFS): BFS is a graph traversal algorithm that visits all the vertices of a graph in breadth-first order. It is useful for finding the shortest path between two vertices, or for finding all vertices at a certain distance from a given vertex.
Depth-First Search (DFS): DFS is a graph traversal algorithm that visits all the vertices of a graph in depth-first order. It is useful for finding cycles in a graph, or for exploring all possible paths in a graph.
Dijkstra's Algorithm: Dijkstra's algorithm is a shortest path algorithm that works on graphs with non-negative edge weights. It is useful for finding the shortest path between two vertices in a weighted graph.
Bellman-Ford Algorithm: Bellman-Ford algorithm is a shortest path algorithm that works on graphs with negative edge weights. It is useful for finding the shortest path between two vertices in a weighted graph with negative edge weights.
Floyd-Warshall Algorithm: Floyd-Warshall algorithm is a shortest path algorithm that works on graphs with positive or negative edge weights. It is useful for finding the shortest path between all pairs of vertices in a weighted graph.
Topological Sorting: Topological sorting is an algorithm that orders the vertices of a directed acyclic graph (DAG) such that for every directed edge (u, v), vertex u comes before vertex v in the ordering. It is useful for scheduling tasks that have dependencies.
Minimum Spanning Tree: Minimum spanning tree is a tree that connects all the vertices of a graph with the minimum possible total edge weight. It is useful for finding the most efficient way to connect a set of points.
Strongly Connected Components: Strongly connected components are subsets of vertices in a directed graph where every vertex in the subset is reachable from every other vertex in the subset. It is useful for finding clusters of related vertices in a directed graph.
Maximum Flow: Maximum flow is the maximum amount of flow that can be sent from a source vertex to a sink vertex in a flow network. It is useful for finding the most efficient way to send data through a network.
These are just a few examples of the many approaches to solving graph problems. The specific approach used will depend on the problem at hand and its constraints.
Here are the pseudocode for the approaches mentioned in the previous answer:
1.th-First Search (BFS):
import java.util.*;
public class BFS {
public static Set<Integer> bfs(Map<Integer, List<Integer>> graph, int start) {
Queue<Integer> queue = new LinkedList<>();
Set<Integer> visited = new HashSet<>();
queue.add(start);
while (!queue.isEmpty()) {
int vertex = queue.poll();
if (!visited.contains(vertex)) {
visited.add(vertex);
for (int neighbor : graph.get(vertex)) {
queue.add(neighbor);
}
}
}
return visited;
}
public static void main(String[] args) {
Map<Integer, List<Integer>> graph = new HashMap<>();
graph.put(0, Arrays.asList(1, 2));
graph.put(1, Arrays.asList(2));
graph.put(2, Arrays.asList(0, 3));
graph.put(3, Arrays.asList(3));
Set<Integer> visited = bfs(graph, 2);
System.out.println(visited); // Output: [0, 2, 3, 1]
}
}
Depth-First Search (DFS):
import java.util.*;
public class DFS {
public static void dfs(Map<Integer, List<Integer>> graph, int start, Set<Integer> visited) {
visited.add(start);
for (int neighbor : graph.get(start)) {
if (!visited.contains(neighbor)) {
dfs(graph, neighbor, visited);
}
}
}
public static void main(String[] args) {
Map<Integer, List<Integer>> graph = new HashMap<>();
graph.put(0, Arrays.asList(1, 2));
graph.put(1, Arrays.asList(2));
graph.put(2, Arrays.asList(0, 3));
graph.put(3, Arrays.asList(3));
Set<Integer> visited = new HashSet<>();
dfs(graph, 2, visited);
System.out.println(visited); // Output: [0, 2, 3, 1]
}
}
Dijkstra's Algorithm:
import java.util.*;
public class Dijkstra {
public static Map<Integer, Integer> dijkstra(Map<Integer, Map<Integer, Integer>> graph, int start) {
Map<Integer, Integer> distances = new HashMap<>();
for (int vertex : graph.keySet()) {
distances.put(vertex, Integer.MAX_VALUE);
}
distances.put(start, 0);
PriorityQueue<int[]> queue = new PriorityQueue<>((a, b) -> a[1] - b[1]);
queue.add(new int[]{start, 0});
while (!queue.isEmpty()) {
int[] current = queue.poll();
int vertex = current[0];
int distance = current[1];
if (distance > distances.get(vertex)) {
continue;
}
for (int neighbor : graph.get(vertex).keySet()) {
int newDistance = distance + graph.get(vertex).get(neighbor);
if (newDistance < distances.get(neighbor)) {
distances.put(neighbor, newDistance);
queue.add(new int[]{neighbor, newDistance});
}
}
}
return distances;
}
public static void main(String[] args) {
Map<Integer, Map<Integer, Integer>> graph = new HashMap<>();
graph.put(0, new HashMap<>());
graph.get(0).put(1, 4);
graph.get(0).put(2, 1);
graph.put(1, new HashMap<>());
graph.get(1).put(3, 1);
graph.get(1).put(2, 2);
graph.put(2, new HashMap<>());
graph.get(2).put(3, 5);
Map<Integer, Integer> distances = dijkstra(graph, 0);
System.out.println(distances); // Output: {0=0, 1=4, 2=1, 3=5}
}
}
# dp on strings
Given a string str, a partitioning of the string is a palindrome partitioning if every sub-string of the partition is a palindrome. Determine the fewest cuts needed for palindrome partitioning of the given string.
Example 1:
Input: str = "ababbbabbababa"
Output: 3
Explaination: After 3 partitioning substrings
are "a", "babbbab", "b", "ababa".
static int palindromicPartition(String str)
{
List<List<String>> ans = new ArrayList<>();
int n= str.length();
int dp[][] = new int[n][n];
// f(0,ans,str,new ArrayList<>(),dp,n);
// return ans.size();
int A[] = new int[n];
for(int i=0;i<n;i++){
A[i]=i;
for(int j=0;j<=i;j++){
if(isPalindrom(j,i,str,dp)){
if(j==0) A[i]=0;
else A[i]=Math.min(A[i],A[j-1]+1);
}
}
}return A[n-1];
}
static void f(int i,List<List<String>> ans,String st,List<String> tem,int dp[][],int n){
if(i==n){
ans.add(new ArrayList<>(tem));
return;
}
for(int j=i;j<n;j++){
if(isPalindrom(i,j,st,dp)){
tem.add(st.substring(i,j+1));
f(j+1,ans,st,tem,dp,n);
tem.remove(tem.size()-1);
}
}
}
static boolean isPalindrom(int i,int j,String s,int dp[][]){
if(dp[i][j]!=0) return dp[i][j]==1;
while(i<j){
if(s.charAt(i)!=s.charAt(j)) {
dp[i][j]=-1;
return false;
}
i++;
j--;
}
dp[i][j]=1;
return true;
}
# greedy Assume you are an awesome parent of N children and want to give your children some cookies out of given M cookies. But, you should give each child atmost one cookie.
Each child i has a greed factor greed [ i ], which is the minimum size of cookie that the child will be content with; and each cookie j has a size sz [ j ]. If sz [ j ] >= greed [ i ], we can assign the cookie j to the child ith, and the child i will be content.
Your goal is to maximize the number of your content children and return the maximum number.
Example 1:
Input:
N = 3
M = 2
greed [ ] = {1, 2, 3}
sz [ ] = {1, 1}
Output: 1
Explanation:
You have 3 children and 2 cookies. The greed factors of 3 children are 1, 2, 3.
And even though you have 2 cookies, since their size is both 1, you could only make the child whose greed factor is 1 content.
You need to return 1.
static int maxChildren(int N,int M,int g[], int sz[]) {
Arrays.sort(g);
Arrays.sort(sz);
int i=0;
for(int j=0;i<N && j<M;j++)
if(sz[j]>=g[i])i++;
return i;
}
Given weights and values of N items, we need to put these items in a knapsack of capacity W to get the maximum total value in the knapsack.
Note: Unlike 0/1 knapsack, you are allowed to break the item.
Example 1:
Input:
N = 3, W = 50
values[] = {60,100,120}
weight[] = {10,20,30}
Output:
240.00
Explanation:Total maximum value of item
we can have is 240.00 from the given
capacity of sack.
Example 2:
double fractionalKnapsack(int W, Item arr[], int n)
{
Arrays.sort(arr,(a,b)->{
double r2=((double)b.value/(double)b.weight);
double r1=((double)a.value/(double)a.weight);
return (r1<r2)?1:(r1>r2)?-1:0;
});
double ans =0,cur=0;
for(int i=0;i<arr.length;i++){
if(cur+arr[i].weight<=W){
ans+=arr[i].value;
cur+=arr[i].weight;
}else {
double rem= W-cur;
ans+=(arr[i].value/(double)arr[i].weight) * rem;
break;
}
}return ans;
}
Given an infinite supply of each denomination of Indian currency { 1, 2, 5, 10, 20, 50, 100, 200, 500, 2000 } and a target value N.
Find the minimum number of coins and/or notes needed to make the change for Rs N. You must return the list containing the value of coins required.
Example 1:
Input: N = 43
Output: 20 20 2 1
Explaination:
Minimum number of coins and notes needed
to make 43.
static List<Integer> minPartition(int N)
{
// code here
int A[] = { 1, 2, 5, 10, 20, 50, 100, 200, 500, 2000 } ;
List<Integer> ans = new ArrayList<>();
for(int i=A.length-1;i>=0;i--){
while(N>=A[i]){
N-=A[i];
ans.add(A[i]);
}
}return ans;
}
You are a owner of lemonade island, each lemonade costs $5. Customers are standing in a queue to buy from you and order one at a time (in the order specified by bills). Each customer will only buy one lemonade and pay with either a $5, $10, or $20 bill. You must provide the correct change to each customer so that the net transaction is that the customer pays $5.
Given an integer array bills of size N where bills [ i ] is the bill the ith customer pays, return true if you can provide every customer with the correct change, or false otherwise.
Example 1:
Input:
N = 5
bills [ ] = {5, 5, 5, 10, 20}
Output: True
Explanation:
From the first 3 customers, we collect three $5 bills in order.
From the fourth customer, we collect a $10 bill and give back a $5.
From the fifth customer, we give a $10 bill and a $5 bill.
Since all customers got correct change we return true.
Example 2:
Input:
N = 5
bills [ ] = {5, 5, 10, 10, 20}
Output: False
static boolean lemonadeChange(int N, int bills[]) {
// code here
int five_usd = 0;
int ten_usd = 0;
for(int i: bills){
if(i == 5) five_usd++;
else if(i == 10){
five_usd--;
ten_usd++;
} else if(ten_usd > 0){
ten_usd--;
five_usd--;
} else {
five_usd -= 3;
}
if(five_usd < 0) return false;
}
return true;
}
Given an expression string x. Examine whether the pairs and the orders of {,},(,),[,] are correct in exp.
For example, the function should return 'true' for exp = [()]{}{[()()]()} and 'false' for exp = [(]).
Note: The drive code prints "balanced" if function return true, otherwise it prints "not balanced".
Example 1:
Input:
{([])}
Output:
true
Explanation:
{ ( [ ] ) }. Same colored brackets can form
balanced pairs, with 0 number of
unbalanced bracket.
bool ispar(string x)
{
stack<char>st;
for(int i=0;i<x.length();i++){
if(!st.empty() && (st.top()==')'||st.top()==']'|| st.top()=='}')){
return false;
}else if(!st.empty() &&((st.top()=='(' && x[i]==')')||(st.top()=='{' && x[i]=='}')||(st.top()=='[' && x[i]==']'))){
st.pop();
}else{
st.push(x[i]);
}
}
// Your code here
if(!st.size()){
return true;
}
return false;
}
There is one meeting room in a firm. There are N meetings in the form of (start[i], end[i]) where start[i] is start time of meeting i and end[i] is finish time of meeting i.
What is the maximum number of meetings that can be accommodated in the meeting room when only one meeting can be held in the meeting room at a particular time?
Note: Start time of one chosen meeting can't be equal to the end time of the other chosen meeting.
Example 1:
Input:
N = 6
start[] = {1,3,0,5,8,5}
end[] = {2,4,6,7,9,9}
Output:
4
Explanation:
Maximum four meetings can be held with
given start and end timings.
The meetings are - (1, 2),(3, 4), (5,7) and (8,9)
public static int maxMeetings(int start[], int end[], int n)
{
int meet[][] = new int[n][3];
for(int i=0;i<n;i++){
meet[i][0]=start[i];
meet[i][1]=end[i];
meet[i][2]=i;
}
int ans =1;
Arrays.sort(meet,(a,b)->{//end time asc
if(a[1]<b[1]) return -1;
else if(a[1]>b[1]) return 1;
else if(a[2]<b[2]) return -1;
return 1;
});
int endp=meet[0][1];
for(int i=1;i<n;i++){
if(meet[i][0]>endp){
endp=meet[i][1];
ans++;
}
}
return ans;
}
Given arrival and departure times of all trains that reach a railway station. Find the minimum number of platforms required for the railway station so that no train is kept waiting.
Consider that all the trains arrive on the same day and leave on the same day. Arrival and departure time can never be the same for a train but we can have arrival time of one train equal to departure time of the other. At any given instance of time, same platform can not be used for both departure of a train and arrival of another train. In such cases, we need different platforms.
Example 1:
Input: n = 6
arr[] = {0900, 0940, 0950, 1100, 1500, 1800}
dep[] = {0910, 1200, 1120, 1130, 1900, 2000}
Output: 3
Explanation:
Minimum 3 platforms are required to
safely arrive and depart all trains.
Example 2:
Input: n = 3
arr[] = {0900, 1100, 1235}
dep[] = {1000, 1200, 1240}
Output: 1
Explanation: Only 1 platform is required to
safely manage the arrival and
static int findPlatform(int arr[], int dep[], int n)
{
Arrays.sort(arr);
Arrays.sort(dep);
int i=1,j=0,cur=1,ans=0;
while(i<n && j<n){
if(arr[i]<=dep[j]){
cur++;
i++;
}else if(arr[i]>dep[j]){
cur--;
j++;
}
ans =Math.max(ans,cur);
}return ans;
}
Given a set of N jobs where each jobi has a deadline and profit associated with it.
Each job takes 1 unit of time to complete and only one job can be scheduled at a time. We earn the profit associated with job if and only if the job is completed by its deadline.
Find the number of jobs done and the maximum profit.
Note: Jobs will be given in the form (Jobid, Deadline, Profit) associated with that Job.
Example 1:
Input:
N = 4
Jobs = {(1,4,20),(2,1,10),(3,1,40),(4,1,30)}
Output:
2 60
Explanation:
Job1 and Job3 can be done with
maximum profit of 60 (20+40).
Example 2:
Input:
N = 5
Jobs = {(1,2,100),(2,1,19),(3,2,27),
(4,1,25),(5,1,15)}
Output:
2 127
Explanation:
2 jobs can be done with
maximum profit of 127 (100+27).
int[] JobScheduling(Job arr[], int n)
{
// Your code here
Arrays.sort(arr,(a,b)->{
if(a.profit>b.profit) return -1;
else if(a.profit<b.profit) return 1;
return 0;
});
int maxd=0,prof=0,ans=0;
for(int i=0;i<n;i++) maxd=Math.max(maxd,arr[i].deadline);
int fill[] = new int[maxd+1];
for(int i=0;i<maxd+1;i++) fill[i]=-1;
for(int i=0;i<n;i++){
for(int j=arr[i].deadline;j>0;j--){
if(fill[j]==-1){
fill[j]=i;
ans++;
prof+=arr[i].profit;
break;
}
}
}return new int[]{ans,prof};
}
Given a collection of Intervals, the task is to merge all of the overlapping Intervals.
Example 1:
Input:
Intervals = {{1,3},{2,4},{6,8},{9,10}}
Output: {{1, 4}, {6, 8}, {9, 10}}
Explanation: Given intervals: [1,3],[2,4]
[6,8],[9,10], we have only two overlapping
intervals here,[1,3] and [2,4]. Therefore
we will merge these two and return [1,4],
[6,8], [9,10].
Example 2:
Input:
Intervals = {{6,8},{1,9},{2,4},{4,7}}
Output: {{1, 9}}
public int[][] overlappedInterval(int[][] A)
{
Arrays.sort(A,(a,b)->a[0]-b[0]);
List<int[]> tem = new ArrayList<>();
int st=A[0][0];
int en=A[0][1];
for(int i=1;i<A.length;i++){
if(A[i][0]<=en){
en=Math.max(en,A[i][1]);
}else {
tem.add(new int[]{st,en});
st=A[i][0];
en=A[i][1];
}
}
tem.add(new int[]{st,en});
return tem.stream().toArray(int[][]::new);
}
# recursion
Your task is to implement the function atoi. The function takes a string(str) as argument and converts it to an integer and returns it.
Note: You are not allowed to use inbuilt function.
Example 1:
Input:
str = 123
Output: 123
Example 2:
Input:
str = 21a
Output: -1
Explanation: Output is -1 as all
characters are not digit only.
int atoi(String str) {
// Your code here
int n=str.length();
int ans=0,fl=-1,i=0;
if(str.charAt(0)=='-'){
fl=0;
i=1;
}
for(;i<n;i++){
char cg =str.charAt(i);
if(cg>='a'&& cg<='z'|| cg=='-'|| cg=='+') return -1;
ans=ans*10+Integer.parseInt(cg+"");
}return (fl==0)?-1*ans:ans;
}
Given a number and its reverse. Find that number raised to the power of its own reverse.
Note: As answers can be very large, print the result modulo 109 + 7.
Example 1:
Input:
N = 2
Output: 4
Explanation: The reverse of 2 is 2
and after raising power of 2 by 2
we get 4 which gives remainder as
4 by dividing 1000000007.
Example 2:
Input:
N = 12
Output: 864354781
Explanation: The reverse of 12 is 21
and 1221 , when divided by 1000000007
gives remainder as 864354781.
long mod =(long)1e9+7;
long power(int N,int R)
{
long ans =1;
long te=R;
// if(te<0) te=-1*te;
while(te>0){
if(te%2==1){
ans =(ans*N)%mod;
te-=1;
}else{
N=(N *N)%mod;
te/=2;
}
}
if(te<0) ans =(long)1/ans;
return ans%mod;
}
Given a string S, Find all the possible subsequences of the String in lexicographically-sorted order.
Example 1:
Input : str = "abc"
Output: a ab abc ac b bc c
Explanation : There are 7 subsequences that
can be formed from abc.
Example 2:
Input: str = "aa"
Output: a a aa
Explanation : There are 3 subsequences that
can be formed from aa.
public List<String> AllPossibleStrings(String s)
{
// Code here
List<String> ans = new ArrayList<>();
for(int i=0;i<(1<<s.length());i++){//0 to 2^8-1
StringBuilder sb = new StringBuilder();
for(int j=0;j<s.length();j++){//0 to len(s)
if((i&(1<<j))!=0)sb.append(s.charAt(j));
}
if(sb.length()>0)//check for empty str
ans.add(sb.toString());
}
Collections.sort(ans);
return ans;
}
Given a pair of strings, Geek wants to find the better string. The better string is the string having more number of distinct subsequences.
If both the strings have equal count of distinct subsequence then return str1.
Example 1:
Input:
str1 = "gfg", str2 = "ggg"
Output: "gfg"
Explanation: "gfg" have 7 distinct subsequences whereas "ggg" have 4 distinct subsequences.
Example 2:
Input: str1 = "a", str2 = "b"
Output: "a"
Explanation: Both the strings have only 1 distinct subsequence.
public static String betterString(String s, String s2) {
int dp[][] = new int[s.length()+1][s2.length()+1];
for(int i=0;i<s.length();i++)Arrays.fill(dp[i],-1);
int l1=memo(0,0,s,dp);
dp= new int[s.length()][s2.length()];
for(int i=0;i<s.length();i++)Arrays.fill(dp[i],-1);
int l2=memo(0,0,s2,dp);
return l1>l2?s: l1==l2? s: s2;
}
static int count()
static int memo(int i,int j,String s,int dp[][]){
if(i==s.length()||j==s.length()) return 1;
if(dp[i][j]!=-1) return dp[i][j];
if(i!=j && s.charAt(i)!=s.charAt(j)){
dp[i][j]=memo(i+1,j,s,dp)+memo(i+1,j+1,s,dp);
}else dp[i][j]=memo(i+1,j,s,dp);
return dp[i][j];
}
Given an array of integers and a sum B, find all unique combinations in the array where the sum is equal to B. The same number may be chosen from the array any number of times to make B.
Note:
1. All numbers will be positive integers.
2. Elements in a combination (a1, a2, …, ak) must be in non-descending order. (ie, a1 ≤ a2 ≤ … ≤ ak).
3. The combinations themselves must be sorted in ascending order.
Example 1:
Input:
N = 4
arr[] = {7,2,6,5}
B = 16
Output:
(2 2 2 2 2 2 2 2)
(2 2 2 2 2 6)
(2 2 2 5 5)
(2 2 5 7)
(2 2 6 6)
(2 7 7)
(5 5 6)
Example 2:
Input:
N = 11
arr[] = {6,5,7,1,8,2,9,9,7,7,9}
B = 6
Output:
(1 1 1 1 1 1)
(1 1 1 1 2)
(1 1 2 2)
(1 5)
(2 2 2)
(6)
static ArrayList<ArrayList<Integer>> combinationSum(ArrayList<Integer> A, int B)
{
ArrayList<ArrayList<Integer>> ans = new ArrayList<>();
f(0,A,B,ans,new ArrayList<>());
return ans;
}
static void f(int i,ArrayList<Integer> A, int B,
ArrayList<ArrayList<Integer>> ans ,ArrayList<Integer> tem){
if(i==A.size()){
if(B==0){
ans.add(new ArrayList<>(tem));
}return;
}
if(A.get(i)<=B){
tem.add(A.get(i));
f(i+1,A,B-A.get(i),ans,tem);
tem.remove(tem.size()-1);
}
f(i+1,A,B,ans,tem);
}
You are given a collection of numbers (candidates) and a target number (target), find all unique combinations in candidates where the candidate numbers sum to the target. Each number in candidates may only be used once in the combination.
Note: The solution set must not contain duplicate combinations.
Example:
Input: candidates = [10,1,2,7,6,1,5], target = 8.
Output: [[1,1,6], [1,2,5], [1,7], [2,6]].
Explanation: These are the unique combinations whose sum is equal to the target.
public static List<List<Integer>> combinationSum2(int[] a, int s) {
List<List<Integer>> ans = new ArrayList<>();
Arrays.sort(a);
f(0,a,s,ans,new ArrayList<>());
return ans;
}
static void f(int ind,int a[],int t,List<List<Integer>> ans,ArrayList<Integer> tem){
if(t==0){
ans.add(new ArrayList<>(tem));
return;
}
for(int i=ind;i<a.length;i++){
if(i>ind && a[i]==a[i-1]) continue;
if(a[i]>t) break;
tem.add(a[i]);
f(i+1,a,t-a[i],ans,tem);
tem.remove(tem.size()-1);
}
}
Given a list arr of N integers, print sums of all subsets in it.
Example 1:
Input:
N = 2
arr[] = {2, 3}
Output:
0 2 3 5
Explanation:
When no elements is taken then Sum = 0.
When only 2 is taken then Sum = 2.
When only 3 is taken then Sum = 3.
When element 2 and 3 are taken then
Sum = 2+3 = 5.
Example 2:
Input:
N = 3
arr = {5, 2, 1}
Output:
0 1 2 3 5 6 7 8
ArrayList<Integer> subsetSums(ArrayList<Integer> arr, int N){
// code here
ArrayList<Integer> ans = new ArrayList<>();
rec(ans,0,0,N,arr);
Collections.sort(ans);
return ans;
}
void rec(ArrayList<Integer> ans,int i,int sum,int n,ArrayList<Integer> arr){
if(i==n){
ans.add(sum);
return;
}
rec(ans,i+1,sum+arr.get(i),n,arr);
rec(ans,i+1,sum,n,arr);
}
You are given an integer array nums that may contain duplicates. Your task is to return all possible subsets. Return only unique subsets and they can be in any order.
Example:
Input:
nums = [1,2,2]
Output:
[[],[1],[1,2],[1,2,2],[2],[2,2]]
Explanation:
We can have subsets ranging from length 0 to 3. which are listed above. Also the subset [1,2] appears twice but is printed only once as we require only unique subsets.
public static ArrayList<ArrayList<Integer>> printUniqueSubsets(int[] nums) {
ArrayList<ArrayList<Integer>> ans = new ArrayList<>();
Arrays.sort(nums);
rec(0,nums,new ArrayList<>(),ans);
return ans;
}
static void rec(int id,int A[],ArrayList<Integer> tem,ArrayList<ArrayList<Integer>> ans){
ans.add(new ArrayList<>(tem));
for(int i=id;i<A.length;i++){
if(i!=id && A[i]==A[i-1]) continue;//unique checlk
tem.add(A[i]);
rec(i+1,A,tem,ans);
tem.remove(tem.size()-1);
}
}
# DFS 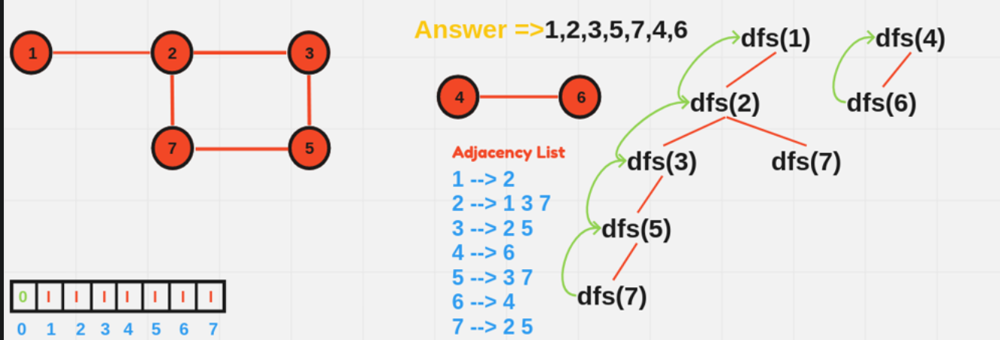
// { Driver Code Starts
// Initial Template for Java
import java.util.*;
import java.lang.*;
import java.io.*;
class GFG {
public static void main(String[] args) throws IOException {
BufferedReader br =
new BufferedReader(new InputStreamReader(System.in));
int T = Integer.parseInt(br.readLine().trim());
while (T-- > 0) {
String[] s = br.readLine().trim().split(" ");
int V = Integer.parseInt(s[0]);
int E = Integer.parseInt(s[1]);
ArrayList<ArrayList<Integer>> adj =
new ArrayList<ArrayList<Integer>>();
for (int i = 0; i < V; i++) adj.add(new ArrayList<Integer>());
for (int i = 0; i < E; i++) {
String[] S = br.readLine().trim().split(" ");
int u = Integer.parseInt(S[0]);
int v = Integer.parseInt(S[1]);
adj.get(u).add(v);
adj.get(v).add(u);
}
Solution obj = new Solution();
ArrayList<Integer> ans = obj.dfsOfGraph(V, adj);
for (int i = 0; i < ans.size(); i++)
System.out.print(ans.get(i) + " ");
System.out.println();
}
}
}
// } Driver Code Ends
class Solution {
// Function to return a list containing the DFS traversal of the graph.
public ArrayList<Integer> dfsOfGraph(int V, ArrayList<ArrayList<Integer>> adj) {
// Code here
ArrayList<Integer> dfsStore = new ArrayList<>();
boolean vis[] = new boolean[V + 1];
for(int i = 0; i < V; i++){
if(vis[i] == false){
dfs(i, vis, adj, dfsStore);
}
}
return dfsStore;
}
public void dfs(int node, boolean vis[], ArrayList<ArrayList<Integer>> adj, ArrayList<Integer> dfsStore){
dfsStore.add(node);
vis[node] = true;
for(Integer i : adj.get(node)){
if(vis[i] == false){
dfs(i, vis, adj, dfsStore);
}
}
}
}
ANALYSIS :-
Time Complexity :- BigO(N+E) Where N is the time taken for visiting N nodes and E is for travelling through adjacent nodes.
Space Complexity :- BigO(N+E) + O(N) + O(N) where Space for adjacency list, Array,Auxiliary space.
# BFS
// { Driver Code Starts
// Initial Template for Java
import java.util.*;
import java.lang.*;
import java.io.*;
class GFG {
public static void main(String[] args) throws IOException {
BufferedReader br =
new BufferedReader(new InputStreamReader(System.in));
int T = Integer.parseInt(br.readLine().trim());
while (T-- > 0) {
String[] s = br.readLine().trim().split(" ");
int V = Integer.parseInt(s[0]);
int E = Integer.parseInt(s[1]);
ArrayList<ArrayList<Integer>> adj = new ArrayList<>();
for (int i = 0; i < V; i++) adj.add(i, new ArrayList<Integer>());
for (int i = 0; i < E; i++) {
String[] S = br.readLine().trim().split(" ");
int u = Integer.parseInt(S[0]);
int v = Integer.parseInt(S[1]);
adj.get(u).add(v);
// adj.get(v).add(u);
}
Solution obj = new Solution();
ArrayList<Integer> ans = obj.bfsOfGraph(V, adj);
for (int i = 0; i < ans.size(); i++)
System.out.print(ans.get(i) + " ");
System.out.println();
}
}
}
// } Driver Code Ends
class Solution {
// Function to return Breadth First Traversal of given graph.
public ArrayList<Integer> bfsOfGraph(int V, ArrayList<ArrayList<Integer>> adj) {
// Code here
ArrayList<Integer> bfs = new ArrayList<>();
boolean vis[] = new boolean[V + 1];
Queue<Integer> q = new LinkedList<>();
q.add(0);
vis[0] = true;
while(!q.isEmpty()){
Integer node = q.poll();
bfs.add(node);
for(Integer it : adj.get(node)){
if(vis[it] == false){
q.add(it);
vis[it] = true;
}
}
}
return bfs;
}
}
ANALYSIS :-
Time Complexity :- BigO(N+E) where N = Nodes , E = travelling through adjacent nodes
Space Complexity :- BigO(N+E) + O(N) + O(N) where Space for adjacency list, visited array, queue data structure
# Detect A Cycle In Undirected Graph {B F S}
Intuition: The intuition behind this is to check for the visited element if it is found again, this means the cycle is present in the given undirected graph.
for(i= 1->N)
{
if(!vis[i])
if(cyclebfs(i)) // if cycle is found , we return true
Return True;
}
Approach:
For the first component, firstly we insert the first element of the graph by marking it as visited in the Queue having prev of the first element as -1. Now we pop out that element and traverse the adjacent element list for that and then insert the elements in the Queue and continue the process until no adjacent element is found for the present element. Here, we can see that no loop is formed. So, we return false for the first component.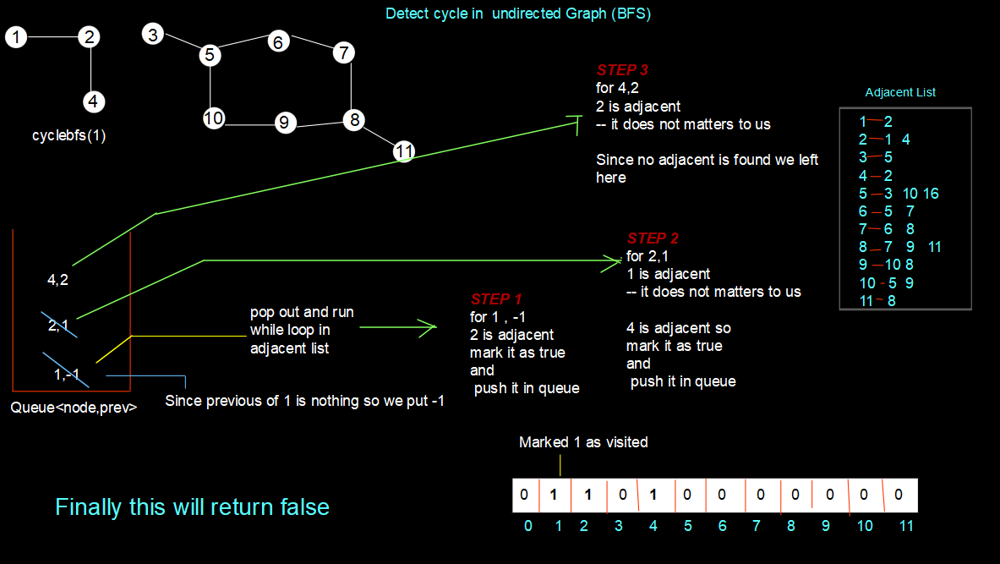
For the second component, a similar process will be done as we have done for the first component. Here we will be able to see that when we come to 7, 8 is one of the next adjacent ones which matters to us, and also, it is already marked as positive. This means someone is linked already with this element. So, it forms a loop and we return true finally.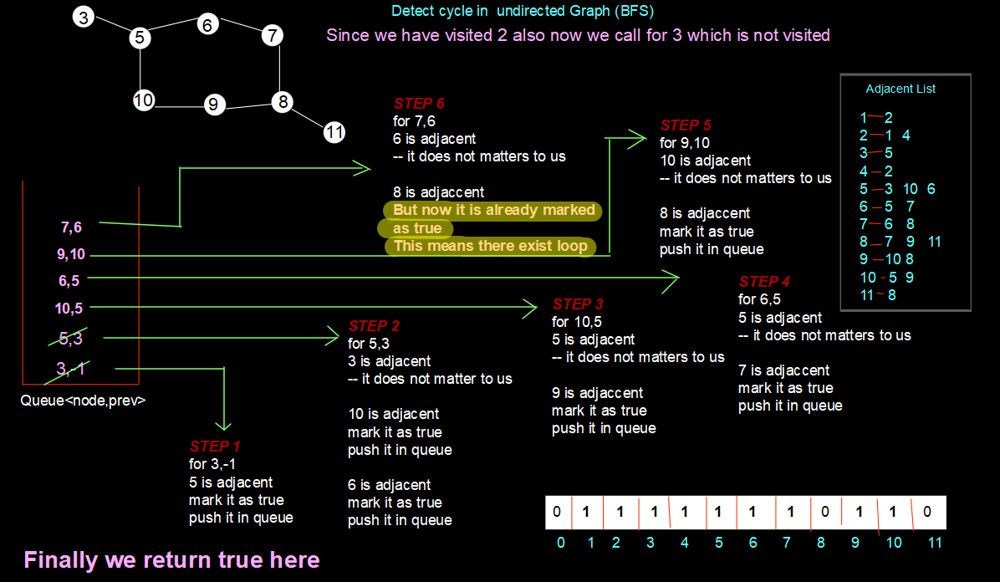
import java.util.*;
import java.lang.*;
import java.io.*;
class GFG
{
public static void main(String[] args) throws IOException
{
int V = 5;
ArrayList<ArrayList<Integer>>adj = new ArrayList<>();
for(int i = 0; i < V; i++)
adj.add(i, new ArrayList<Integer>());
adj.get(0).add(1);
adj.get(0).add(2);
adj.get(2).add(3);
adj.get(1).add(3);
adj.get(2).add(4);
Solution obj = new Solution();
boolean ans = obj.isCycle(V, adj);
if(ans)
System.out.println("Yes");
else
System.out.println("No");
}
}
class Node {
int first;
int second;
public Node(int first, int second) {
this.first = first;
this.second = second;
}
}
class Solution
{
static boolean checkForCycle(ArrayList<ArrayList<Integer>> adj, int s,
boolean vis[])
{
Queue<Node> q = new LinkedList<>(); //BFS
q.add(new Node(s, -1));
vis[s] =true;
while(!q.isEmpty())
{
int node = q.peek().first;
int par = q.peek().second;
q.remove();
for(Integer it: adj.get(node))
{
if(vis[it]==false)
{
q.add(new Node(it, node));
vis[it] = true;
}
else if(par != it) return true;
}
}
return false;
}
public boolean isCycle(int V, ArrayList<ArrayList<Integer>> adj)
{
boolean vis[] = new boolean[V];
Arrays.fill(vis,false);
for(int i=0;i<V;i++)
if(vis[i]==false)
if(checkForCycle(adj, i,vis))
return true;
return false;
}
}
Output:
Yes
Time Complexity: O(N+E), N is the time taken and E is for traveling through adjacent nodes overall.
Space Complexity: O(N+E) + O(N) + O(N) , space for adjacent list , array and queue
took reference from striver sde sheet
Approach: Run a for loop from the first node to the last node and check if the node is visited. If it is not visited then call the function recursively which goes into the depth as known as DFS search and if you find a cycle you can say that there is a cycle in the graph.
Basically calling the isCyclic function with number of nodes and passing the graph
Traversing from 1 to number of nodes and checking for every node if it is unvisited
If the node is unvisited then call a function checkForCycle, that checks if there is a cycle and returns true if there is a cycle.
Now the function checkForCycle has the node and previous of the parent node. It will also have the visited array and the graph that has adjacency list
Mark it as visited and then traverse for its adjacency list using a for loop.
Calling DFS traversal if that node is unvisited call recursive function that checks if its a cycle and returns true
If the previously visited node and it is not equal to the parent we can say there is cycle again and will return true
Now if you have traveled for all adjacent nodes and all the DSF have been called and it never returned true that means we have done the DSF call entirely and now we can return false, that mean there is no DSF cycle
import java.util.*;
class GFG {
public static void main(String[] args) {
int V = 5;
ArrayList < ArrayList < Integer >> adj = new ArrayList < > ();
for (int i = 0; i < V; i++) {
adj.add(new ArrayList < > ());
}
// edge 0---1
adj.get(0).add(1);
adj.get(1).add(0);
// edge 1---2
adj.get(1).add(2);
adj.get(2).add(1);
// adge 2--3
adj.get(2).add(3);
adj.get(3).add(2);
// adge 3--4
adj.get(3).add(4);
adj.get(4).add(3);
// adge 1--4
adj.get(1).add(4);
adj.get(4).add(1);
Solution obj = new Solution();
boolean ans = obj.isCycle(V, adj);
if (ans == true) {
System.out.println("Cycle Detected");
} else {
System.out.println("No Cycle Detected");
}
}
}
class Solution {
public boolean checkForCycle(int node, int parent, boolean vis[], ArrayList < ArrayList
< Integer >> adj) {
vis[node] = true;
for (Integer it: adj.get(node)) {
if (vis[it] == false) {
if (checkForCycle(it, node, vis, adj) == true)
return true;
} else if (it != parent)
return true;
}
return false;
}
// 0-based indexing Graph
public boolean isCycle(int V, ArrayList < ArrayList < Integer >> adj) {
boolean vis[] = new boolean[V];
for (int i = 0; i < V; i++) {
if (vis[i] == false) {
if (checkForCycle(i, -1, vis, adj))
return true;
}
}
return false;
}
}
Output:
Cycle Detected
Time Complexity: O(N+E), N is the time taken and E is for traveling through adjacent nodes overall.
Space Complexity: O(N)
In the above diagram, let us say we start DFS from node 2 and we visit the nodes: 0, 1, 3, 4 and 5 through the edges: 2->0, 0->1, 1->3, 3->4 and 4->5. These edges become the forward edges in our DFS traversal of the graph which eventually form a DFS tree considering the forward edges only whereas the edges which were not the part of our DFS i.e 0->3 and 3->5 become the back edges.
We will be using an array of visited vertices during the DFS traversal to check for back edges, so whenever we find an edge that goes back to a vertex already in the visited array, we return true as a result that the graph contains a cycle.
Algorithm for the solution
Take the number of edges and vertices as user input.
Use vertex visited array and parent node to create a recursive function.
Mark the current vertex as visited.
Make recursive calls for all the unvisited adjacent vertices for the current vertex, and if any of these recursive functions return true, return true as the final answer.
If any adjacent vertex is already in the visited array, mark the answer as true.
Return false if none of the above steps returns true.
Implementation of the solution
#include<bits/stdc++.h>
using namespace std;
//Class for the graph.
class graph
{
int v;
//Adjacency list.
list<int> *adjacencylist;
//Function to detectcycle.
bool checkcycle2(int v, bool vertvisited[], int parentnode);
public:
graph(int v);
void drawedge(int v, int u);
bool checkcycle();
};
//Constructor for a graph with v nodes.
graph::graph(int v)
{
this->v=v;
adjacencylist= new list<int>[v];
}
//To add edges in the graph.
void graph::drawedge(int v, int u)
{
adjacencylist[v].push_back(u);
adjacencylist[u].push_back(v);
}
//Function to keep track of visited nodes.
bool graph::checkcycle2(int v, bool vertvisited[], int parentnode)
{
//Marking the vertex as visited.
vertvisited[v]=true;
//Making recursive calls for the adjacent
//vertices and return true if any back edge is
//found.
list<int>::iterator itr;
for(itr=adjacencylist[v].begin();itr!=adjacencylist[v].end();++itr)
{
if (!vertvisited[*itr])
{
if(checkcycle2(*itr, vertvisited, v))
{
return true;
}
}
else if (*itr != parentnode)
{
return true;
}
}
return false;
}
bool graph::checkcycle()
{
//Declare and initialise the visited and recursion stack array as false.
bool *vertvisited=new bool[v];
for(int i=0;i<v;i++)
{
vertvisited[i]=false;
}
//Call the "checkcycle2" function for cycle
//detection.
for(int i=0;i<v;i++)
{
if(!vertvisited[i])
{
if(checkcycle2(i, vertvisited, -1))
{
return true;
}
}
}
return false;
}
//Driver function.
int main()
{
graph g(6);
g.drawedge(0, 1);
g.drawedge(1, 5);
g.drawedge(5, 4);
g.drawedge(4, 0);
g.drawedge(4, 3);
g.drawedge(3, 2);
g.drawedge(0, 2);
//Function call and print the result.
if(g.checkcycle())
cout << "Graph is cyclic";
else
cout << "Graph is acyclic";
return 0;
}
Output-
Graph is cyclic
Breadth-First Search (BFS):
import java.util.*;
public class BFS {
public void bfs(int[][] graph, int start) {
Queue<Integer> queue = new LinkedList<>();
boolean[] visited = new boolean[graph.length];
visited[start] = true;
queue.offer(start);
while (!queue.isEmpty()) {
int node = queue.poll();
System.out.print(node + " ");
for (int i = 0; i < graph.length; i++) {
if (graph[node][i] == 1 && !visited[i]) {
visited[i] = true;
queue.offer(i);
}
}
}
}
}
Depth-First Search (DFS):
import java.util.*;
public class DFS {
public void dfs(int[][] graph, int start) {
Stack<Integer> stack = new Stack<>();
boolean[] visited = new boolean[graph.length];
visited[start] = true;
stack.push(start);
while (!stack.isEmpty()) {
int node = stack.pop();
System.out.print(node + " ");
for (int i = 0; i < graph.length; i++) {
if (graph[node][i] == 1 && !visited[i]) {
visited[i] = true;
stack.push(i);
}
}
}
}
}
Dijkstra's Algorithm:
import java.util.*;
public class Dijkstra {
public void dijkstra(int[][] graph, int start) {
int[] dist = new int[graph.length];
boolean[] visited = new boolean[graph.length];
Arrays.fill(dist, Integer.MAX_VALUE);
dist[start] = 0;
for (int i = 0; i < graph.length - 1; i++) {
int u = minDistance(dist, visited);
visited[u] = true;
for (int v = 0; v < graph.length; v++) {
if (!visited[v] && graph[u][v] != 0 && dist[u] != Integer.MAX_VALUE && dist[u] + graph[u][v] < dist[v]) {
dist[v] = dist[u] + graph[u][v];
}
}
}
printDistances(dist);
}
private int minDistance(int[] dist, boolean[] visited) {
int min = Integer.MAX_VALUE;
int minIndex = -1;
for (int i = 0; i < dist.length; i++) {
if (!visited[i] && dist[i] <= min) {
min = dist[i];
minIndex = i;
}
}
return minIndex;
}
private void printDistances(int[] dist) {
System.out.println("Vertex \t Distance from Source");
for (int i = 0; i < dist.length; i++) {
System.out.println(i + " \t " + dist[i]);
}
}
}
Bellman-Ford Algorithm:
import java.util.*;
public class BellmanFord {
public void bellmanFord(int[][] graph, int start) {
int[] dist = new int[graph.length];
Arrays.fill(dist, Integer.MAX_VALUE);
dist[start] = 0;
for (int i = 0; i < graph.length - 1; i++) {
for (int u = 0; u < graph.length; u++) {
for (int v = 0; v < graph.length; v++) {
if (graph[u][v] != 0 && dist[u] != Integer.MAX_VALUE && dist[u] + graph[u][v] < dist[v]) {
dist[v] = dist[u] + graph[u][v];
}
}
}
}
printDistances(dist);
}
private void printDistances(int[] dist) {
System.out.println("Vertex \t Distance from Source");
for (int i = 0; i < dist.length; i++) {
System.out.println(i + " \t " + dist[i]);
}
}
}
Minimum Spanning Tree (MST):
Prim's Algorithm:
import java.util.*;
public class Prim {
public void prim(int[][] graph) {
int[] parent = new int[graph.length];
int[] key = new int[graph.length];
boolean[] mstSet = new boolean[graph.length];
Arrays.fill(key, Integer.MAX_VALUE);
key[0] = 0;
parent[0] = -1;
for (int i = 0; i < graph.length - 1; i++) {
int u = minKey(key, mstSet);
mstSet[u] = true;
for (int v = 0; v < graph.length; v++) {
if (graph[u][v] != 0 && !mstSet[v] && graph[u][v] < key[v]) {
parent[v] = u;
key[v] = graph[u][v];
}
}
}
printMST(parent, graph);
}
private int minKey(int[] key, boolean[] mstSet) {
int min = Integer.MAX_VALUE;
int minIndex = -1;
for (int i = 0; i < key.length; i++) {
if (!mstSet[i] && key[i] < min) {
min = key[i];
minIndex = i;
}
}
return minIndex;
}
private void printMST(int[] parent, int[][] graph) {
System.out.println("Edge \t Weight");
for (int i = 1; i < graph.length; i++) {
System.out.println(parent[i] + " - " + i + " \t " + graph[i][parent[i]]);
}
}
}
Kruskal's Algorithm:
import java.util.*;
public class Kruskal {
class Edge implements Comparable<Edge> {
int src, dest, weight;
public int compareTo(Edge other) {
return this.weight - other.weight;
}
}
public void kruskal(int[][] graph) {
int V = graph.length;
Edge[] edges = new Edge[V * V];
int index = 0;
for (int i = 0; i < V; i++) {
for (int j = 0; j < V; j++) {
if (graph[i][j] != 0) {
Edge edge = new Edge();
edge.src = i;
edge.dest = j;
edge.weight = graph[i][j];
edges[index++] = edge;
}
}
}
Edge[] result = new Edge[V];
Arrays.sort(edges);
int[] parent = new int[V];
for (int i = 0; i < V; i++) {
parent[i] = i;
}
int e = 0;
int i = 0;
while (e < V - 1) {
Edge nextEdge = edges[i++];
int x = find(parent, nextEdge.src);
int y = find(parent, nextEdge.dest);
if (x != y) {
result[e++] = nextEdge;
parent[x] = y;
}
}
printMST(result);
}
private int find(int[] parent, int i) {
if (parent[i] == i) {
return i;
}
return find(parent, parent[i]);
}
private void printMST(Edge[] result) {
System.out.println("Edge \t Weight");
for (int i = 0; i < result.length; i++) {
System.out.println(result[i].src + " - " + result[i].dest + " \t " + result[i].weight);
}
}
}
Floyd-Warshall Algorithm:
The Floyd-Warshall algorithm is used to find the shortest path between all pairs of vertices in a weighted graph. Here's an example implementation in Java:
public class FloydWarshall {
public void shortestPath(int[][] graph) {
int V = graph.length;
int[][] dist = new int[V][V];
for (int i = 0; i < V; i++) {
for (int j = 0; j < V; j++) {
dist[i][j] = graph[i][j];
}
}
for (int k = 0; k < V; k++) {
for (int i = 0; i < V; i++) {
for (int j = 0; j < V; j++) {
if (dist[i][k] + dist[k][j] < dist[i][j]) {
dist[i][j] = dist[i][k] + dist[k][j];
}
}
}
}
printSolution(dist);
}
private void printSolution(int[][] dist) {
System.out.println("Shortest distances between every pair of vertices:");
for (int i = 0; i < dist.length; i++) {
for (int j = 0; j < dist.length; j++) {
if (dist[i][j] == Integer.MAX_VALUE) {
System.out.print("INF ");
} else {
System.out.print(dist[i][j] + " ");
}
}
System.out.println();
}
}
}
Prim's Algorithm:
Prim's algorithm is used to find the minimum spanning tree of a weighted undirected graph. Here's an example implementation in Java:
public class PrimsAlgorithm {
public void minimumSpanningTree(int[][] graph) {
int V = graph.length;
int[] parent = new int[V];
int[] key = new int[V];
boolean[] mstSet = new boolean[V];
for (int i = 0; i < V; i++) {
key[i] = Integer.MAX_VALUE;
mstSet[i] = false;
}
key[0] = 0;
parent[0] = -1;
for (int count = 0; count < V - 1; count++) {
int u = minKey(key, mstSet);
mstSet[u] = true;
for (int v = 0; v < V; v++) {
if (graph[u][v] != 0 && !mstSet[v] && graph[u][v] < key[v]) {
parent[v] = u;
key[v] = graph[u][v];
}
}
}
printMST(parent, graph);
}
private int minKey(int[] key, boolean[] mstSet) {
int min = Integer.MAX_VALUE;
int minIndex = -1;
for (int i = 0; i < key.length; i++) {
if (!mstSet[i] && key[i] < min) {
min = key[i];
minIndex = i;
}
}
return minIndex;
}
private void printMST(int[] parent, int[][] graph) {
System.out.println("Edge \t Weight");
for (int i = 1; i < graph.length; i++) {
System.out.println(parent[i] + " - " + i + " \t " + graph[i][parent[i]]);
}
}
}
Kruskal's Algorithm:
Kruskal's algorithm is also used to find the minimum spanning tree of a weighted undirected graph. Here's an example implementation in Java:
public class KruskalsAlgorithm {
class Edge implements Comparable<Edge> {
int src, dest, weight;
public int compareTo(Edge other) {
return this.weight - other.weight;
}
}
public void minimumSpanningTree(int[][] graph) {
int V = graph.length;
Edge[] edges = new Edge[V * V];
int index = 0;
for (int i = 0; i < V; i++) {
for (int j = 0; j < V; j++) {
if (graph[i][j] != 0) {
Edge edge = new Edge();
edge.src = i;
edge.dest = j;
edge.weight = graph[i][j];
edges[index++] = edge;
}
}
}
Edge[] result = new Edge[V];
Arrays.sort(edges);
int[] parent = new int[V];
for (int i = 0; i < V; i++) {
parent[i] = i;
}
int e = 0;
for (int i = 0; i < edges.length && e < V - 1; i++) {
Edge edge = edges[i];
int x = find(parent, edge.src);
int y = find(parent, edge.dest);
if (x != y) {
result[e++] = edge;
parent[x] = y;
}
}
printMST(result);
}
private int find(int[] parent, int i) {
if (parent[i] == i) {
return i;
}
return find(parent, parent[i]);
}
private void printMST(Edge[] result) {
System.out.println("Edge \t Weight");
for (int i = 0; i < result.length; i++) {
System.out.println(result[i].src + " - " + result[i].dest + " \t " + result[i].weight);
}
}
}
Topological Sort:
import java.util.*;
public class TopologicalSort {
public int[] sort(int[][] graph) {
int V = graph.length;
int[] inDegree = new int[V];
for (int i = 0; i < V; i++) {
for (int j = 0; j < V; j++) {
if (graph[i][j] != 0) {
inDegree[j]++;
}
}
}
Queue<Integer> queue = new LinkedList<>();
for (int i = 0; i < V; i++) {
if (inDegree[i] == 0) {
queue.offer(i);
}
}
int[] result = new int[V];
int index = 0;
while (!queue.isEmpty()) {
int node = queue.poll();
result[index++] = node;
for (int i = 0; i < V; i++) {
if (graph[node][i] != 0) {
inDegree[i]--;
if (inDegree[i] == 0) {
queue.offer(i);
}
}
}
}
return result;
}
}
Strongly Connected Components (SCC):
import java.util.*;
public class SCC {
private int V;
private List<Integer>[] graph;
private List<Integer>[] reverseGraph;
private boolean[] visited;
private Stack<Integer> stack;
public SCC(int V) {
this.V = V;
graph = new ArrayList[V];
reverseGraph = new ArrayList[V];
for (int i = 0; i < V; i++) {
graph[i] = new ArrayList<>();
reverseGraph[i] = new ArrayList<>();
}
visited = new boolean[V];
stack = new Stack<>();
}
public void addEdge(int u, int v) {
graph[u].add(v);
reverseGraph[v].add(u);
}
public List<List<Integer>> getSCCs() {
List<List<Integer>> result = new ArrayList<>();
for (int i = 0; i < V; i++) {
if (!visited[i]) {
dfs(i);
}
}
visited = new boolean[V];
while (!stack.isEmpty()) {
int node = stack.pop();
if (!visited[node]) {
List<Integer> scc = new ArrayList<>();
reverseDfs(node, scc);
result.add(scc);
}
}
return result;
}
private void dfs(int node) {
visited[node] = true;
for (int neighbor : graph[node]) {
if (!visited[neighbor]) {
dfs(neighbor);
}
}
stack.push(node);
}
private void reverseDfs(int node, List<Integer> scc) {
visited[node] = true;
scc.add(node);
for (int neighbor : reverseGraph[node]) {
if (!visited[neighbor]) {
reverseDfs(neighbor, scc);
}
}
}
}
here are some common ways to use segment trees to solve problems:
Range Sum Queries:
A segment tree can be used to efficiently answer range sum queries on an array. The tree is built by recursively dividing the array into two halves and storing the sum of each segment in the corresponding node of the tree. To answer a range sum query, we traverse the tree and add up the sums of the segments that overlap with the query range.
Range Minimum Queries:
A segment tree can also be used to efficiently answer range minimum queries on an array. The tree is built by recursively dividing the array into two halves and storing the minimum value of each segment in the corresponding node of the tree. To answer a range minimum query, we traverse the tree and find the minimum value of the segments that overlap with the query range.
Lazy Propagation:
Lazy propagation is a technique used to update a segment tree efficiently when there are many updates to be made. Instead of updating all the nodes in the tree, we only update the nodes that are affected by the update and mark the other nodes as "lazy". When we need to query the tree, we first propagate the lazy updates to the affected nodes and then traverse the tree as usual.
Range Updates:
A segment tree can be used to efficiently update a range of values in an array. The tree is built by recursively dividing the array into two halves and storing the sum of each segment in the corresponding node of the tree. To update a range of values, we traverse the tree and update the nodes that overlap with the range.
Range Queries on Trees:
A segment tree can be used to efficiently answer range queries on trees. The tree is built by recursively dividing the tree into subtrees and storing the sum of each subtree in the corresponding node of the tree. To answer a range query on the tree, we traverse the tree and add up the sums of the subtrees that overlap with the query range.
Persistent Segment Trees:
A persistent segment tree is a data structure that allows us to efficiently store and query multiple versions of a segment tree. Instead of modifying the original tree, we create a new tree for each update and link it to the previous tree. This allows us to query any version of the tree without affecting the other versions.
Range Sum Queries:
public class SegmentTree {
private int[] tree;
private int n;
public SegmentTree(int[] nums) {
n = nums.length;
tree = new int[2 * n];
buildTree(nums);
}
private void buildTree(int[] nums) {
for (int i = n; i < 2 * n; i++) {
tree[i] = nums[i - n];
}
for (int i = n - 1; i > 0; i--) {
tree[i] = tree[2 * i] + tree[2 * i + 1];
}
}
public void update(int index, int val) {
index += n;
tree[index] = val;
while (index > 0) {
int left = index;
int right = index;
if (index % 2 == 0) {
right = index + 1;
} else {
left = index - 1;
}
tree[index / 2] = tree[left] + tree[right];
index /= 2;
}
}
public int sumRange(int left, int right) {
left += n;
right += n;
int sum = 0;
while (left <= right) {
if (left % 2 == 1) {
sum += tree[left];
left++;
}
if (right % 2 == 0) {
sum += tree[right];
right--;
}
left /= 2;
right /= 2;
}
return sum;
}
}
Range Minimum Queries:
public class SegmentTree {
private int[] tree;
private int n;
public SegmentTree(int[] nums) {
n = nums.length;
tree = new int[2 * n];
buildTree(nums);
}
private void buildTree(int[] nums) {
for (int i = n; i < 2 * n; i++) {
tree[i] = nums[i - n];
}
for (int i = n - 1; i > 0; i--) {
tree[i] = Math.min(tree[2 * i], tree[2 * i + 1]);
}
}
public void update(int index, int val) {
index += n;
tree[index] = val;
while (index > 0) {
int left = index;
int right = index;
if (index % 2 == 0) {
right = index + 1;
} else {
left = index - 1;
}
tree[index / 2] = Math.min(tree[left], tree[right]);
index /= 2;
}
}
public int minRange(int left, int right) {
left += n;
right += n;
int min = Integer.MAX_VALUE;
while (left <= right) {
if (left % 2 == 1) {
min = Math.min(min, tree[left]);
left++;
}
if (right % 2 == 0) {
min = Math.min(min, tree[right]);
right--;
}
left /= 2;
right /= 2;
}
return min;
}
}
here's the complete code for lazy propagation:
public class SegmentTree {
private int[] tree;
private int[] lazy;
private int n;
public SegmentTree(int[] nums) {
n = nums.length;
tree = new int[4 * n];
lazy = new int[4 * n];
buildTree(nums, 1, 0, n - 1);
}
private void buildTree(int[] nums, int index, int left, int right) {
if (left == right) {
tree[index] = nums[left];
return;
}
int mid = (left + right) / 2;
buildTree(nums, 2 * index, left, mid);
buildTree(nums, 2 * index + 1, mid + 1, right);
tree[index] = tree[2 * index] + tree[2 * index + 1];
}
public void update(int left, int right, int val) {
update(1, 0, n - 1, left, right, val);
}
private void update(int index, int left, int right, int rangeLeft, int rangeRight, int val) {
if (lazy[index] != 0) {
tree[index] += lazy[index] * (right - left + 1);
if (left != right) {
lazy[2 * index] += lazy[index];
lazy[2 * index + 1] += lazy[index];
}
lazy[index] = 0;
}
if (left > rangeRight || right < rangeLeft) {
return;
}
if (left >= rangeLeft && right <= rangeRight) {
tree[index] += val * (right - left + 1);
if (left != right) {
lazy[2 * index] += val;
lazy[2 * index + 1] += val;
}
return;
}
int mid = (left + right) / 2;
update(2 * index, left, mid, rangeLeft, rangeRight, val);
update(2 * index + 1, mid + 1, right, rangeLeft, rangeRight, val);
tree[index] = tree[2 * index] + tree[2 * index + 1];
}
public int sumRange(int left, int right) {
return sumRange(1, 0, n - 1, left, right);
}
private int sumRange(int index, int left, int right, int rangeLeft, int rangeRight) {
if (lazy[index] != 0) {
tree[index] += lazy[index] * (right - left + 1);
if (left != right) {
lazy[2 * index] += lazy[index];
lazy[2 * index + 1] += lazy[index];
}
lazy[index] = 0;
}
if (left > rangeRight || right < rangeLeft) {
return 0;
}
if (left >= rangeLeft && right <= rangeRight) {
return tree[index];
}
int mid = (left + right) / 2;
int leftSum = sumRange(2 * index, left, mid, rangeLeft, rangeRight);
int rightSum = sumRange(2 * index + 1, mid + 1, right, rangeLeft, rangeRight);
return leftSum + rightSum;
}
}
here's the complete code for range updates:
public class SegmentTree {
private int[] tree;
private int n;
public SegmentTree(int[] nums) {
n = nums.length;
tree = new int[4 * n];
buildTree(nums, 1, 0, n - 1);
}
private void buildTree(int[] nums, int index, int left, int right) {
if (left == right) {
tree[index] = nums[left];
return;
}
int mid = (left + right) / 2;
buildTree(nums, 2 * index, left, mid);
buildTree(nums, 2 * index + 1, mid + 1, right);
tree[index] = tree[2 * index] + tree[2 * index + 1];
}
public void update(int left, int right, int val) {
update(1, 0, n - 1, left, right, val);
}
private void update(int index, int left, int right, int rangeLeft, int rangeRight, int val) {
if (left > rangeRight || right < rangeLeft) {
return;
}
if (left >= rangeLeft && right <= rangeRight) {
tree[index] += val * (right - left + 1);
if (left != right) {
update(2 * index, left, (left + right) / 2, rangeLeft, rangeRight, val);
update(2 * index + 1, (left + right) / 2 + 1, right, rangeLeft, rangeRight, val);
}
return;
}
update(2 * index, left, (left + right) / 2, rangeLeft, rangeRight, val);
update(2 * index + 1, (left + right) / 2 + 1, right, rangeLeft, rangeRight, val);
tree[index] = tree[2 * index] + tree[2 * index + 1];
}
public int sumRange(int left, int right) {
return sumRange(1, 0, n - 1, left, right);
}
private int sumRange(int index, int left, int right, int rangeLeft, int rangeRight) {
if (left > rangeRight || right < rangeLeft) {
return 0;
}
if (left >= rangeLeft && right <= rangeRight) {
return tree[index];
}
int mid = (left + right) / 2;
int leftSum = sumRange(2 * index, left, mid, rangeLeft, rangeRight);
int rightSum = sumRange(2 * index + 1, mid + 1, right, rangeLeft, rangeRight);
return leftSum + rightSum;
}
}
here's the complete code for range queries on trees:
public class SegmentTree {
private List<Integer>[] tree;
private int[] start;
private int[] end;
private int[] treeIndex;
private int[] flatTree;
private int index;
public SegmentTree(List<Integer>[] tree) {
int n = tree.length;
this.tree = tree;
start = new int[n];
end = new int[n];
treeIndex = new int[n];
flatTree = new int[4 * n];
index = 0;
dfs(0, -1);
buildTree(1, 0, n - 1);
}
private void dfs(int node, int parent) {
start[node] = index;
treeIndex[index] = node;
index++;
for (int neighbor : tree[node]) {
if (neighbor != parent) {
dfs(neighbor, node);
}
}
end[node] = index - 1;
}
private void buildTree(int index, int left, int right) {
if (left == right) {
flatTree[index] = treeIndex[left];
return;
}
int mid = (left + right) / 2;
buildTree(2 * index, left, mid);
buildTree(2 * index + 1, mid + 1, right);
int leftNode = flatTree[2 * index];
int rightNode = flatTree[2 * index + 1];
flatTree[index] = (start[leftNode] < start[rightNode]) ? leftNode : rightNode;
}
public int query(int left, int right) {
int nodeIndex = query(1, 0, tree.length - 1, left, right);
return treeIndex[nodeIndex];
}
private int query(int index, int left, int right, int rangeLeft, int rangeRight) {
if (left > rangeRight || right < rangeLeft) {
return -1;
}
if (left >= rangeLeft && right <= rangeRight) {
return flatTree[index];
}
int mid = (left + right) / 2;
int leftNode = query(2 * index, left, mid, rangeLeft, rangeRight);
int rightNode = query(2 * index + 1, mid + 1, right, rangeLeft, rangeRight);
if (leftNode == -1) {
return rightNode;
}
if (rightNode == -1) {
return leftNode;
}
return (start[leftNode] < start[rightNode]) ? leftNode : rightNode;
}
}
Persistent Segment Tree for Range Sum Queries:
public class PersistentSegmentTree {
private Node[] versions;
private int versionCount;
public PersistentSegmentTree(int[] nums) {
int n = nums.length;
versions = new Node[4 * n * (int) Math.ceil(Math.log(n) / Math.log(2))];
versionCount = 0;
buildTree(nums, 0, n - 1, 0);
}
private void buildTree(int[] nums, int left, int right, int index) {
versions[index] = new Node();
if (left == right) {
versions[index].sum = nums[left];
return;
}
int mid = (left + right) / 2;
buildTree(nums, left, mid, 2 * index + 1);
buildTree(nums, mid + 1, right, 2 * index + 2);
versions[index].sum = versions[2 * index + 1].sum + versions[2 * index + 2].sum;
}
public int query(int version, int left, int right) {
return query(version, 0, versions.length / 4 - 1, left, right, 0);
}
private int query(int version, int left, int right, int rangeLeft, int rangeRight, int index) {
if (left > rangeRight || right < rangeLeft) {
return 0;
}
if (left >= rangeLeft && right <= rangeRight) {
return versions[version].sum - versions[index].sum;
}
int mid = (left + right) / 2;
int leftSum = query(version, left, mid, rangeLeft, rangeRight, 2 * index + 1);
int rightSum = query(version, mid + 1, right, rangeLeft, rangeRight, 2 * index + 2);
return leftSum + rightSum;
}
public int update(int version, int index, int val) {
versions = Arrays.copyOf(versions, versions.length + 1);
versionCount++;
update(version, 0, versions.length / 4 - 1, index, val, versionCount - 1);
return versionCount - 1;
}
private void update(int version, int left, int right, int index, int val, int newVersion) {
versions[newVersion] = new Node();
if (left == right) {
versions[newVersion].sum = val;
return;
}
int mid = (left + right) / 2;
if (index <= mid) {
versions[newVersion].right = versions[version].right;
update(versions[version].left, left, mid, index, val, versions[newVersion].left = versionCount);
} else {
versions[newVersion].left = versions[version].left;
update(versions[version].right, mid + 1, right, index, val, versions[newVersion].right = versionCount);
}
versions[newVersion].sum = versions[versions[newVersion].left].sum + versions[versions[newVersion].right].sum;
}
private static class Node {
int sum;
int left;
int right;
public Node() {
sum = 0;
left = -1;
right = -1;
}
}
}
Example usage:
int[] nums = {1, 3, 5, 7, 9};
PersistentSegmentTree pst = new PersistentSegmentTree(nums);
int version1 = 0;
int version2 = pst.update(version1, 2, 6);
int version3 = pst.update(version2, 3, 8);
System.out.println(pst.query(version1, 1, 3)); // Output: 8
System.out.println(pst.query(version2, 1, 3)); // Output: 11
System.out.println(pst.query(version3, 1, 3)); // Output: 13
M coloring
public boolean graphColoring(boolean graph[][], int m, int n) {
int col[] = new int[n];
if(solve(0,graph,m,n,col)) return true;
return false;
}
boolean solve(int node,boolean G[][],int m,int n,int[] col){
if(node==n)return true;
for(int c=1;c<=m;c++){// check all colors
if(safe(node,G,c,col,n)){//check is safe
col[node]=c;
if(solve(node+1,G,m,n,col)) return true;
col[node]=0;
}
}return false;
}
boolean safe(int node,boolean G[][],int c,int col[],int n){
for(int k=0;k<n;k++){
if(k!=node && G[k][node] && col[k]==c) return false;
}return true;
}
# sudoko
static boolean SolveSudoku(int grid[][])
{
// add your code here
return solve(grid);
}
static boolean solve(int grid[][]){
int n=grid.length;
for(int i=0;i<n;i++){
for(int j=0;j<n;j++){
if(grid[i][j]==0){
for(int k=1;k<=n;k++){
if(isSafe(grid,k,n,i,j)){
grid[i][j]=k;
if(solve(grid))return true;
else grid[i][j]=0;//wrong choise
}
}return false;//we can't placed key
}
}
}return true;
}
static boolean isSafe(int grid[][],int k,int n,int row,int col){
for(int i=0;i<n;i++){
if(grid[i][col]==k) return false;
if(grid[row][i]==k) return false;
if(grid[3*(row/3)+i/3][3*(col/3)+i%3]==k) return false;
}return true;
}
//Function to print grids of the Sudoku.
static void printGrid (int grid[][])
{
int n=grid.length;
// add your code here
for(int i=0;i<n;i++){
for(int j=0;j<n;j++){
System.out.print(grid[i][j]+" ");
}
}
}
# POWER SET
public List<String> AllPossibleStrings(String s)
{
// Code here
List<String> ans = new ArrayList<>();
for(int i=0;i<(1<<s.length());i++){//0 to 2^8-1
StringBuilder sb = new StringBuilder();
for(int j=0;j<s.length();j++){//0 to len(s)
if((i&(1<<j))!=0)sb.append(s.charAt(j));//
}
if(sb.length()>0)//check for empty str
ans.add(sb.toString());
}
Collections.sort(ans);
return ans;
}
This structure might apply to many other backtracking questions, but here I am just going to demonstrate Subsets, Permutations, and Combination Sum.
Subsets : https://leetcode.com/problems/subsets/
public List<List<Integer>> subsets(int[] nums) {
List<List<Integer>> list = new ArrayList<>();
Arrays.sort(nums);
backtrack(list, new ArrayList<>(), nums, 0);
return list;
}
private void backtrack(List<List<Integer>> list , List<Integer> tempList, int [] nums, int start){
list.add(new ArrayList<>(tempList));
for(int i = start; i < nums.length; i++){
tempList.add(nums[i]);
backtrack(list, tempList, nums, i + 1);
tempList.remove(tempList.size() - 1);
}
}
Subsets II (contains duplicates) : https://leetcode.com/problems/subsets-ii/
public List<List<Integer>> subsetsWithDup(int[] nums) {
List<List<Integer>> list = new ArrayList<>();
Arrays.sort(nums);
backtrack(list, new ArrayList<>(), nums, 0);
return list;
}
private void backtrack(List<List<Integer>> list, List<Integer> tempList, int [] nums, int start){
list.add(new ArrayList<>(tempList));
for(int i = start; i < nums.length; i++){
if(i > start && nums[i] == nums[i-1]) continue; // skip duplicates
tempList.add(nums[i]);
backtrack(list, tempList, nums, i + 1);
tempList.remove(tempList.size() - 1);
}
}
Permutations : https://leetcode.com/problems/permutations/
public List<List<Integer>> permute(int[] nums) {
List<List<Integer>> list = new ArrayList<>();
// Arrays.sort(nums); // not necessary
backtrack(list, new ArrayList<>(), nums);
return list;
}
private void backtrack(List<List<Integer>> list, List<Integer> tempList, int [] nums){
if(tempList.size() == nums.length){
list.add(new ArrayList<>(tempList));
} else{
for(int i = 0; i < nums.length; i++){
if(tempList.contains(nums[i])) continue; // element already exists, skip
tempList.add(nums[i]);
backtrack(list, tempList, nums);
tempList.remove(tempList.size() - 1);
}
}
}
Permutations II (contains duplicates) : https://leetcode.com/problems/permutations-ii/
public List<List<Integer>> permuteUnique(int[] nums) {
List<List<Integer>> list = new ArrayList<>();
Arrays.sort(nums);
backtrack(list, new ArrayList<>(), nums, new boolean[nums.length]);
return list;
}
private void backtrack(List<List<Integer>> list, List<Integer> tempList, int [] nums, boolean [] used){
if(tempList.size() == nums.length){
list.add(new ArrayList<>(tempList));
} else{
for(int i = 0; i < nums.length; i++){
if(used[i] || i > 0 && nums[i] == nums[i-1] && !used[i - 1]) continue;
used[i] = true;
tempList.add(nums[i]);
backtrack(list, tempList, nums, used);
used[i] = false;
tempList.remove(tempList.size() - 1);
}
}
}
Combination Sum : https://leetcode.com/problems/combination-sum/
public List<List<Integer>> combinationSum(int[] nums, int target) {
List<List<Integer>> list = new ArrayList<>();
Arrays.sort(nums);
backtrack(list, new ArrayList<>(), nums, target, 0);
return list;
}
private void backtrack(List<List<Integer>> list, List<Integer> tempList, int [] nums, int remain, int start){
if(remain < 0) return;
else if(remain == 0) list.add(new ArrayList<>(tempList));
else{
for(int i = start; i < nums.length; i++){
tempList.add(nums[i]);
backtrack(list, tempList, nums, remain - nums[i], i); // not i + 1 because we can reuse same elements
tempList.remove(tempList.size() - 1);
}
}
}
Combination Sum II (can't reuse same element) : https://leetcode.com/problems/combination-sum-ii/
public List<List<Integer>> combinationSum2(int[] nums, int target) {
List<List<Integer>> list = new ArrayList<>();
Arrays.sort(nums);
backtrack(list, new ArrayList<>(), nums, target, 0);
return list;
}
private void backtrack(List<List<Integer>> list, List<Integer> tempList, int [] nums, int remain, int start){
if(remain < 0) return;
else if(remain == 0) list.add(new ArrayList<>(tempList));
else{
for(int i = start; i < nums.length; i++){
if(i > start && nums[i] == nums[i-1]) continue; // skip duplicates
tempList.add(nums[i]);
backtrack(list, tempList, nums, remain - nums[i], i + 1);
tempList.remove(tempList.size() - 1);
}
}
}
Palindrome Partitioning : https://leetcode.com/problems/palindrome-partitioning/
public List<List<String>> partition(String s) {
List<List<String>> list = new ArrayList<>();
backtrack(list, new ArrayList<>(), s, 0);
return list;
}
public void backtrack(List<List<String>> list, List<String> tempList, String s, int start){
if(start == s.length())
list.add(new ArrayList<>(tempList));
else{
for(int i = start; i < s.length(); i++){
if(isPalindrome(s, start, i)){
tempList.add(s.substring(start, i + 1));
backtrack(list, tempList, s, i + 1);
tempList.remove(tempList.size() - 1);
}
}
}
}
public boolean isPalindrome(String s, int low, int high){
while(low < high)
if(s.charAt(low++) != s.charAt(high--)) return false;
return true;
}
This structure might apply to many other backtracking questions, but here I am just going to demonstrate Subsets, Permutations, and Combination Sum.
Subsets : https://leetcode.com/problems/subsets/
public List<List<Integer>> subsets(int[] nums) {
List<List<Integer>> list = new ArrayList<>();
Arrays.sort(nums);
backtrack(list, new ArrayList<>(), nums, 0);
return list;
}
private void backtrack(List<List<Integer>> list , List<Integer> tempList, int [] nums, int start){
list.add(new ArrayList<>(tempList));
for(int i = start; i < nums.length; i++){
tempList.add(nums[i]);
backtrack(list, tempList, nums, i + 1);
tempList.remove(tempList.size() - 1);
}
}
Subsets II (contains duplicates) : https://leetcode.com/problems/subsets-ii/
public List<List<Integer>> subsetsWithDup(int[] nums) {
List<List<Integer>> list = new ArrayList<>();
Arrays.sort(nums);
backtrack(list, new ArrayList<>(), nums, 0);
return list;
}
private void backtrack(List<List<Integer>> list, List<Integer> tempList, int [] nums, int start){
list.add(new ArrayList<>(tempList));
for(int i = start; i < nums.length; i++){
if(i > start && nums[i] == nums[i-1]) continue; // skip duplicates
tempList.add(nums[i]);
backtrack(list, tempList, nums, i + 1);
tempList.remove(tempList.size() - 1);
}
}
Permutations : https://leetcode.com/problems/permutations/
public List<List<Integer>> permute(int[] nums) {
List<List<Integer>> list = new ArrayList<>();
// Arrays.sort(nums); // not necessary
backtrack(list, new ArrayList<>(), nums);
return list;
}
private void backtrack(List<List<Integer>> list, List<Integer> tempList, int [] nums){
if(tempList.size() == nums.length){
list.add(new ArrayList<>(tempList));
} else{
for(int i = 0; i < nums.length; i++){
if(tempList.contains(nums[i])) continue; // element already exists, skip
tempList.add(nums[i]);
backtrack(list, tempList, nums);
tempList.remove(tempList.size() - 1);
}
}
}
Permutations II (contains duplicates) : https://leetcode.com/problems/permutations-ii/
public List<List<Integer>> permuteUnique(int[] nums) {
List<List<Integer>> list = new ArrayList<>();
Arrays.sort(nums);
backtrack(list, new ArrayList<>(), nums, new boolean[nums.length]);
return list;
}
private void backtrack(List<List<Integer>> list, List<Integer> tempList, int [] nums, boolean [] used){
if(tempList.size() == nums.length){
list.add(new ArrayList<>(tempList));
} else{
for(int i = 0; i < nums.length; i++){
if(used[i] || i > 0 && nums[i] == nums[i-1] && !used[i - 1]) continue;
used[i] = true;
tempList.add(nums[i]);
backtrack(list, tempList, nums, used);
used[i] = false;
tempList.remove(tempList.size() - 1);
}
}
}
Combination Sum : https://leetcode.com/problems/combination-sum/
public List<List<Integer>> combinationSum(int[] nums, int target) {
List<List<Integer>> list = new ArrayList<>();
Arrays.sort(nums);
backtrack(list, new ArrayList<>(), nums, target, 0);
return list;
}
private void backtrack(List<List<Integer>> list, List<Integer> tempList, int [] nums, int remain, int start){
if(remain < 0) return;
else if(remain == 0) list.add(new ArrayList<>(tempList));
else{
for(int i = start; i < nums.length; i++){
tempList.add(nums[i]);
backtrack(list, tempList, nums, remain - nums[i], i); // not i + 1 because we can reuse same elements
tempList.remove(tempList.size() - 1);
}
}
}
Combination Sum II (can't reuse same element) : https://leetcode.com/problems/combination-sum-ii/
public List<List<Integer>> combinationSum2(int[] nums, int target) {
List<List<Integer>> list = new ArrayList<>();
Arrays.sort(nums);
backtrack(list, new ArrayList<>(), nums, target, 0);
return list;
}
private void backtrack(List<List<Integer>> list, List<Integer> tempList, int [] nums, int remain, int start){
if(remain < 0) return;
else if(remain == 0) list.add(new ArrayList<>(tempList));
else{
for(int i = start; i < nums.length; i++){
if(i > start && nums[i] == nums[i-1]) continue; // skip duplicates
tempList.add(nums[i]);
backtrack(list, tempList, nums, remain - nums[i], i + 1);
tempList.remove(tempList.size() - 1);
}
}
}
Palindrome Partitioning : https://leetcode.com/problems/palindrome-partitioning/
public List<List<String>> partition(String s) {
List<List<String>> list = new ArrayList<>();
backtrack(list, new ArrayList<>(), s, 0);
return list;
}
public void backtrack(List<List<String>> list, List<String> tempList, String s, int start){
if(start == s.length())
list.add(new ArrayList<>(tempList));
else{
for(int i = start; i < s.length(); i++){
if(isPalindrome(s, start, i)){
tempList.add(s.substring(start, i + 1));
backtrack(list, tempList, s, i + 1);
tempList.remove(tempList.size() - 1);
}
}
}
}
public boolean isPalindrome(String s, int low, int high){
while(low < high)
if(s.charAt(low++) != s.charAt(high--)) return false;
return true;
}
Question wants us to return the length of new array after removing duplicates and that we don't care about what we leave beyond new length , hence we can use i to keep track of the position and update the array.
Remove Duplicates from Sorted Array(no duplicates) :
public int removeDuplicates(int[] nums) {
int i = 0;
for(int n : nums)
if(i < 1 || n > nums[i - 1])
nums[i++] = n;
return i;
}
Remove Duplicates from Sorted Array II (allow duplicates up to 2):
public int removeDuplicates(int[] nums) {
int i = 0;
for (int n : nums)
if (i < 2 || n > nums[i - 2])
nums[i++] = n;
return i;
}
I will show you all how to tackle various tree questions using iterative inorder traversal. First one is the standard iterative inorder traversal using stack. Hope everyone agrees with this solution.
Question : Binary Tree Inorder Traversal
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<>();
if(root == null) return list;
Stack<TreeNode> stack = new Stack<>();
while(root != null || !stack.empty()){
while(root != null){
stack.push(root);
root = root.left;
}
root = stack.pop();
list.add(root.val);
root = root.right;
}
return list;
}
Now, we can use this structure to find the Kth smallest element in BST.
Question : Kth Smallest Element in a BST
public int kthSmallest(TreeNode root, int k) {
Stack<TreeNode> stack = new Stack<>();
while(root != null || !stack.isEmpty()) {
while(root != null) {
stack.push(root);
root = root.left;
}
root = stack.pop();
if(--k == 0) break;
root = root.right;
}
return root.val;
}
We can also use this structure to solve BST validation question.
Question : Validate Binary Search Tree
public boolean isValidBST(TreeNode root) {
if (root == null) return true;
Stack<TreeNode> stack = new Stack<>();
TreeNode pre = null;
while (root != null || !stack.isEmpty()) {
while (root != null) {
stack.push(root);
root = root.left;
}
root = stack.pop();
if(pre != null && root.val <= pre.val) return false;
pre = root;
root = root.right;
}
return true;
}
Combination Sum I
public List<List<Integer>> combinationSum(int[] candidates, int target) {
List<List<Integer>> list = new ArrayList<>();
Arrays.sort(candidates);
backtrack(list, new ArrayList<Integer>(), candidates, target, 0);
return list;
}
private void backtrack(List<List<Integer>> list, List<Integer> tempList, int[] cand, int remain, int start) {
if (remain < 0) return; /** no solution */
else if (remain == 0) list.add(new ArrayList<>(tempList));
else{
for (int i = start; i < cand.length; i++) {
tempList.add(cand[i]);
backtrack(list, tempList, cand, remain-cand[i], i);
tempList.remove(tempList.size()-1);
}
}
}
Combination Sum II
public List<List<Integer>> combinationSum2(int[] candidates, int target) {
List<List<Integer>> list = new LinkedList<List<Integer>>();
Arrays.sort(candidates);
backtrack(list, new ArrayList<Integer>(), candidates, target, 0);
return list;
}
private void backtrack(List<List<Integer>> list, List<Integer> tempList, int[] cand, int remain, int start) {
if(remain < 0) return; /** no solution */
else if(remain == 0) list.add(new ArrayList<>(tempList));
else{
for (int i = start; i < cand.length; i++) {
if(i > start && cand[i] == cand[i-1]) continue; /** skip duplicates */
tempList.add(cand[i]);
backtrack(list, tempList, cand, remain - cand[i], i+1);
tempList.remove(tempList.size() - 1);
}
}
}
Combination Sum III
public List<List<Integer>> combinationSum3(int k, int n) {
List<List<Integer>> list = new ArrayList<>();
backtrack(list, new ArrayList<Integer>(), k, n, 1);
return list;
}
private void backtrack(List<List<Integer>> list, List<Integer> tempList, int k, int remain, int start) {
if(tempList.size() > k) return; /** no solution */
else if(tempList.size() == k && remain == 0) list.add(new ArrayList<>(tempList));
else{
for (int i = start; i <= 9; i++) {
tempList.add(i);
backtrack(list, tempList, k, remain-i, i+1);
tempList.remove(tempList.size() - 1);
}
}
}
Postorder traversal : Binary Tree Postorder Traversal
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<>();
if(root == null) return list;
Stack<TreeNode> stack = new Stack<>();
stack.push(root);
while(!stack.empty()){
root = stack.pop();
list.add(0, root.val);
if(root.left != null) stack.push(root.left);
if(root.right != null) stack.push(root.right);
}
return list;
}
Preorder traversal : Binary Tree Preorder Traversal
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<>();
if(root == null) return list;
Stack<TreeNode> stack = new Stack<>();
stack.push(root);
while(!stack.empty()){
root = stack.pop();
list.add(root.val);
if(root.right != null) stack.push(root.right);
if(root.left != null) stack.push(root.left);
}
return list;
}
Inorder traversal : Binary Tree Inorder Traversal
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<>();
if(root == null) return list;
Stack<TreeNode> stack = new Stack<>();
while(root != null || !stack.empty()){
while(root != null){
stack.push(root);
root = root.left;
}
root = stack.pop();
list.add(root.val);
root = root.right;
}
return list;
}
# power set
class Solution {
public List<List<Integer>> subsets(int[] nums) {
List<List<Integer>> ans = new ArrayList<>();
// Arrays.sort(nums);
// dfs(ans,new ArrayList<>(),nums,0);
// return ans;
int n = nums.length;
for(int i=(1<<n);i<(1<<(n+1));i++){
String bitmask = Integer.toBinaryString(i).substring(1);
List<Integer> tem = new ArrayList<>();
for(int j=0;j<n;j++){
if(bitmask.charAt(j)=='1')tem.add(nums[j]);
}ans.add(tem);
}return ans;
}
private void dfs(List<List<Integer>> ans,List<Integer> tem, int A[],int i){
ans.add(new ArrayList<>(tem));
for(int j=i;j<A.length;j++){
tem.add(A[j]);
dfs(ans,tem,A,j+1);
tem.remove(tem.size()-1);
}
}
}
# partition dp
static int matrixMultiplication(int N, int A[])
{
// code here
int dp[][] = new int[N][N];
return f(1,N-1,A,dp);
}
static int f(int i,int j,int A[],int dp[][]){
if(i==j) return 0;
if(dp[i][j]!=0) return dp[i][j];
int min=(int)1e9;
for(int k=i;k<=j-1;k++){
int step = A[i-1]*A[k]*A[j]+f(i,k,A,dp)+f(k+1,j,A,dp);
min=Math.min(min,step);
}return dp[i][j]= min;
}
Partition DP is a technique used to solve problems that involve partitioning a set of elements into two or more subsets, such that each subset satisfies certain conditions. The basic idea behind partition DP is to define a state that represents the current state of the partition and then recursively compute the optimal solution for that state.
The rules for partition DP are as follows:
Define the state: The first step in partition DP is to define a state that represents the current state of the partition. The state should be defined in such a way that it captures all the relevant information about the current partition.
Define the base case: The next step is to define the base case for the partition. This is the simplest possible partition that can be solved directly without any recursion.
Define the recurrence relation: The recurrence relation defines how to compute the optimal solution for the current state of the partition, based on the optimal solutions for the previous states. The recurrence relation should be defined in such a way that it captures the optimal solution for the current state, based on the optimal solutions for the previous states.
Compute the optimal solution: Once the recurrence relation has been defined, the optimal solution for the current state can be computed by recursively applying the recurrence relation to the previous states, until the base case is reached.
Return the final solution: Once the optimal solution for the current state has been computed, it can be returned as the final solution to the problem.
Partition DP can be used to solve a wide range of problems, including subset sum, knapsack, and graph partitioning problems. The key to using partition DP effectively is to carefully define the state and the recurrence relation, so that they capture all the relevant information about the problem and lead to an efficient solution.
# identity
Partition DP problems typically involve partitioning a set of elements into two or more subsets, such that each subset satisfies certain conditions. Here are some common characteristics of partition DP problems:
The problem involves partitioning a set of elements into two or more subsets.
The subsets must satisfy certain conditions, such as having a certain sum, size, or property.
The problem requires finding the optimal partition that satisfies the conditions.
The problem may involve finding the number of ways to partition the set, or the actual partition itself.
The problem may involve finding the minimum or maximum value of a certain function over all possible partitions.
The problem may involve finding the optimal partition recursively, by considering all possible partitions of a smaller subset of elements.
Some examples of partition DP problems include:
Subset sum problem: Given a set of integers, find if there exists a subset whose sum is equal to a given target value.
Knapsack problem: Given a set of items with weights and values, find the maximum value that can be obtained by selecting a subset of items that fit into a knapsack of a given capacity.
Graph partitioning problem: Given a graph, partition the vertices into two or more subsets such that the number of edges between the subsets is minimized.
Balanced partition problem: Given a set of integers, partition the set into two subsets such that the difference between the sums of the subsets is minimized.
If a problem involves partitioning a set of elements and finding the optimal partition that satisfies certain conditions, it may be a partition DP problem.
static int matrixMultiplication(int N, int A[])
{
int dp[][] = new int[N][N];
for(int i=N-1;i>=1;i--){
for(int j=i+1;j<N;j++){
int min=(int)1e9;
for(int k=i;k<=j-1;k++){
int step = A[i-1]*A[k]*A[j]+
dp[i][k]+dp[k+1][j];
min=Math.min(min,step);
} dp[i][j]= min;
}
}
return dp[1][N-1];
}
static int f(int i,int j,int A[],int dp[][]){
if(i==j) return 0;
if(dp[i][j]!=0) return dp[i][j];
int min=(int)1e9;
for(int k=i;k<=j-1;k++){
int step = A[i-1]*A[k]*A[j]+f(i,k,A,dp)+f(k+1,j,A,dp);
min=Math.min(min,step);
}return dp[i][j]= min;
}
Full problem list: https://leetcode.com/list/x1k8lxi5
Longest Increasing Subsequence variants:
https://leetcode.com/problems/longest-increasing-subsequence/
https://leetcode.com/problems/largest-divisible-subset/
https://leetcode.com/problems/russian-doll-envelopes/
https://leetcode.com/problems/maximum-length-of-pair-chain/
https://leetcode.com/problems/number-of-longest-increasing-subsequence/
https://leetcode.com/problems/delete-and-earn/
https://leetcode.com/problems/longest-string-chain/
Partition Subset:
https://leetcode.com/problems/partition-equal-subset-sum/
https://leetcode.com/problems/last-stone-weight-ii/
BitMasking:
https://leetcode.com/problems/partition-to-k-equal-sum-subsets/
Longest Common Subsequence Variant:
https://leetcode.com/problems/longest-common-subsequence/
https://leetcode.com/problems/edit-distance/
https://leetcode.com/problems/distinct-subsequences/
https://leetcode.com/problems/minimum-ascii-delete-sum-for-two-strings/
Palindrome:
https://leetcode.com/problems/palindrome-partitioning-ii/
https://leetcode.com/problems/palindromic-substrings/
Coin Change variant:
https://leetcode.com/problems/coin-change/
https://leetcode.com/problems/coin-change-2/
https://leetcode.com/problems/combination-sum-iv/
https://leetcode.com/problems/perfect-squares/
https://leetcode.com/problems/minimum-cost-for-tickets/
Matrix multiplication variant:
https://leetcode.com/problems/minimum-score-triangulation-of-polygon/
https://leetcode.com/problems/minimum-cost-tree-from-leaf-values/
https://leetcode.com/problems/burst-balloons/
Matrix/2D Array:
https://leetcode.com/problems/matrix-block-sum/
https://leetcode.com/problems/range-sum-query-2d-immutable/
https://leetcode.com/problems/dungeon-game/
https://leetcode.com/problems/triangle/
https://leetcode.com/problems/maximal-square/
https://leetcode.com/problems/minimum-falling-path-sum/
Hash + DP:
https://leetcode.com/problems/target-sum/
https://leetcode.com/problems/longest-arithmetic-sequence/
https://leetcode.com/problems/longest-arithmetic-subsequence-of-given-difference/
https://leetcode.com/problems/maximum-product-of-splitted-binary-tree/
State machine:
https://leetcode.com/problems/best-time-to-buy-and-sell-stock/
https://leetcode.com/problems/best-time-to-buy-and-sell-stock-ii/
https://leetcode.com/problems/best-time-to-buy-and-sell-stock-iii/
https://leetcode.com/problems/best-time-to-buy-and-sell-stock-iv/
https://leetcode.com/problems/best-time-to-buy-and-sell-stock-with-cooldown/
https://leetcode.com/problems/best-time-to-buy-and-sell-stock-with-transaction-fee/
Depth First Search + DP:
https://leetcode.com/problems/out-of-boundary-paths/
https://leetcode.com/problems/knight-probability-in-chessboard/
Minimax DP:
https://leetcode.com/problems/predict-the-winner/
https://leetcode.com/problems/stone-game/
Misc:
https://leetcode.com/problems/greatest-sum-divisible-by-three/
https://leetcode.com/problems/decode-ways/
https://leetcode.com/problems/perfect-squares/
https://leetcode.com/problems/count-numbers-with-unique-digits/
https://leetcode.com/problems/longest-turbulent-subarray/
https://leetcode.com/problems/number-of-dice-rolls-with-target-sum/
Sample solutions for each of above problem type:
Longest Increasing Subsequence
https://leetcode.com/problems/longest-increasing-subsequence/
https://leetcode.com/problems/largest-divisible-subset/
https://leetcode.com/problems/russian-doll-envelopes/
https://leetcode.com/problems/maximum-length-of-pair-chain/
https://leetcode.com/problems/number-of-longest-increasing-subsequence/
https://leetcode.com/problems/delete-and-earn/
https://leetcode.com/problems/longest-string-chain/
class Solution {
public:
int lengthOfLIS(vector<int>& nums) {
int n = nums.size();
vector<int>LIS(n+1, 1);
for (int i = 0; i < n; i++) {
for (int j = 0; j < i; j++) {
if (nums[i] > nums[j])
LIS[i] = max(LIS[i], 1 + LIS[j]);
}
}
int ans = 0;
for (int i = 0; i < n; i++) {
ans = max(ans, LIS[i]);
}
return ans;
}
};Partition Subset Sum:
https://leetcode.com/problems/partition-equal-subset-sum/
https://leetcode.com/problems/last-stone-weight-ii/
class Solution {
public:
bool canPartition(vector<int>& nums) {
int n = nums.size();
int sum = 0;
for (int i = 0; i < n; i++)
sum += nums[i];
if (sum % 2 != 0) return false;
int target = sum/2;
vector<bool>dp(target+1, false);
dp[0] = true;
for (int i = 0; i < n; i++) {
for (int j = target; j >= nums[i]; j--) {
dp[j] = dp[j] | dp[j - nums[i]];
}
}
return dp[target];
}
};BitMasking in DP:
https://leetcode.com/problems/partition-to-k-equal-sum-subsets/
class Solution {
int dp[(1<<16) + 2];
public:
bool canPartitionKSubsets(vector<int>& nums, int k) {
int n = nums.size();
fill(dp, dp+(1<<16)+2, -1);
int sum = 0;
for (int i = 0; i < n; i++)
sum += nums[i];
if (sum % k != 0) return false;
int target = sum/k;
dp[0] = 0;
for (int mask = 0; mask < (1<<n); mask++) {
if (dp[mask] == -1) continue;
for (int i = 0; i < n; i++) {
if (!(mask & (1 << i)) && dp[mask] + nums[i] <= target)
dp[mask | (1 << i)] = (dp[mask] + nums[i]) % target;
}
}
return dp[(1<<n)-1] == 0;
}
};Longest Common Subsequence
https://leetcode.com/problems/longest-common-subsequence/
https://leetcode.com/problems/edit-distance/
https://leetcode.com/problems/distinct-subsequences/
https://leetcode.com/problems/minimum-ascii-delete-sum-for-two-strings/
class Solution {
int longestCommonSubsequenceUtil(string text1, string text2, int n, int m) {
if (n == 0 || m == 0)
return 0;
vector<vector<int>>L(n+1, vector<int>(m+1, 0));
for (int i = 0; i <= n; i++) {
for (int j = 0; j <= m; j++) {
if (i == 0 || j == 0)
L[i][j] = 0;
else if (text1[i-1] == text2[j-1])
L[i][j] = 1 + L[i-1][j-1];
else
L[i][j] = max(L[i][j-1], L[i-1][j]);
}
}
return L[n][m];
}
public:
int longestCommonSubsequence(string text1, string text2) {
int n = text1.size();
int m = text2.size();
return longestCommonSubsequenceUtil(text1, text2, n, m);
}
};Palindrome:
https://leetcode.com/problems/palindrome-partitioning-ii/
https://leetcode.com/problems/palindromic-substrings/
class Solution {
public:
int minCut(string s) {
int n = s.length();
int res[n];
bool P[n][n];
for (int i = 0; i < n; i++)
P[i][i] = true;
for (int L = 2; L <= n; L++) {
for (int i = 0; i < n-L+1; i++) {
int j = i+L-1;
if (L == 2) {
P[i][j] = (s[i] == s[j]);
} else {
P[i][j] = (s[i] == s[j]) && P[i+1][j-1];
}
}
}
for (int i = 0; i < n; i++) {
if (P[0][i])
res[i] = 0;
else {
res[i] = INT_MAX;
for (int j = 0; j < i; j++) {
if (P[j+1][i] && res[i] > 1 + res[j])
res[i] = 1+res[j];
}
}
}
return res[n-1] == INT_MAX ? 1 : res[n-1];
}
};Coin Change:
https://leetcode.com/problems/coin-change/
https://leetcode.com/problems/coin-change-2/
https://leetcode.com/problems/combination-sum-iv/
https://leetcode.com/problems/perfect-squares/
https://leetcode.com/problems/minimum-cost-for-tickets/
class Solution {
public:
int coinChange(vector<int>& coins, int amount) {
int n = coins.size();
if (n == 0) return 0;
vector<int>res(amount+1, INT_MAX);
res[0] = 0;
for (int i = 0; i < n; i++) {
for (int j = coins[i]; j <= amount; j++) {
if (res[j-coins[i]] != INT_MAX)
res[j] = min(res[j], 1+res[j-coins[i]]);
}
}
return res[amount] != INT_MAX ? res[amount] : -1;
}
};Matrix multiplication:
https://leetcode.com/problems/minimum-score-triangulation-of-polygon/
https://leetcode.com/problems/minimum-cost-tree-from-leaf-values/
https://leetcode.com/problems/burst-balloons/
class Solution {
public:
int minScoreTriangulation(vector<int>& A) {
int n = A.size();
vector<vector<int>>dp(n, vector<int>(n, 0));
for (int L = 2; L <= n; L++) {
for (int i = 0; i+L < n; i++) {
int j = i+L;
dp[i][j] = INT_MAX;
for (int k = i+1; k < j; k++) {
dp[i][j] = min(dp[i][j], dp[i][k] + dp[k][j] + A[i]*A[k]*A[j]);
}
}
}
return dp[0][n-1];
}
};Matrix/2D Array:
https://leetcode.com/problems/matrix-block-sum/
https://leetcode.com/problems/range-sum-query-2d-immutable/
https://leetcode.com/problems/dungeon-game/
https://leetcode.com/problems/triangle/
https://leetcode.com/problems/maximal-square/
https://leetcode.com/problems/minimum-falling-path-sum/
class Solution {
public:
vector<vector<int>> matrixBlockSum(vector<vector<int>>& mat, int K) {
int m = mat.size();
int n = mat[0].size();
vector<vector<int>>sum(m+1, vector<int>(n+1, 0));
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
sum[i][j] = sum[i-1][j] + sum[i][j-1] - sum[i-1][j-1] + mat[i-1][j-1];
}
}
vector<vector<int>>res(m, vector<int>(n, 0));
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
int r1 = max(0, i-K); int c1 = max(0, j-K);
int r2 = min(m-1, i+K); int c2 = min(n-1, j+K);
r1++; r2++;
c1++; c2++;
res[i][j] = sum[r2][c2] - (sum[r2][c1-1] + sum[r1-1][c2]- sum[r1-1][c1-1]);
}
}
return res;
}
};Hash + DP:
https://leetcode.com/problems/target-sum/
https://leetcode.com/problems/longest-arithmetic-sequence/
https://leetcode.com/problems/longest-arithmetic-subsequence-of-given-difference/
https://leetcode.com/problems/maximum-product-of-splitted-binary-tree/
class Solution {
public:
int findTargetSumWays(vector<int>& nums, int S) {
int n = nums.size();
unordered_map<int, int>hm;
hm[0] = 1;
for (int i = 0; i < n; i++) {
auto mp = hm;
hm.clear();
for (auto it = mp.begin(); it != mp.end(); it++) {
hm[it->first + nums[i]] += it->second;
hm[it->first - nums[i]] += it->second;
}
}
return hm[S];
}
};State machine:
https://leetcode.com/problems/best-time-to-buy-and-sell-stock/
https://leetcode.com/problems/best-time-to-buy-and-sell-stock-ii/
https://leetcode.com/problems/best-time-to-buy-and-sell-stock-iii/
https://leetcode.com/problems/best-time-to-buy-and-sell-stock-iv/
https://leetcode.com/problems/best-time-to-buy-and-sell-stock-with-cooldown/
https://leetcode.com/problems/best-time-to-buy-and-sell-stock-with-transaction-fee/
class Solution {
public:
int maxProfit(vector<int>& prices, int fee) {
int n = prices.size();
vector<int>buy(n, 0);
vector<int>sell(n, 0);
buy[0] = -prices[0], sell[0] = 0;
for (int i = 1; i < n; i++) {
buy[i] = max(buy[i-1], sell[i-1]-prices[i]);
sell[i] = max(sell[i-1], buy[i-1]+prices[i]-fee);
}
return sell[n-1];
}
};Depth First Search +DP:
https://leetcode.com/problems/out-of-boundary-paths/
https://leetcode.com/problems/knight-probability-in-chessboard/
class Solution {
int mod = 1000000007;
int dfs(int m, int n, int N, int r, int c, vector<vector<vector<int>>>& dp) {
if (r < 0 || c < 0 || r >= m || c >= n) return 1;
if (N == 0) return 0;
if (dp[N][r][c] != -1) return dp[N][r][c]%mod;
int moves = 0;
moves = (moves + dfs(m, n, N-1, r, c+1, dp))%mod;
moves = (moves + dfs(m, n, N-1, r, c-1, dp))%mod;
moves = (moves + dfs(m, n, N-1, r+1, c, dp))%mod;
moves = (moves + dfs(m, n, N-1, r-1, c, dp))%mod;
dp[N][r][c] = moves%mod;
return dp[N][r][c];
}
public:
int findPaths(int m, int n, int N, int i, int j) {
vector<vector<vector<int>>>dp(N+1, vector<vector<int>>(m+1, vector<int>(n+1, -1)));
return dfs(m, n, N, i, j, dp);
}
};Minimax DP:
https://leetcode.com/problems/predict-the-winner/
https://leetcode.com/problems/stone-game/
class Solution {
public:
bool PredictTheWinner(vector<int>& nums) {
int n = nums.size();
int res[n][n];
for (int i = 0; i < n; i++)
res[i][i] = nums[i];
for (int l = 2; l <= n; l++) {
for (int i = 0; i+l-1 < n; i++) {
int j = i+l-1;
int a = (i+1 <= j-1) ? res[i+1][j-1] : 0;
int b = (i+2 <= j) ? res[i+2][j] : 0;
int c = (i <= j-2) ? res[i][j-2] : 0;
res[i][j] = max(nums[i] + min(a,b), nums[j] + min(a, c));
}
}
int total = 0;
for (int i = 0; i < n; i++)
total += nums[i];
return res[0][n-1] >= total - res[0][n-1];
}
};Miscellaneous:
https://leetcode.com/problems/greatest-sum-divisible-by-three/
https://leetcode.com/problems/decode-ways/
https://leetcode.com/problems/count-numbers-with-unique-digits/
https://leetcode.com/problems/longest-turbulent-subarray/
https://leetcode.com/problems/number-of-dice-rolls-with-target-sum/
Please point out issues in solutions if you find any. There might be better approaches in few.
Graph Problems For Practice
Sharing some topic wise good Graph problems and sample solutions to observe on how to approach.
List: https://leetcode.com/list/x1wy4de7
Union Find:
Identify if problems talks about finding groups or components.
https://leetcode.com/problems/friend-circles/
https://leetcode.com/problems/redundant-connection/
https://leetcode.com/problems/most-stones-removed-with-same-row-or-column/
https://leetcode.com/problems/number-of-operations-to-make-network-connected/
https://leetcode.com/problems/satisfiability-of-equality-equations/
https://leetcode.com/problems/accounts-merge/
All the above problems can be solved by Union Find algorithm with minor tweaks.
Below is a standard template for union find problems.
class Solution {
vectorparent;
int find(int x) {
return parent[x] == x ? x : find(parent[x]);
}
public:
vector findRedundantConnection(vector<vector>& edges) {
int n = edges.size();
parent.resize(n+1, 0);
for (int i = 0; i <= n; i++)
parent[i] = i;
vector<int>res(2, 0);
for (int i = 0; i < n; i++) {
int x = find(edges[i][0]);
int y = find(edges[i][1]);
if (x != y)
parent[y] = x;
else {
res[0] = edges[i][0];
res[1] = edges[i][1];
}
}
return res;
}};
Depth First Search
Start DFS from nodes at boundary:
https://leetcode.com/problems/surrounded-regions/
https://leetcode.com/problems/number-of-enclaves/
class Solution {
int rows, cols;
void dfs(vector<vector>& A, int i, int j) {
if (i < 0 || j < 0 || i >= rows || j >= cols)
return;
if (A[i][j] != 1)
return;
A[i][j] = -1;
dfs(A, i+1, j);
dfs(A, i-1, j);
dfs(A, i, j+1);
dfs(A, i, j-1);
}public:
int numEnclaves(vector<vector>& A) {
if (A.empty()) return 0;
rows = A.size();
cols = A[0].size();
for (int i = 0; i < rows; i++) {
for (int j = 0; j < cols; j++) {
if (i == 0 || j == 0 || i == rows-1 || j == cols-1)
dfs(A, i, j);
}
}
int ans = 0;
for (int i = 0; i < rows; i++) {
for (int j = 0; j < cols; j++) {
if (A[i][j] == 1)
ans++;
}
}
return ans;
}};
Time taken to reach all nodes or share information to all graph nodes:
https://leetcode.com/problems/time-needed-to-inform-all-employees/
class Solution {
void dfs(unordered_map<int, vector>&hm, int i, vector& informTime, int &res, int curr) {
curr += informTime[i];
res = max(res, curr);
for (auto it = hm[i].begin(); it != hm[i].end(); it++)
dfs(hm, *it, informTime, res, curr);
}public:
int numOfMinutes(int n, int headID, vector& manager, vector& informTime) {
unordered_map<int, vector<int>>hm;
for (int i = 0; i < n; i++)
if (manager[i] != -1) hm[manager[i]].push_back(i);
int res = 0, curr = 0;
dfs(hm, headID, informTime, res, curr);
return res;
}};
DFS from each unvisited node/Island problems
https://leetcode.com/problems/number-of-closed-islands/
https://leetcode.com/problems/number-of-islands/
https://leetcode.com/problems/keys-and-rooms/
https://leetcode.com/problems/max-area-of-island/
https://leetcode.com/problems/flood-fill/
class Solution {
void dfs(vector<vector>& grid, vector<vector>& visited, int i, int j, int m, int n) {
if (i < 0 || i >= m || j < 0 || j >= n) return;
if (grid[i][j] == '0' || visited[i][j]) return;
visited[i][j] = true;
dfs(grid, visited, i+1, j, m, n);
dfs(grid, visited, i, j+1, m, n);
dfs(grid, visited, i-1, j, m, n);
dfs(grid, visited, i, j-1, m, n);
}
public:
int numIslands(vector<vector>& grid) {
if (grid.empty()) return 0;
int m = grid.size();
int n = grid[0].size();
vector<vector<bool>>visited(m, vector<bool>(n, false));
int res = 0;
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (grid[i][j] == '1' && !visited[i][j]) {
dfs(grid, visited, i, j, m, n);
res++;
}
}
}
return res;
}
};Cycle Find:
https://leetcode.com/problems/find-eventual-safe-states/
class Solution {
bool dfs(vector<vector>& graph, int v, vector& dp) {
if (dp[v])
return dp[v] == 1;
dp[v] = -1;
for (auto it = graph[v].begin(); it != graph[v].end(); it++)
if (!dfs(graph, *it, dp))
return false;
dp[v] = 1;
return true;
}public:
vector eventualSafeNodes(vector<vector>& graph) {
int V = graph.size();
vector<int>res;
vector<int>dp(V, 0);
for (int i = 0; i < V; i++) {
if (dfs(graph, i, dp))
res.push_back(i);
}
return res;
}};
Breadth First Search
Shortest Path:
https://leetcode.com/problems/01-matrix/
https://leetcode.com/problems/as-far-from-land-as-possible/
https://leetcode.com/problems/rotting-oranges/
https://leetcode.com/problems/shortest-path-in-binary-matrix/
Start BFS from nodes from which shortest path is asked for.
Below is the sample BFS approach to find the path.
class Solution {
public:
vector<vector> updateMatrix(vector<vector>& matrix) {
if (matrix.empty()) return matrix;
int rows = matrix.size();
int cols = matrix[0].size();
queue<pair<int, int>>pq;
for (int i = 0; i < rows; i++) {
for (int j = 0; j < cols; j++) {
if (matrix[i][j] == 0) {
pq.push({i-1, j}), pq.push({i+1, j}), pq.push({i, j-1}), pq.push({i, j+1});
}
}
}
vector<vector<bool>>visited(rows, vector<bool>(cols, false));
int steps = 0;
while (!pq.empty()) {
steps++;
int size = pq.size();
for (int i = 0; i < size; i++) {
auto front = pq.front();
int l = front.first;
int r = front.second;
pq.pop();
if (l >= 0 && r >= 0 && l < rows && r < cols && !visited[l][r] && matrix[l][r] == 1) {
visited[l][r] = true;
matrix[l][r] = steps;
pq.push({l-1, r}), pq.push({l+1, r}), pq.push({l, r-1}), pq.push({l, r+1});
}
}
}
return matrix;
}};
Graph coloring/Bipartition
https://leetcode.com/problems/possible-bipartition/
https://leetcode.com/problems/is-graph-bipartite/
Problems asks to check if its possible to divide the graph nodes into 2 groups
Apply BFS for same. Below is a sample graph coloring approach.
class Solution {
public:
bool isBipartite(vector<vector>& graph) {
int n = graph.size();
vectorcolor(n, -1);
for (int i = 0; i < n; i++) {
if (color[i] != -1) continue;
color[i] = 1;
queue<int>q;
q.push(i);
while (!q.empty()) {
int t = q.front();
q.pop();
for (int j = 0; j < graph[t].size(); j++) {
if (color[graph[t][j]] == -1) {
color[graph[t][j]] = 1-color[t];
q.push(graph[t][j]);
} else if (color[graph[t][j]] == color[t]) {
return false;
}
}
}
}
return true;
}
};Topological Sort:
Check if its directed acyclic graph and we have to arrange the elements in an order in which we need to select the most independent node at first. Number of in-node 0
https://leetcode.com/problems/course-schedule/
https://leetcode.com/problems/course-schedule-ii/
Below is sample approach. Find if cycle is present, if not apply topological sort.
class Solution {
int V;
list*adj;
bool isCyclicUtil(int v, vector<bool>&visited, vector<bool>&recStack) {
visited[v] = true;
recStack[v] = true;
for (auto it = adj[v].begin(); it != adj[v].end(); it++) {
if (!visited[*it] && isCyclicUtil(*it, visited, recStack))
return true;
else if (recStack[*it])
return true;
}
recStack[v] = false;
return false;
}
bool isCyclic() {
vector<bool>visited(V, false);
vector<bool>recStack(V, false);
for (int i = 0; i < V; i++) {
if (isCyclicUtil(i, visited, recStack))
return true;
}
return false;
}
void topologicalSortUtil(int v, vector<bool>&visited, vector<int>& res) {
visited[v] = true;
for (auto it = adj[v].begin(); it != adj[v].end(); it++)
if (!visited[*it])
topologicalSortUtil(*it, visited, res);
res.push_back(v);
}
vector<int>topologicalSort(int v) {
vector<int>res;
vector<bool>visited(V, false);
topologicalSortUtil(v, visited, res);
for (int i = 0; i < V; i++) {
if (!visited[i])
topologicalSortUtil(i, visited, res);
}
return res;
}
public:
vector<int> findOrder(int numCourses, vector<vector<int>>& prerequisites) {
V = numCourses;
adj = new list<int>[V];
unordered_map<int, vector<int>>hm;
for (int i = 0; i < prerequisites.size(); i++) {
adj[prerequisites[i][0]].push_back(prerequisites[i][1]);
hm[prerequisites[i][1]].push_back(prerequisites[i][0]);
}
if (isCyclic()) return vector<int>();
int i = 0;
for (i = 0; i < V; i++) {
if (hm.find(i) == hm.end())
break;
}
return topologicalSort(i);
}};
Find Shortest Path (Dijkstra's/Bellman Ford)
https://leetcode.com/problems/network-delay-time/
Dijkstras and Bellman Ford:
class Solution {
public:
int networkDelayTime(vector<vector>& times, int N, int K) {
priority_queue<pair<int, int>, vector<pair<int, int>>, greater<pair<int, int>>>pq;
vector<int>dist(N+1, INT_MAX);
pq.push(make_pair(0, K));
dist[K] = 0;
unordered_map<int, vector<pair<int, int>>>hm;
for (int i = 0; i < times.size(); i++)
hm[times[i][0]].push_back(make_pair(times[i][1], times[i][2]));
while (!pq.empty()) {
pair<int, int>p = pq.top();
pq.pop();
int u = p.second;
for (auto it = hm[u].begin(); it != hm[u].end(); it++) {
int v = it->first;
int w = it->second;
if (dist[v] > dist[u] + w) {
dist[v] = dist[u] + w;
pq.push(make_pair(dist[v], v));
}
}
}
int res = 0;
for (int i = 1; i <= N; i++)
res = max(res, dist[i]);
return res == INT_MAX ? -1 : res;
}
};
class Solution {
public:
int networkDelayTime(vector<vector<int>>& times, int N, int K) {
int n = times.size();
if (!n) return 0;
vector<int>dist(N+1, INT_MAX);
int res = 0;
dist[K] = 0;
for (int i = 0; i < N; i++) {
for (int j = 0; j < n; j++) {
int u = times[j][0];
int v = times[j][1];
int w = times[j][2];
if (dist[u] != INT_MAX && dist[u] + w < dist[v])
dist[v] = w + dist[u];
}
}
for (int i = 1; i <= N; i++)
res = max(res, dist[i]);
return res == INT_MAX ? -1 : res;
}
}Complete List: Below are mostly list of problems (mostly medium level and may 1 or 2 easy) which are better to start practice with:
(Updated on 14th June '20)
Union Find:
https://leetcode.com/problems/friend-circles/
https://leetcode.com/problems/redundant-connection/
https://leetcode.com/problems/most-stones-removed-with-same-row-or-column/
https://leetcode.com/problems/number-of-operations-to-make-network-connected/
https://leetcode.com/problems/satisfiability-of-equality-equations/
https://leetcode.com/problems/accounts-merge/
https://leetcode.com/problems/connecting-cities-with-minimum-cost/
DFS:
DFS from boundary:
https://leetcode.com/problems/surrounded-regions/
https://leetcode.com/problems/number-of-enclaves/
Shortest time:
https://leetcode.com/problems/time-needed-to-inform-all-employees/
Islands Variants
https://leetcode.com/problems/number-of-closed-islands/
https://leetcode.com/problems/number-of-islands/
https://leetcode.com/problems/keys-and-rooms/
https://leetcode.com/problems/max-area-of-island/
https://leetcode.com/problems/flood-fill/
https://leetcode.com/problems/coloring-a-border/
Hash/DFS:
https://leetcode.com/problems/employee-importance/
https://leetcode.com/problems/find-the-town-judge/
Cycle Find:
https://leetcode.com/problems/find-eventual-safe-states/
BFS:
BFS for shortest path:
https://leetcode.com/problems/01-matrix/
https://leetcode.com/problems/as-far-from-land-as-possible/
https://leetcode.com/problems/rotting-oranges/
https://leetcode.com/problems/shortest-path-in-binary-matrix/
Graph coloring:
https://leetcode.com/problems/possible-bipartition/
https://leetcode.com/problems/is-graph-bipartite/
Topological Sort:
https://leetcode.com/problems/course-schedule-ii/
Shortest Path:
https://leetcode.com/problems/network-delay-time/
https://leetcode.com/problems/find-the-city-with-the-smallest-number-of-neighbors-at-a-threshold-distance/
https://leetcode.com/problems/cheapest-flights-within-k-stops/
Please correct the approach/solution if you find anything wrong.
Designing a distributed Job Scheduler
I am writing this post because I was not able to find any resources for the system design question “Design a job scheduler” that were satisfying (at least for me). I thought that sharing my approach with you in oder to start a discussion would be great. I also think that it touches and uses a lot of concepts involved in a distributed system and can be a good starting point for people studying for their System Design Interview.
Please don't forget to UPVOTE if you like the post :)
Functional requirements (can vary but I assume the following):
A job can be scheduled for one time or multiple executions (cron job) by other services/microservices
For each job a class can be specified which inherits some interface like IJob so that we can later call that interface method on the worker nodes when we execute the job. (That class can e.g. be present in a .jar file on the worker nodes).
Results of job executions are stored and can be queried
Non-function requirements (again, can vary but I assume the following):
Scalability: Thousands or even millions of jobs can be scheduled and run per day
Durability: Jobs must not get lost -> we need to persist jobs
Reliability: Jobs must not be executed much later than expected or dropped -> we need a fault-tolerant system
Availability: It should always be possible to schedule and execute jobs -> (dynamical) horizontal scaling
Jobs must not be executed multiple times (or such occurences should be kept to a minimum)
Domain Analysis: Concepts
We can define the Domain Model that can later be converted into a Data Model (Database Model for Schema or a Model for ZooKeeper):
Job:
Represents a Job to be executed
Properties:
Id, Name, JobExecutorClass, Priority, Running, LastStartTime, LastEndTime, LastExecutor, Data (Parameters)
Trigger (based on the concept Quartz Scheduler uses):
Defines when a Job is executed
We can define different Triggers like: OneTimeTrigger, CronTrigger
Based on the type, we have properties like:
Id, Type, StartTime, EndTime, OneTime, Cronjob, Interval
Executor:
Is a single Job Executor/Worker Node
Can have Properties like:
Id (e.g. IP-based), LastHeartBeat
The multiplicity between Job and Trigger: Job--1-------*--Trigger (A Job can have multiple Triggers)
HLD (High Level Design)
Now, lets look at a high-level System Design diagram:
Microservices that want to schedule a non-/recuring Job: Can send a Message (or produce in Kafka terminology) to the corresponding Kafka Queue (precisely a Topic).
Job Scheduler Service: Will consume the Messages (requesting a Job enqueueing). They will generate a unique Id using e.g. the Snowflake ID Generation concept. Based on that ID (e.g. by hashing it) they decide into which Database Partition the Job will go. They create a Job and Trigger record according to the Message in the corresponding Database Partition.
RDBMS: I chose an RDBMS because we will later need ACID properties, meaning transactions. The database is sharded into an adequate number of shards to distribute the load and data. We use Active-Passive/Master-Slave Replication for each Partition in a semi-synchronous fashion. One Slave/Follower will follow synchronously while the others will receive the Replication Stream asynchronously. That way, we can be sure that at least one Slave holds up to date data in case the Master fails (due to network partitions, server outage, etc.) and that Slave will be promoted to be the new Leader.
Job Executor Service:
- On Startup it will fetch the Database Partitioning info from ZooKeeper as well as the Partition Assignment between other instances and the Database Partitions.
- It will choose a Database Partition which has the least number of Executors assigned to balance out the number of Executors that execute Jobs for a all the different Database Partitions.
- It will send/store the Partition Assignment to ZooKeeper.
- It constantly sends Heartbeats to ZooKeeper
- It pulls information from the Database Partition and fights with other Executor instances assigned to the same Database Partition for Jobs that are due to execute. The fighting works by using Row Locks. That is why we need transactional properties (hence an RDBS that supports that, not all really do!)
- Before an Executor Node executes a Job, it will update the Job record in the DB: Flagging it to be “Running”, store the “StartTime” and which Executor node (=itself) is executing the Job, etc.
- When an Executor Node fails then other Nodes (assigned the same Partition) can detect it using ZooKeeper (due to the Heartbeating). They can then find all the Jobs that the failed Node was executing (Flag=Running and LastExecutor=Failed Node) and can fight for those Jobs to execute them (we could make a Job configurable to retry or not in case of execution failure).
- Finally after successfully/unsuccessfully executing a Job, we send/publish/produce a Message to another Kafka Queue.
Regarding Point 7 (to expand the horizon on possibilities): We could also use Broadcast Messaging or a Gossip Protocol to detect Node failures. I'm excited to hear your argumentation.
Result Handler Service: Will consume Messages and store the Execution Result in a NoSQL database like Cassandra – Cassandra has a great write-throughput due to the fact that it is Leaderless (no time lost for fail overs for example), replicates asynchronously (can be configured) etc. We are also okay with Eventual Consistency because it is not crucial if we see a result with some delay.
Coordination Service, ZooKeeper: Stores the above mentioned information. Regarding the Database Partitioning information: We can e.g. load that info into ZooKeeper from another Service/Configuration file.
Message Queues, in general: We use Message Queues (here Kafka which is more of an (append) log than a Queue in the conventional sense, you can find great docs on the official website) in order to:
Be able to scale the consumer and producer nodes independently (in Kafka we have Topics which can be horizontally partitioned and scale by that)
We decouple the consumer and producer from each other
Lower latency for the producer (doesn't have to wait for a response)
Durability and Reliability: When a Consumer Node crashes another Node can process the Message which otherwise would be lost (see Offset in Kafka). The Messages are persisted.
We can throttle/limit the number of messages the consumers process (see Backpressure)
Kafka offers message ordering
Other Issues and Concerns
Unreliable Clocks/Time: In a distributed system we have unreliable clocks and time (due to unbounded delays when requesting NTP time because we are using packet-switched networks and usually not circuit-switched ones), unreliable NTP servers, Quartz Clocks that develop an offset, etc). When we want to schedule Jobs reliably and execute them at the right time, clocks and time play an important role. We therefore need to make sure that the times on the nodes are synchronized and don't differ too much. One way to achieve that is to use multiple NTP servers and filter out those that deviate much. Another more reliable but costly way is to use Atomic Clocks in the Data Center(s).
Final Words:
Of course this is a somewhat “simple” approach that would probably fit into a 45 minutes system design interview
I’m aware that there are a lot of difficulties to actually build such a system, e.g.: Distributing Jobs correctly based on the load/work they have to do (and using the CPUs most efficiently), Exactly-once-delivery (/execution) and so on. Feel free to start a discussion :).
I didn’t go deeply into things like how ZooKeeper or Apache Kafka works since that would blow the scope of this post. I assume that you know that those systems are already built in a distributed, fault-tolerant way.
Let me know what you think :)! I appreciate any input and feedback and would love to iterate on this approach with you!
Segment trees
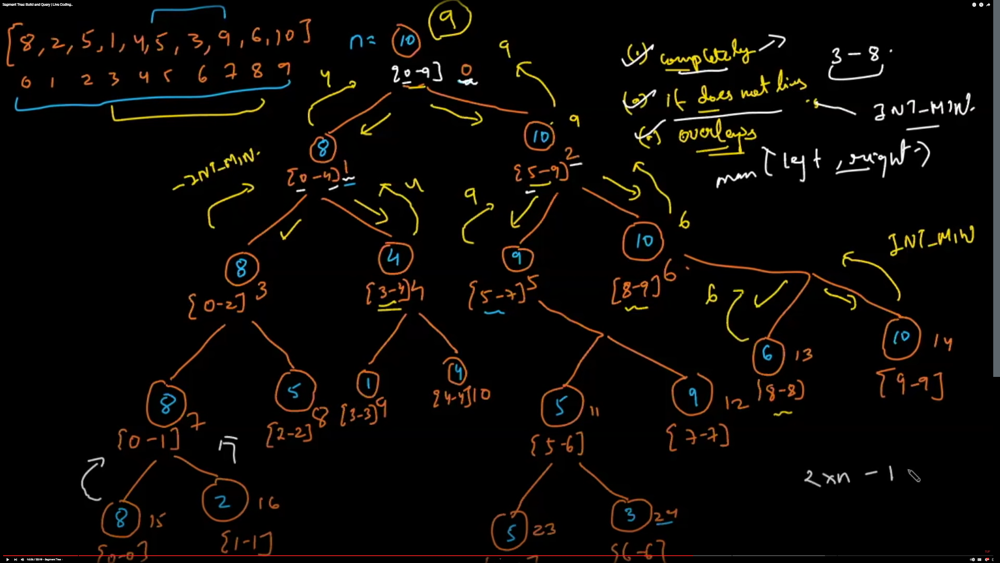
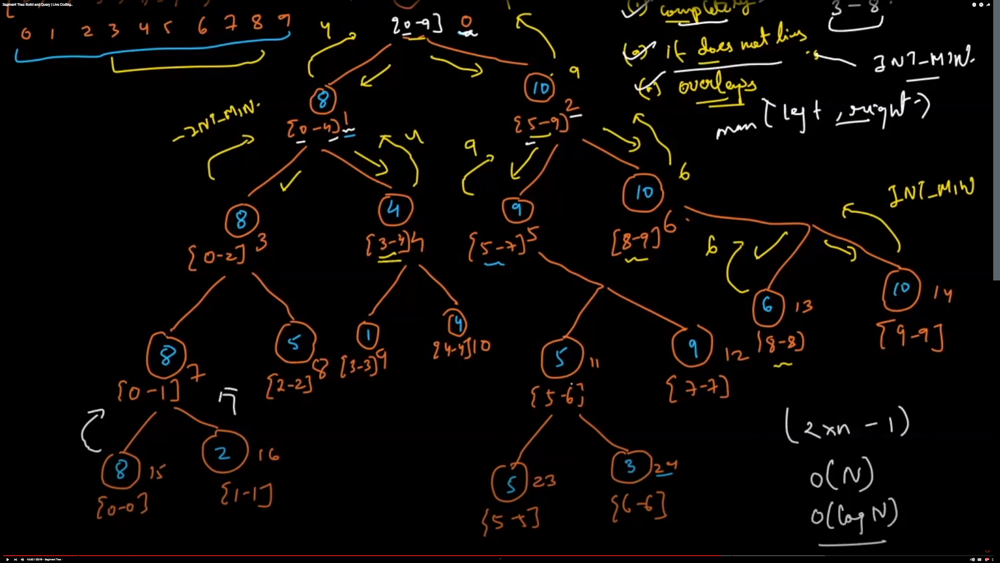
code

public class DSAw {
public static void main(String[] args) {
int nums[]= {8,2,5,1,4,5,3,9,6,10};
SegmentTree segmentTree = new SegmentTree(nums);
segmentTree.build(0,0, nums.length-1);
int ans= segmentTree.query(0,0,nums.length-1,5,7);
System.out.println(ans);
}
}
class SegmentTree{
int segment[];
int inputArray[];
SegmentTree(int input[]){
this.segment = new int[4*100005];
this.inputArray =input;
}
void build(int ind,int l,int r){
if(l==r){
segment[ind]= inputArray[l];
return;
}
int mid=(l+r)>>1;
build(2*ind+1,l,mid);
build(2*ind+2,mid+1,r);
segment[ind]=Math.max(segment[2*ind+1],segment[2*ind+2]);
}
int query(int ind,int low,int high,int l,int r){
//fall in betw
if(low>=l && high<=r) return segment[ind];
//cross not falls
if(low>r || high<l) return Integer.MIN_VALUE;
//over laps
int mid = (low+high)>>1;
int left = query(2*ind+1,low,mid,l,r);
int right = query(2*ind+2,mid+1,high,l,r);
return Math.max(left,right);
}
}
# detect a cycle using any traversal
public boolean isCycle(int V, ArrayList<ArrayList<Integer>> adj) {
int vis[] = new int[V];
for(int i=0;i<V;i++){
if(vis[i]==0)
if(bfs(i,vis,adj)) return true;
}
return false;
}
boolean dfs(int i,int par,int vis[],ArrayList<ArrayList<Integer>> adj){
vis[i]=1;
for(int j:adj.get(i)){
if(vis[j]==0){
if(dfs(j,i,vis,adj)) return true;
}else if(j!=par) return true;
}return false;
}
boolean bfs(int i,int vis[],ArrayList<ArrayList<Integer>> adj){
vis[i]=1;//mark
Queue<int[]> q= new LinkedList<>();
q.add(new int[]{i,-1});//process
while(!q.isEmpty()){
int node=q.peek()[0];
int pr=q.peek()[1];
q.remove();
for(int idx:adj.get(node)){
if(vis[idx]==0){
vis[idx]=1;
q.add(new int[]{idx,node});
}
else if(pr!=idx ) return true;
}
}return false;
}detect a cycle in DAG
public boolean isCyclic(int V, ArrayList<ArrayList> adj) {
int v[] = new int[V];
for(int i=0;i<V;i++){
for(int k:adj.get(i)){
v[k]++;
}
}
Queue q = new LinkedList<>();
for(int i=0;i<V;i++){
if(v[i]==0) q.add(i);
}
int x=0;
while(!q.isEmpty()){
int nod=q.poll();
x++;
for(int k:adj.get(nod)){
v[k]--;
if(v[k]==0) q.add(k);
}
}
if(x==V) return false;
return true;
}
boolean dfs(int i,int v[],ArrayList<ArrayList<Integer>> adj){
// v[i]=1;
v[i]=2;
for(int k:adj.get(i)){
if(v[k]==0){
if(dfs(k,v,adj)) return true;
}
else if(v[k]==2) return true;
}
v[i]=1;
return false;
}Top sort is an algorithm used to sort a directed acyclic graph (AG) in a specific order. The identification of a topological sort algorithm can include the following:
Input: The input to the algorithm is a directed acyclic graph (DAG).
Output: The output of the algorithm is a linear ordering of the vertices of the DAG such that for every directed edge (u, v), vertex u comes before vertex v in the ordering.
Algorithm: The algorithm typically involves visiting each vertex in the DAG and adding it to the output list in a specific order. The order is determined by the dependencies between the vertices, with vertices that have no incoming edges added first.
Complexity: The time complexity of the algorithm is typically O(V+E), where V is the number of vertices and E is the number of edges in the DAG.
Applications: Topological sort is used in many applications, including task scheduling, dependency resolution, and data processing.
Variations: There are several variations of the topological sort algorithm, including depth-first search (DFS) and breadth-first search (BFS) approaches.
Overall, the identification of a topological sort algorithm includes its input and output, the algorithm itself, its time complexity, and its applications.
java version features
Java 1.0 (1996):
Basic language features such as classes, objects, and interfaces
Garbage collection
Multi-threading support
Applet support for web browsers
Java 1.1 (1997):
Inner classes
JavaBeans
JDBC (Java Database Connectivity)
RMI (Remote Method Invocation)
Java 1.2 (1998):
Collections framework
Swing GUI toolkit
JIT (Just-In-Time) compiler
Java Naming and Directory Interface (JNDI)
Java 1.3 (2000):
HotSpot JVM (Java Virtual Machine)
Java Sound API
Java Platform Debugger Architecture (JPDA)
Java Web Start
Java 1.4 (2002):
Assertions
Regular expressions
NIO (New I/O)
XML processing with JAXP (Java API for XML Processing)
Java 5 (2004):
Generics
Enhanced for loop
Autoboxing and unboxing
Varargs (variable-length arguments)
Annotations
Java 6 (2006):
Scripting support with JSR 223
JDBC 4.0
Pluggable annotations
Improved GUI toolkit
Java 7 (2011):
Switch statement with strings
Try-with-resources statement
Diamond operator
Fork/Join framework for parallel programming
Java 8 (2014):
Lambda expressions
Stream API
Date and Time API
Nashorn JavaScript engine
Java 9 (2017):
Modularization with Jigsaw
JShell (Java Shell)
Reactive Streams API
HTTP/2 client
Java 10 (2018):
Local variable type inference
Garbage collector interface
Application Class-Data Sharing
Java 11 (2018):
HTTP client API
Launch single-file source-code programs
Flight Recorder
ZGC (Z Garbage Collector)
Java 12 (2019):
Switch expressions
Microbenchmark suite
JVM constants API
Java 13 (2019):
Text blocks
Dynamic CDS archives
ZGC uncommit
Java 14 (2020):
Records
Pattern matching for instanceof
Helpful NullPointerExceptions
Java 15 (2020):
Sealed classes
Hidden classes
Text blocks improvements
Java 16 (2021):
Records improvements
Pattern matching for switch
Vector API (incubator)
Java 17 (2021):
Sealed classes improvements
Strongly encapsulated JDK internals
Foreign function and memory API (incubator)
Java 18 (expected in 2022):
Records improvements
Pattern matching for switch
Vector API (incubator)
Java 19 (expected in 2023):
Enhanced pattern matching
Enhanced switch expressions
Enhanced nullability annotations
Java 20 (expected in 2024):
Enhanced vector API
Enhanced pattern matching for instanceof
Enhanced switch expressions
Note that the features for Java 18 to 20 are not yet finalized and may change before their release.
Java provides several built-in data structures that can be used to store and manipulate data. Here are some of the most commonly used data structures in Java:
Arrays: Arrays are a fixed-size collection of elements of the same data type. They can be used to store and manipulate data in a linear fashion.
ArrayList: ArrayList is a dynamic array implementation that can grow or shrink in size as needed. It provides methods for adding, removing, and accessing elements.
LinkedList: LinkedList is a data structure that consists of a sequence of nodes, each containing a reference to the next node in the sequence. It provides methods for adding, removing, and accessing elements.
Stack: Stack is a data structure that follows the Last-In-First-Out (LIFO) principle. It provides methods for pushing elements onto the stack and popping elements off the stack.
Queue: Queue is a data structure that follows the First-In-First-Out (FIFO) principle. It provides methods for adding elements to the back of the queue and removing elements from the front of the queue.
PriorityQueue: PriorityQueue is a queue implementation that orders elements based on their priority. It provides methods for adding and removing elements based on their priority.
HashSet: HashSet is a set implementation that stores elements in no particular order and does not allow duplicates. It provides methods for adding, removing, and checking for the presence of elements.
HashMap: HashMap is a map implementation that stores key-value pairs. It provides methods for adding, removing, and accessing elements based on their keys.
TreeMap: TreeMap is a map implementation that orders elements based on their keys. It provides methods for adding, removing, and accessing elements based on their keys.
These are just some of the most commonly used data structures in Java. There are many other data structures available in Java, such as TreeSet, LinkedHashMap, and ConcurrentHashMap, that can be used for specific use cases.
LinkedList, ArrayDeque, and Vector are all data structures in Java that can be to store and manipulate collections of elements. Here's a brief overview of each:
LinkedList: LinkedList is a data structure that consists of a sequence of nodes, each containing a reference to the next node in the sequence. It provides methods for adding, removing, and accessing elements. LinkedList is a dynamic data structure, which means that it can grow or shrink in size as needed. However, accessing elements in a LinkedList can be slower than accessing elements in an ArrayList because each element must be traversed sequentially.
ArrayDeque: ArrayDeque is a double-ended queue implementation that allows elements to be added or removed from both ends of the queue. It provides methods for adding, removing, and accessing elements from the front and back of the queue. ArrayDeque is implemented as a resizable array, which means that it can grow or shrink in size as needed. Accessing elements in an ArrayDeque is faster than accessing elements in a LinkedList because elements can be accessed directly using an index.
Vector: Vector is a dynamic array implementation that can grow or shrink in size as needed. It provides methods for adding, removing, and accessing elements. Vector is similar to ArrayList, but it is synchronized, which means that it can be used safely in multi-threaded environments. However, this synchronization can make Vector slower than ArrayList in single-threaded environments.
In summary, LinkedList is a data structure that consists of a sequence of nodes, ArrayDeque is a double-ended queue implementation that allows elements to be added or removed from both ends of the queue, and Vector is a dynamic array implementation that is synchronized for use in multi-threaded environments. Each data structure has its own strengths and weaknesses, and the choice of which one to use depends on the specific use case.
What is the difference between an abstract class and an interface?
Answer: An abstract class is a class that cannot be instantiated and is used as a base class for other classes. It can contain both abstract and non-abstract methods. An interface is a collection of abstract methods that can be implemented by any class. An interface cannot contain any implementation code.
What is the difference between a stack and a queue?
Answer: A stack is a data structure that follows the Last-In-First-Out (LIFO) principle, while a queue is a data structure that follows the First-In-First-Out (FIFO) principle. In a stack, elements are added and removed from the top of the stack, while in a queue, elements are added to the back of the queue and removed from the front of the queue.
What is the difference between a checked and an unchecked exception?
Answer: A checked exception is an exception that is checked at compile-time and must be handled by the programmer. An unchecked exception is an exception that is not checked at compile-time and can be handled by the JVM.
What is the difference between a HashMap and a TreeMap?
Answer: A HashMap is a map implementation that stores key-value pairs in no particular order and provides constant-time performance for basic operations. A TreeMap is a map implementation that stores key-value pairs in sorted order and provides logarithmic-time performance for basic operations.
What is the difference between a thread and a process?
Answer: A process is an instance of a program that is running on a computer, while a thread is a unit of execution within a process. A process can have multiple threads, each of which can execute concurrently.
What is the difference between a static and a non-static method?
Answer: A static method is a method that belongs to a class and can be called without creating an instance of the class. A non-static method is a method that belongs to an instance of a class and can only be called on an instance of the class.
What is the difference between a StringBuilder and a StringBuffer?
Answer: A StringBuilder is a mutable sequence of characters that is not thread-safe, while a StringBuffer is a mutable sequence of characters that is thread-safe. In general, StringBuilder is faster than StringBuffer, but StringBuffer is safer to use in multi-threaded environments.
What is the difference between a synchronized method and a synchronized block?
Answer: A synchronized method is a method that is synchronized on the object instance, while a synchronized block is a block of code that is synchronized on a specific object. Synchronized methods can be used to synchronize access to instance variables, while synchronized blocks can be used to synchronize access to specific blocks of code.
What is multi-threading and how does it work in Java?
Answer: Multi-threading is the ability of a program to execute multiple threads concurrently. In Java, multi-threading is implemented using the Thread class and the Runnable interface. A thread is a separate path of execution within a program, and multiple threads can run concurrently within the same program.
What is a deadlock and how can it be prevented?
Answer: A deadlock is a situation where two or more threads are blocked waiting for each other to release resources. Deadlocks can be prevented by using techniques such as resource ordering, timeout mechanisms, and avoiding circular wait conditions.
What is a data structure and what are some common data structures used in Java?
Answer: A data structure is a way of organizing and storing data in a computer program. Some common data structures used in Java include arrays, ArrayLists, LinkedLists, Stacks, Queues, HashMaps, and TreeMaps.
What is a design pattern and what are some common design patterns used in Java?
Answer: A design pattern is a reusable solution to a common software design problem. Some common design patterns used in Java include the Singleton pattern, Factory pattern, Observer pattern, and Decorator pattern.
principles are a set of design principles that are used to create software that is easy to maintain, extend, and modify. The SOLID principles are:
Single Responsibility Principle (SRP): A class should have only one reason to change.
Example: A class that handles user authentication should only be responsible for authentication and not for other unrelated tasks such as sending emails or generating reports.
Open/Closed Principle (OCP): A class should be open for extension but closed for modification.
Example: A class that calculates the area of a shape should be open for extension to support new shapes, but closed for modification to avoid changing the existing code.
Liskov Substitution Principle (LSP): Subtypes should be substitutable for their base types.
Example: A subclass of a shape class should be able to be used in place of the base shape class without affecting the correctness of the program.
Interface Segregation Principle (ISP): Clients should not be forced to depend on interfaces they do not use.
Example: A class that implements an interface should only implement the methods that it needs, and not be forced to implement methods that it does not need.
Dependency Inversion Principle (DIP): High-level modules should not depend on low-level modules. Both should depend on abstractions.
Example: A class that sends emails should depend on an abstraction such as an interface, rather than a concrete implementation such as a specific email service.
Here are two examples for each of the SOLID principles:
Single Responsibility Principle (SRP):
Example 1: A class that handles user authentication should only be responsible for authentication and not for other unrelated tasks such as sending emails or generating reports.
Example 2: A class that handles database connections should only be responsible for connecting to the database and not for executing queries or managing transactions.
Open/Closed Principle (OCP):
Example 1: A class that calculates the area of a shape should be open for extension to support new shapes, but closed for modification to avoid changing the existing code.
Example 2: A class that generates reports should be open for extension to support new report formats, but closed for modification to avoid changing the existing code.
Liskov Substitution Principle (LSP):
Example 1: A subclass of a shape class should be able to be used in place of the base shape class without affecting the correctness of the program.
Example 2: A subclass of a vehicle class should be able to be used in place of the base vehicle class without affecting the correctness of the program.
Interface Segregation Principle (ISP):
Example 1: A class that implements an interface should only implement the methods that it needs, and not be forced to implement methods that it does not need.
Example 2: A class that handles user authentication should only implement the methods that are related to authentication, and not be forced to implement methods that are related to other tasks such as sending emails or generating reports.
Dependency Inversion Principle (DIP):
Example 1: A class that sends emails should depend on an abstraction such as an interface, rather than a concrete implementation such as a specific email service.
Example 2: A class that handles database connections should depend on an abstraction such as an interface, rather than a concrete implementation such as a specific database driver.
Here are some common microservices interview questions and answers:
What are microservices?
Answer: Microservices are a software architecture pattern that involves breaking down a large monolithic application into smaller, independent services that can be developed, deployed, and scaled independently.
What are the benefits of using microservices?
Answer: Some benefits of using microservices include increased agility, scalability, and resilience, as well as improved fault isolation and easier maintenance.
What are some common challenges of using microservices?
Answer: Some common challenges of using microservices include increased complexity, the need for effective service discovery and communication, and the need for effective monitoring and management of the services.
What is service discovery and how does it work in microservices?
Answer: Service discovery is the process of locating and connecting to services in a microservices architecture. It typically involves a service registry that maintains a list of available services and their locations, and a service discovery mechanism that allows services to locate and connect to each other.
What is API gateway and how does it work in microservices?
Answer: An API gateway is a server that acts as an entry point for a microservices architecture. It typically handles tasks such as authentication, routing, and load balancing, and provides a unified interface for clients to access the services.
What is circuit breaker pattern and how does it work in microservices?
Answer: The circuit breaker pattern is a design pattern that is used to handle failures in a microservices architecture. It involves wrapping calls to a service in a circuit breaker that monitors the service for failures and opens the circuit if the service fails repeatedly. This allows the system to gracefully degrade and recover from failures.
What is containerization and how does it work in microservices?
Answer: Containerization is the process of packaging an application and its dependencies into a container that can be run consistently across different environments. Containerization is often used in microservices architectures to provide a consistent and portable environment for running services.
Containerization: Containerization is the process of packaging an application and its dependencies into a container that can be run consistently across different environments. Containers provide a lightweight and portable way to run applications, and they can be easily moved between different environments such as development, testing, and production. Containerization is often used in microservices architectures to provide a consistent and portable environment for running services.
Service discovery: Service discovery is the process of locating and connecting to services in a microservices architecture. In a microservices architecture, services are typically deployed independently and may be running on different hosts or containers. Service discovery involves a service registry that maintains a list of available services and their locations, and a service discovery mechanism that allows services to locate and connect to each other. Common service discovery mechanisms include DNS-based discovery, client-side discovery, and server-side discovery.
API gateway design: An API gateway is a server that acts as an entry point for a microservices architecture. It typically handles tasks such as authentication, routing, and load balancing, and provides a unified interface for clients to access the services. API gateway design involves designing the API gateway to handle these tasks effectively and efficiently. This may involve using techniques such as caching, rate limiting, and circuit breaking to improve performance and reliability. API gateway design also involves designing the API itself to be easy to use and understand, with clear documentation and consistent naming conventions.
In summary, containerization provides a lightweight and portable way to run applications, service discovery allows services to locate and connect to each other in a microservices architecture, and API gateway design involves designing the API gateway to handle tasks such as authentication, routing, and load balancing effectively and efficiently. These topics are all important for building scalable and resilient microservices architectures.
Here are some hard Spring Boot interview questions:
What is Spring Boot and how does it differ from Spring Framework?
Answer: Spring Boot is a framework that is built on top of the Spring Framework and provides a simplified way to create and deploy Spring-based applications. Spring Boot includes many features that are commonly used in Spring applications, such as auto-configuration, embedded servers, and production-ready metrics and health checks.
What is auto-configuration in Spring Boot?
Answer: Auto-configuration is a feature of Spring Boot that automatically configures the Spring application based on the dependencies that are present on the classpath. Auto-configuration can save time and reduce the amount of boilerplate code that is required to configure the application.
What is the difference between @Component, @Service, and @Repository annotations in Spring Boot?
Answer: @Component is a generic annotation that is used to mark a class as a Spring component. @Service is a specialization of @Component that is used to mark a class as a service component. @Repository is a specialization of @Component that is used to mark a class as a repository component. While all three annotations are used to mark a class as a Spring component, they are used to indicate different types of components.
What is Spring Data JPA and how does it work?
Answer: Spring Data JPA is a framework that provides a simplified way to work with JPA (Java Persistence API) in Spring applications. Spring Data JPA includes many features that are commonly used in JPA applications, such as CRUD operations, pagination, and sorting. Spring Data JPA also provides a repository abstraction that allows developers to work with entities in a more object-oriented way.
What is Spring Security and how does it work?
Answer: Spring Security is a framework that provides authentication and authorization services for Spring applications. Spring Security includes many features that are commonly used in security applications, such as authentication providers, authorization rules, and access control lists. Spring Security also provides integration with other Spring frameworks, such as Spring MVC and Spring Boot.
What is Spring Cloud and how does it work?
Answer: Spring Cloud is a framework that provides a set of tools and libraries for building cloud-native applications with Spring. Spring Cloud includes many features that are commonly used in cloud applications, such as service discovery, configuration management, and circuit breaking. Spring Cloud also provides integration with other cloud technologies, such as Netflix OSS and Kubernetes.
Creational Design Patterns:
Singleton: Ensures that a class has only one instance and provides a global point of access to it. Example: A logger class that needs to be accessed from multiple parts of the application.
Factory Method: Defines an interface for creating objects, but allows subclasses to decide which class to instantiate. Example: A pizza restaurant that has different types of pizzas, but the customer can choose which toppings to add.
Here explanations of all Creational design patterns with two examples each:
1 Abstract Factory Pattern:
Provides an interface for creating families of related or dependent objects without specifying their concrete classes.
Example 1: A class that represents a GUI toolkit, where the abstract factory can create different types of buttons, text boxes, and other GUI components depending on the platform.
Example 2: A class that represents a database connection, where the abstract factory can create different types of connections depending on the database vendor.
Builder Pattern:
Separates the construction of a complex object from its representation, allowing the same construction process to create different representations.
Example 1: A class that represents a pizza, where the builder can create different types of pizzas with different toppings and crusts.
Example 2: A class that represents a car, where the builder can create different types of cars with different engines, transmissions, and options.
Factory Method Pattern:
Defines an interface for creating objects, but allows subclasses to decide which class to instantiate.
Example 1: A pizza restaurant that has different types of pizzas, but the customer can choose which toppings to add.
Example 2: A class that represents a logger, where the factory method can create different types of loggers depending on the logging level.
Prototype Pattern:
Creates new objects by cloning existing ones, avoiding the need to create new objects from scratch.
Example 1: A class that represents a document, where the prototype can be used to create new documents with the same structure and content as an existing document.
Example 2: A class that represents a game character, where the prototype can be used to create new characters with the same attributes and abilities as an existing character.
Singleton Pattern:
Ensures that a class has only one instance and provides a global point of access to it.
Example 1: A class that represents a database connection pool, where the singleton ensures that only one pool is created and shared among all clients.
Example 2: A class that represents a configuration manager, where the singleton ensures that only one instance of the configuration is used throughout the application.
Structural Design Patterns:
Adapter: Converts the interface of a class into another interface that clients expect. Example: A class that reads data from a file and converts it into a format that can be used by another class.
Decorator: Adds new functionality to an existing object without changing its structure. Example: A class that adds a border or a shadow to an image.
Here are explanations of all Structural design patterns with two examples each:
Adapter Pattern:
Converts the interface of a class into another interface that clients expect.
Example 1: A class that reads data from a file and converts it into a format that can be used by another class.
Example 2: A class that converts data from one format to another, such as from XML to JSON.
Bridge Pattern:
Decouples an abstraction from its implementation so that the two can vary independently.
Example 1: A class that provides an interface for drawing shapes, but allows different implementations for different types of shapes.
Example 2: A class that provides an interface for sending messages, but allows different implementations for different types of messaging systems.
Composite Pattern:
Composes objects into tree structures to represent part-whole hierarchies.
Example 1: A class that represents a directory structure, where each directory can contain files or other directories.
Example 2: A class that represents a menu structure, where each menu item can contain sub-menus or other menu items.
Decorator Pattern:
Adds new functionality to an existing object without changing its structure.
Example 1: A class that adds a border or a shadow to an image.
Example 2: A class that adds logging or caching functionality to a method.
Facade Pattern:
Provides a simplified interface to a complex system of classes.
Example 1: A class that provides a simplified interface to a database, hiding the complexity of the underlying SQL queries.
Example 2: A class that provides a simplified interface to a messaging system, hiding the complexity of the underlying message formats and protocols.
Flyweight Pattern:
Shares objects to support large numbers of fine-grained objects efficiently.
Example 1: A class that represents a color, where multiple objects can share the same color instance to save memory.
Example 2: A class that represents a font, where multiple objects can share the same font instance to save memory.
Proxy Pattern:
Provides a surrogate or placeholder for another object to control access to it.
Example 1: A class that represents a remote object, where the proxy object handles the communication with the remote object.
Example 2: A class that represents a large object, where the proxy object loads the object on demand to save memory.
Behavioral Design Patterns:
Observer: Defines a one-to-many dependency between objects, so that when one object changes state, all its dependents are notified and updated automatically. Example: A weather station that notifies its subscribers when the temperature changes.
Strategy: Defines a family of algorithms, encapsulates each one, and makes them interchangeable. Example: A class that calculates the shipping cost based on the weight of the package, but allows different algorithms to be used for different shipping methods.
Here are explanations of all Behavioral design patterns with two examples each:
Chain of Responsibility Pattern:
Allows a request to be passed through a chain of handlers until one of them handles the request.
Example 1: A class that handles HTTP requests, where each handler in the chain checks if it can handle the request and passes it to the next handler if it can't.
Example 2: A class that handles exceptions, where each handler in the chain checks if it can handle the exception and passes it to the next handler if it can't.
Command Pattern:
Encapsulates a request as an object, allowing it to be queued, logged, or undone.
Example 1: A class that represents a button in a user interface, where each button has a command object that is executed when the button is clicked.
Example 2: A class that represents a transaction in a database, where each transaction is represented by a command object that can be executed or rolled back.
Interpreter Pattern:
Defines a grammar for a language and provides an interpreter to interpret the language.
Example 1: A class that represents a regular expression, where the interpreter can match the regular expression against a string.
Example 2: A class that represents a mathematical expression, where the interpreter can evaluate the expression and return the result.
Iterator Pattern:
Provides a way to access the elements of an aggregate object sequentially without exposing its underlying representation.
Example 1: A class that represents a list of items, where the iterator can be used to iterate over the items in the list.
Example 2: A class that represents a tree structure, where the iterator can be used to traverse the nodes in the tree.
Mediator Pattern:
Defines an object that encapsulates how a set of objects interact, promoting loose coupling between the objects.
Example 1: A class that represents a chat room, where each user object communicates with the chat room object instead of directly with other user objects.
Example 2: A class that represents a traffic control system, where each vehicle object communicates with the traffic control object instead of directly with other vehicle objects.
Memento Pattern:
Provides a way to capture and restore an object's internal state.
Example 1: A class that represents a text editor, where the memento object can be used to save and restore the editor's state.
Example 2: A class that represents a game, where the memento object can be used to save and restore the game's state.
Observer Pattern:
Defines a one-to-many dependency between objects, so that when one object changes state, all its dependents are notified and updated automatically.
Example 1: A class that represents a weather station, where the observer objects are notified when the temperature changes.
Example 2: A class that represents a stock market, where the observer objects are notified when the price of a stock changes.
State Pattern:
Allows an object to alter its behavior when its internal state changes.
Example 1: A class that represents a vending machine, where the behavior of the machine changes depending on whether it is in the "idle", "dispensing", or "out of stock" state.
Example 2: A class that represents a game character, where the behavior of the character changes depending on whether it is in the "standing", "walking", or "attacking" state.
Strategy Pattern:
Defines a family of algorithms, encapsulates each one, and makes them interchangeable.
Example 1: A class that calculates the shipping cost based on the weight of the package, but allows different algorithms to be used for different shipping methods.
Example 2: A class that sorts a list of items, but allows different algorithms to be used for different types of items.
Template Method Pattern:
Defines the skeleton of an algorithm in a method, deferring some steps to subclasses.
Example 1: A class that represents a game, where the template method defines the basic structure of the game, but allows subclasses to implement specific game rules.
Example 2: A class that represents a report, where the template method defines the basic structure of the report, but allows subclasses to implement specific report sections.
Concurrency Design Patterns:
Producer-Consumer: A pattern where one or more threads produce data, and one or more threads consume the data. Example: A queue that is used to transfer data between two threads.
Read-Write Lock: A pattern that allows multiple readers to access a shared resource simultaneously, but only one writer at a time. Example: A database that allows multiple users to read data, but only one user to write data at a time.
Architectural Design Patterns:
Model-View-Controller (MVC): Separates the presentation layer, the business logic layer, and the data storage layer. Example: A web application that separates the user interface, the application logic, and the database.
Microservices: A pattern where a large application is broken down into smaller, independent services that can be developed, deployed, and scaled independently. Example: An e-commerce website that has separate services for product catalog, shopping cart, and payment processing.
public static void quickSort(int[] arr, int left, int right) {
if (left < right) {
// Choose a pivot element
int pivotIndex = partition(arr, left, right);
// Recursively sort the left and right subarrays
quickSort(arr, left, pivotIndex - 1);
quickSort(arr, pivotIndex + 1, right);
}
}
private static int partition(int[] arr, int left, int right) {
// Choose the rightmost element as the pivot
int pivot = arr[right];
// Index of the first element that is greater than the pivot
int i = left - 1;
// Iterate over the subarray and swap elements as necessary
for (int j = left; j < right; j++) {
if (arr[j] < pivot) {
i++;
swap(arr, i, j);
}
}
// Place the pivot in its correct position
swap(arr, i + 1, right);
// Return the index of the pivot
return i + 1;
}
private static void swap(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}public static void mergeSort(int[] arr, int left, int right) {
if (left < right) {
// Find the middle index
int mid = (left + right) / 2;
// Recursively sort the left and right subarrays
mergeSort(arr, left, mid);
mergeSort(arr, mid + 1, right);
// Merge the sorted subarrays
merge(arr, left, mid, right);
}
}
private static void merge(int[] arr, int left, int mid, int right) {
// Create temporary arrays for the left and right subarrays
int[] leftArr = Arrays.copyOfRange(arr, left, mid + 1);
int[] rightArr = Arrays.copyOfRange(arr, mid + 1, right + 1);
// Merge the left and right subarrays
int i = 0, j = 0, k = left;
while (i < leftArr.length && j < rightArr.length) {
if (leftArr[i] <= rightArr[j]) {
arr[k++] = leftArr[i++];
} else {
arr[k++] = rightArr[j++];
}
}
// Copy any remaining elements from the left subarray
while (i < leftArr.length) {
arr[k++] = leftArr[i++];
}
// Copy any remaining elements from the right subarray
while (j < rightArr.length) {
arr[k++] = rightArr[j++];
}
}here's an implementation of the Dutch National Flag algorithm in Java with comments
public static voidchFlag(int[] arr) {
int low = 0;
int mid = 0;
int high = arr.length - 1;
Copy code// Iterate over the array and swap elements as necessary
while (mid <= high) {
if (arr[mid] == 0) {
// If the current element is 0, swap it with the element at the low index
swap(arr, low, mid);
low++;
mid++;
} else if (arr[mid] == 1) {
// If the current element is 1, leave it in place and move to the next element
mid++;
} else {
// If the current element is 2, swap it with the element at the high index
swap(arr, mid, high);
high--;
}
}
}
private static void swap(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}here are the implementations of Radix Sort and Counting Sort in Java comments:
public static void radixSort(int[] arr) {
// Find the maximum element in the array
int max = Arrays.stream(arr).max().getAsInt();
// Perform counting sort for each digit
for (int exp = 1; max / exp > 0; exp *= 10) {
countingSort(arr, exp);
}
}
private static void countingSort(int[] arr, int exp) {
int n = arr.length;
int[] output = new int[n];
int[] count = new int[10];
// Count the frequency of each digit
for (int i = 0; i < n; i++) {
int digit = (arr[i] / exp) % 10;
count[digit]++;
}
// Calculate the cumulative count of each digit
for (int i = 1; i < 10; i++) {
count[i] += count[i - 1];
}
// Build the output array
for (int i = n - 1; i >= 0; i--) {
int digit = (arr[i] / exp) % 10;
output[count[digit] - 1] = arr[i];
count[digit]--;
}
// Copy the output array to the input array
System.arraycopy(output, 0, arr, 0, n);
}
Counting Sort:
public static void countingSort(int[] arr) {
int n = arr.length;
int[] output = new int[n];
int[] count = new int[Arrays.stream(arr).max().getAsInt() + 1];
// Count the frequency of each element
for (int i = 0; i < n; i++) {
count[arr[i]]++;
}
// Calculate the cumulative count of each element
for (int i = 1; i < count.length; i++) {
count[i] += count[i - 1];
}
// Build the output array
for (int i = n - 1; i >= 0; i--) {
output[count[arr[i]] - 1] = arr[i];
count[arr[i]]--;
}
// Copy the output array to the input array
System.arraycopy(output, 0, arr, 0, n);
}
Note that this implementation assumes that the elements in the array are non-negative integers. If the elements are not non-negative integers, we need to modify the implementation accordingly.
Here are some common recurrence relations used in dynamic programming:Fibonacci sequence F(n) = F(n-1) + F(n-2), with base cases F(0) = 0 and F(1) = 1
Longest common subsequence: LCS(i, j) = LCS(i-1, j-1) + 1 if s1[i] = s2[j], otherwise LCS(i, j) = max(LCS(i-1, j), LCS(i, j-1)), with base cases LCS(i, 0) = 0 and LCS(0, j) = 0
Knapsack problem: K(i, w) = max(K(i-1, w), K(i-1, w-wi) + vi), with base cases K(0, w) = 0 and K(i, 0) = 0
Edit distance: ED(i, j) = ED(i-1, j-1) if s1[i] = s2[j], otherwise ED(i, j) = min(ED(i-1, j), ED(i, j-1), ED(i-1, j-1)) + 1, with base cases ED(i, 0) = i and ED(0, j) = j
Coin change problem: C(i, j) = C(i-1, j) + C(i, j-ci) if j >= ci, otherwise C(i, j) = C(i-1, j), with base cases C(0, j) = 0 and C(i, 0) = 1
Maximum subarray: M(i) = max(M(i-1) + A[i], A[i]), with base case M(0) = A[0]
Matrix chain multiplication: M(i, j) = min(M(i, k) + M(k+1, j) + p[i-1] * p[k] * p[j]) for all i <= k < j, with base cases M(i, i) = 0
These recurrence relations can be used to solve a variety of dynamic programming problems
By understanding these recurrence relations and how to apply them, you can solve dynamic programming problems efficiently and effectively
public int fibonacci(int n) {
if (n == 0) {
return 0;
}
if (n == 1) {
return 1;
}
int[] dp = new int[n+1];
dp[0] = 0;
dp[1] = 1;
for (int i = 2; i <= n; i++) {
dp[i] = dp[i-1] + dp[i-2];
}
return dp[n];
}
public int longestCommonSubsequence(String s1, String s2) {
int m = s1.length();
int n = s2.length();
int[][] dp = new int[m+1][n+1];
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if (s1.charAt(i-1) == s2.charAt(j-1)) {
dp[i][j] = dp[i-1][j-1] + 1;
} else {
dp[i][j] = Math.max(dp[i-1][j], dp[i][j-1]);
}
}
}
return dp[m][n];
}
public int knapsack(int[] weights, int[] values, int capacity) {
int n = weights.length;
int[][] dp = new int[n+1][capacity+1];
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= capacity; j++) {
if (weights[i-1] <= j) {
dp[i][j] = Math.max(dp[i-1][j], dp[i-1][j-weights[i-1]] + values[i-1]);
} else {
dp[i][j] = dp[i-1][j];
}
}
}
return dp[n][capacity];
}
public int editDistance(String s1, String s2) {
int m = s1.length();
int n = s2.length();
int[][] dp = new int[m+1][n+1];
for (int i = 0; i <= m; i++) {
dp[i][0] = i;
}
for (int j = 0; j <= n; j++) {
dp[0][j] = j;
}
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if (s1.charAt(i-1) == s2.charAt(j-1)) {
dp[i][j] = dp[i-1][j-1];
} else {
dp[i][j] = Math.min(dp[i-1][j], Math.min(dp[i][j-1], dp[i-1][j-1])) + 1;
}
}
}
return dp[m][n];
}
public int coinChange(int[] coins, int amount) {
int n = coins.length;
int[][] dp = new int[n+1][amount+1];
for (int i = 0; i <= n; i++) {
dp[i][0] = 1;
}
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= amount; j++) {
if (coins[i-1] <= j) {
dp[i][j] = dp[i-1][j] + dp[i][j-coins[i-1]];
} else {
dp[i][j] = dp[i-1][j];
}
}
}
return dp[n][amount];
}
public int maxSubarray(int[] nums) {
int n = nums.length;
int[] dp = new int[n];
dp[0] = nums[0];
int maxSum = dp[0];
for (int i = 1; i < n; i++) {
dp[i] = Math.max(dp[i-1] + nums[i], nums[i]);
maxSum = Math.max(maxSum, dp[i]);
}
return maxSum;
}
int matrixChainMultiplication(int[] p) {
int n = p.length - 1;
int[][] dp = new int[n][n];
for (int len = 2; len <= n; len++) {
for (int i = 0; i <= n - len; i++) {
int j = i + len - 1;
dp[i][j] = Integer.MAX_VALUE;
for (int k = i; k < j; k++) {
dp[i][j] = Math.min(dp[i][j], dp[i][k] + dp[k+1][j] + p[i] * p[k+1] * p[j+1]);
}
}
}
return dp[0][n-1];
}
In this code, p is an array of integers representing the dimensions of the matrices
For example, if p = {10, 20, 30}, then there are two matrices with dimensions 10x20 and 20x30
The goal is to find the minimum number of scalar multiplications needed to multiply these matrices
The code uses a bottom-up approach to fill in the dp table
The outer loop iterates over the length of the chain, from 2 to n
The inner loop iterates over the starting index of the chain, from 0 to n-len
The variable j is set to i + len - 1, which represents the ending index of the chain
The code then iterates over all possible split points k in the chain and computes the cost of multiplying the two resulting subchains
The cost is the sum of the cost of multiplying the two subchains and the cost of multiplying the resulting matrices
The minimum cost is stored in the dp table
Finally, the code returns the minimum cost of multiplying the entire chain of matrices, which is stored in dp[0][n-1]
This code has a time complexity of O(n^3) and a space complexity of O(n^2), where n is the number of matrices in the chain
LCS count + result
public String shortestCommonSupersequence(String s1, String s2) {
// find the LCS of s1 and s2
char lcs[] = lcs(s1,s2).toCharArray();
int i=0,j=0;
StringBuilder sb = new StringBuilder();
// merge s1 and s2 with the LCS
for(char c:lcs){
// add characters from s1 until the LCS character is found
while(s1.charAt(i)!=c) sb.append(s1.charAt(i++));
// add characters from s2 until the LCS character is found
while(s2.charAt(j)!=c) sb.append(s2.charAt(j++));
// add the LCS character
sb.append(c);
i++;
j++;
}
// add any remaining characters from s1 and s2
sb.append(s1.substring(i)).append(s2.substring(j));
// return the merged string
return sb.toString();
}
// helper method to find the LCS of two strings
String lcs(String s1,String s2){
int m = s1.length(),n=s2.length();
int dp[][] = new int[m+1][n+1];
// fill the dp array using dynamic programming
for(int i=1;i<=m;i++){
for(int j=1;j<=n;j++){
if(s1.charAt(i-1)==s2.charAt(j-1)){
dp[i][j]=1+dp[i-1][j-1];
}else dp[i][j]=Math.max(dp[i-1][j],dp[i][j-1]);
}
}
// backtrack from the bottom right corner of the dp array to find the LCS
StringBuilder sb = new StringBuilder();
int i=m,j=n;
while(i>0 && j>0){
if(s1.charAt(i-1)==s2.charAt(j-1)){
sb.append(s1.charAt(i-1));
i--;
j--;
}else if(dp[i-1][j]>dp[i][j-1]) i--;
else j--;
}
// reverse the LCS string and return it
return sb.reverse().toString();
}LIS using binary search
public static int longestIncreasingSubsequence(int arr[]) {
int len=arr.length;
List<Integer> tem = new ArrayList<>();
tem.add(arr[0]);
int cnt=1;
for(int i=1;i<len;i++){
… }else tem.set(lb,arr[i]);
}
}
}return cnt;What is Spring Boot?
Spring Boot is an open-source Java-based framework used to create standalone, production-grade Spring-based applications with minimal configuration.
What are the advantages of using Spring Boot?
Spring Boot provides a number of advantages, including:
Rapid application development with minimal configuration
Embedded servers for easy deployment
Auto-configuration of Spring and third-party libraries
Production-ready features such as metrics, health checks, and externalized configuration
Easy integration with other Spring projects and third-party libraries
What is the difference between Spring and Spring Boot?
Spring is a framework for building Java applications, while Spring Boot is a framework for building standalone, production-grade Spring-based applications with minimal configuration. Spring Boot builds on top of Spring and provides additional features and functionality.
How do you create a Spring Boot application?
You can create a Spring Boot application using the Spring Initializr, which is a web-based tool that generates a project structure and initial configuration for your application based on your specifications.
What is the role of the application.properties (or application.yml) file in Spring Boot?
The application.properties (or application.yml) file is used to configure various aspects of a Spring Boot application, such as the server port, database connection details, logging configuration, and more. Spring Boot provides a number of default properties that can be overridden or extended as needed.
What is Spring Boot Actuator?
Spring Boot Actuator is a sub-project of Spring Boot that provides production-ready features for monitoring and managing your application, such as health checks, metrics, and externalized configuration. Actuator endpoints can be accessed via HTTP or JMX.
What is Spring Boot Starter?
Spring Boot Starter is a set of pre-configured dependencies that provide a specific set of features for your application, such as web, data, security, and more. Starters simplify the process of configuring your application by providing a consistent and opinionated set of defaults.
What is Spring Boot DevTools?
Spring Boot DevTools is a set of tools that provide a faster development experience by enabling features such as automatic restarts, live reload, and remote debugging. DevTools is included as a dependency in Spring Boot applications and can be configured via the application.properties (or application.yml) file.
What is Spring Boot Test?
Spring Boot Test is a set of utilities and annotations for testing Spring Boot applications, such as the @SpringBootTest annotation for integration testing, the @MockBean annotation for mocking dependencies, and the TestRestTemplate for testing RESTful endpoints.
What is Spring Boot Auto-configuration?
Spring Boot Auto-configuration is a feature that automatically configures Spring and third-party libraries based on the dependencies included in your application. Auto-configuration simplifies the process of configuring your application by providing a consistent and opinionated set of defaults.
Here some of the top questions about Spring Security:
What is Spring Security?
Spring Security is a powerful and highly customizable authentication and access-control framework for Java applications. It provides a comprehensive set of security features for web and non-web applications, including authentication, authorization, and session management.
What are the key features of Spring Security?
Spring Security provides a number of key features, including:
Authentication and authorization
Session management
Password hashing and encryption
CSRF protection
Role-based access control
LDAP and Active Directory integration
OAuth and OpenID Connect support
Customizable login and logout pages
How do you configure Spring Security in a Spring Boot application?
You can configure Spring Security in a Spring Boot application by adding the spring-boot-starter-security dependency to your project and creating a configuration class that extends the WebSecurityConfigurerAdapter class. In the configuration class, you can define security rules and customize various aspects of the security framework.
What is the difference between authentication and authorization in Spring Security?
Authentication is the process of verifying the identity of a user, while authorization is the process of determining whether a user has the necessary permissions to access a particular resource. Spring Security provides support for both authentication and authorization.
What is a security filter chain in Spring Security?
A security filter chain is a series of filters that are applied to incoming requests to a Spring Security-enabled application. Each filter performs a specific security-related task, such as authentication, authorization, or CSRF protection. The order of the filters in the chain is important, as it determines the order in which the filters are applied to incoming requests.
What is a UserDetails object in Spring Security?
A UserDetails object is a core interface in Spring Security that represents a user's details, such as their username, password, and authorities. UserDetails objects are used by Spring Security to perform authentication and authorization.
What is a GrantedAuthority object in Spring Security?
A GrantedAuthority object is an interface in Spring Security that represents a user's authority or permission to perform a specific action or access a specific resource. GrantedAuthority objects are used by Spring Security to perform authorization.
What is a security context in Spring Security?
A security context is an object in Spring Security that represents the current security state of a user. The security context contains information such as the user's authentication details and authorities, and is used by Spring Security to perform authorization checks.
What is CSRF protection in Spring Security?
CSRF (Cross-Site Request Forgery) protection is a security feature in Spring Security that prevents malicious websites from executing unauthorized actions on behalf of a user. CSRF protection works by adding a unique token to each form submission, which is then verified on the server side to ensure that the request is legitimate.
What is OAuth in Spring Security?
OAuth is an open standard for authorization that allows users to grant third-party applications access to their resources without sharing their credentials. Spring Security provides support for OAuth 2.0 and OpenID Connect, which are widely used for authentication and authorization in modern web applications.
Here are some of the top questions about microservices:
What are microservices?
Microservices are a software architecture pattern in which complex applications are broken down into smaller, independent services that can be developed, deployed, and scaled independently. Each microservice is responsible for a specific business capability and communicates with other microservices via APIs.
What are the benefits of using microservices?
Microservices provide a number of benefits, including:
Improved scalability and flexibility
Faster development and deployment times
Better fault isolation and resilience
Improved team autonomy and productivity
Easier technology stack upgrades and maintenance
Better alignment with business capabilities and requirements
What are the challenges of using microservices?
Microservices also present a number of challenges, including:
Increased complexity and management overhead
Higher operational costs and infrastructure requirements
Increased network latency and communication overhead
Higher security and compliance risks
Increased testing and monitoring requirements
Higher skill requirements for development and operations teams
What is the difference between monolithic and microservices architectures?
Monolithic architectures are characterized by a single, large application that contains all the business logic and functionality. Microservices architectures, on the other hand, are characterized by smaller, independent services that communicate with each other via APIs.
What is the role of APIs in microservices architectures?
APIs are a critical component of microservices architectures, as they enable communication between the different microservices. APIs provide a standardized way for microservices to interact with each other, and can be used to enforce security, versioning, and other policies.
What is service discovery in microservices architectures?
Service discovery is the process of automatically locating and connecting to the different microservices in a distributed system. Service discovery is typically implemented using a registry or discovery service, which maintains a list of available services and their locations.
What is containerization in microservices architectures?
Containerization is a technology that enables the packaging and deployment of microservices in lightweight, portable containers. Containers provide a consistent and isolated runtime environment for microservices, and can be easily deployed and scaled using container orchestration tools such as Kubernetes.
What is the role of DevOps in microservices architectures?
DevOps is a set of practices that emphasizes collaboration and communication between development and operations teams. DevOps is critical in microservices architectures, as it enables teams to rapidly develop, deploy, and scale microservices while maintaining high levels of quality and reliability.
What is the role of testing in microservices architectures?
Testing is a critical component of microservices architectures, as it enables teams to ensure that each microservice is functioning correctly and communicating with other microservices as expected. Testing in microservices architectures typically involves unit testing, integration testing, and end-to-end testing.
What is the role of monitoring in microservices architectures?
Monitoring is a critical component of microservices architectures, as it enables teams to detect and diagnose issues in real-time. Monitoring in microservices architectures typically involves collecting and analyzing metrics such as response times, error rates, and resource utilization, and using this data to identify and resolve issues.
Here are some of the top questions about DevOps:
What isOps?
DevOps is a set of practices that combines software development (Dev) and IT operations (Ops) to enable faster and more reliable software delivery. DevOps emphasizes collaboration, automation, and continuous improvement across the entire software development lifecycle.
What are the benefits of using DevOps?
DevOps provides a number of benefits, including:
Faster time-to-market for software releases
Improved collaboration and communication between development and operations teams
Increased efficiency and productivity
Improved quality and reliability of software releases
Better alignment with business goals and customer needs
Reduced costs and risks
What are the key principles of DevOps?
The key principles of DevOps include:
Collaboration and communication between development and operations teams
Automation of software delivery processes
Continuous integration and continuous delivery (CI/CD)
Infrastructure as code (IaC)
Monitoring and feedback loops
Continuous improvement and learning
What is the difference between DevOps and Agile?
Agile is a software development methodology that emphasizes iterative and incremental development, while DevOps is a set of practices that focuses on collaboration, automation, and continuous improvement across the entire software development lifecycle. DevOps builds on the principles of Agile and extends them to include operations and infrastructure.
What is continuous integration (CI)?
Continuous integration is a software development practice in which developers integrate their code changes into a shared repository frequently, typically several times a day. Each integration is verified by an automated build and test process to detect and resolve integration issues early.
What is continuous delivery (CD)?
Continuous delivery is a software development practice in which code changes are automatically built, tested, and deployed to production environments. Continuous delivery enables faster and more frequent releases while maintaining high levels of quality and reliability.
What is infrastructure as code (IaC)?
Infrastructure as code is a practice in which infrastructure is defined and managed using code and software development techniques. IaC enables infrastructure to be treated as a versioned and automated artifact, which can be easily deployed and scaled using DevOps practices.
What is a DevOps pipeline?
A DevOps pipeline is a set of automated processes that enable code changes to be built, tested, and deployed to production environments. A DevOps pipeline typically includes continuous integration, continuous delivery, and automated testing and deployment processes.
What is site reliability engineering (SRE)?
Site reliability engineering is a set of practices that combines software engineering and operations to enable highly reliable and scalable software systems. SRE emphasizes automation, monitoring, and incident response to ensure that software systems are highly available and performant.
What is the role of culture in DevOps?
Culture is a critical component of DevOps, as it enables teams to collaborate effectively and embrace change and continuous improvement. DevOps culture emphasizes communication, trust, and shared responsibility, and encourages teams to take ownership of the entire software development lifecycle.
Here are some of the top questions about system design:
What is system design?
System design is the process of defining the architecture, components, modules, interfaces, and data for a system to satisfy specified requirements. System design is a critical step in the software development lifecycle and involves a number of key activities, including requirements analysis, architecture design, component design, and interface design.
What are the key principles of system design?
The key principles of system design include:
Modularity and abstraction
Separation of concerns
Loose coupling and high cohesion
Scalability and performance
Fault tolerance and resilience
Security and privacy
Usability and accessibility
What is scalability in system design?
Scalability is the ability of a system to handle increasing amounts of work or traffic without sacrificing performance or reliability. Scalability is a critical consideration in system design and can be achieved through a number of techniques, including horizontal scaling, vertical scaling, and load balancing.
What is fault tolerance in system design?
Fault tolerance is the ability of a system to continue operating in the event of a failure or error. Fault tolerance is a critical consideration in system design and can be achieved through a number of techniques, including redundancy, replication, and failover.
What is the role of caching in system design?
Caching is a technique in which frequently accessed data is stored in memory or on disk to improve performance and reduce latency. Caching is a critical consideration in system design and can be used to improve scalability, performance, and reliability.
What is the role of load balancing in system design?
Load balancing is a technique in which incoming traffic is distributed across multiple servers or instances to improve performance and reliability. Load balancing is a critical consideration in system design and can be achieved through a number of techniques, including round-robin, least connections, and IP hash.
What is the role of databases in system design?
Databases are a critical component of many systems and are used to store and retrieve data. Databases can be designed using a number of different models, including relational, NoSQL, and graph databases. Choosing the right database model is a critical consideration in system design.
What is the role of APIs in system design?
APIs are a critical component of many systems and are used to enable communication between different components or systems. APIs can be designed using a number of different styles, including REST, SOAP, and GraphQL. Choosing the right API style is a critical consideration in system design.
What is the role of security in system design?
Security is a critical consideration in system design and involves protecting the system from unauthorized access, data breaches, and other security threats. Security can be achieved through a number of techniques, including encryption, access control, and auditing.
What is the role of testing in system design?
Testing is a critical component of system design and involves verifying that the system meets its specified requirements and performs as expected. Testing can be achieved through a number of techniques, including unit testing, integration testing, and end-to-end testing.
Here some of the top questions about design patterns:
What are design patterns?
Design patterns are reusable solutions to common software design problems. Design patterns provide a way to solve problems that have been encountered and solved before, and can help to improve the quality, maintainability, and scalability of software systems.
What are the benefits of using design patterns?
Design patterns provide a number of benefits, including:
Improved code quality and maintainability
Faster development times
Improved scalability and flexibility
Better alignment with industry best practices
Improved communication and collaboration among developers
What are the different types of design patterns?
Design patterns can be classified into three main categories:
Creational patterns, which deal with object creation and initialization
Structural patterns, which deal with object composition and relationships
Behavioral patterns, which deal with communication and interaction between objects
What is the Singleton pattern?
The Singleton pattern is a creational pattern that ensures that a class has only one instance and provides a global point of access to that instance. The Singleton pattern is commonly used for objects that need to be shared across the entire application, such as configuration settings or database connections.
What is the Factory pattern?
The Factory pattern is a creational pattern that provides an interface for creating objects in a superclass, but allows subclasses to alter the type of objects that will be created. The Factory pattern is commonly used to encapsulate object creation and improve code maintainability.
What is the Observer pattern?
The Observer pattern is a behavioral pattern that defines a one-to-many relationship between objects, where changes to one object are automatically propagated to other objects. The Observer pattern is commonly used for event-driven systems, such as user interfaces or message queues.
What is the Decorator pattern?
The Decorator pattern is a structural pattern that allows behavior to be added to an individual object, either statically or dynamically, without affecting the behavior of other objects in the same class. The Decorator pattern is commonly used to add functionality to existing objects without modifying their underlying code.
What is the Adapter pattern?
The Adapter pattern is a structural pattern that allows incompatible interfaces to work together by wrapping one interface around another. The Adapter pattern is commonly used to integrate legacy code or third-party libraries into a new system.
What is the Strategy pattern?
The Strategy pattern is a behavioral pattern that defines a family of algorithms, encapsulates each one, and makes them interchangeable. The Strategy pattern is commonly used to enable runtime selection of algorithms or to provide a pluggable architecture for different implementations.
What is the Template Method pattern?
The Template Method pattern is a behavioral pattern that defines the skeleton of an algorithm in a superclass, but allows subclasses to override specific steps of the algorithm without changing its overall structure. The Template Method pattern is commonly used to provide a framework for implementing complex algorithms with multiple steps.
Here are some of the top questions about SOLID principles:
What are SOLID principles?
SOLID principles are a set of five design principles that help to create software that is easy to maintain, extend, and modify. The SOLID principles are:
Single Responsibility Principle (SRP)
Open/Closed Principle (OCP)
Liskov Substitution Principle (LSP)
Interface Segregation Principle (ISP)
Dependency Inversion Principle (DIP)
What is the Single Responsibility Principle (SRP)?
The Single Responsibility Principle (SRP) states that a class should have only one reason to change. In other words, a class should have only one responsibility or job to do. This principle helps to create classes that are easy to understand, test, and maintain.
What is the Open/Closed Principle (OCP)?
The Open/Closed Principle (OCP) states that software entities (classes, modules, functions, etc.) should be open for extension but closed for modification. In other words, you should be able to add new functionality to a system without changing its existing code. This principle helps to create systems that are easy to extend and modify.
What is the Liskov Substitution Principle (LSP)?
The Liskov Substitution Principle (LSP) states that objects of a superclass should be replaceable with objects of a subclass without affecting the correctness of the program. In other words, subclasses should be able to be used in place of their parent classes without causing any unexpected behavior. This principle helps to create systems that are easy to maintain and extend.
What is the Interface Segregation Principle (ISP)?
The Interface Segregation Principle (ISP) states that clients should not be forced to depend on interfaces they do not use. In other words, interfaces should be designed to be as small and specific as possible, so that clients only need to implement the methods they actually use. This principle helps to create systems that are easy to maintain and extend.
What is the Dependency Inversion Principle (DIP)?
The Dependency Inversion Principle (DIP) states that high-level modules should not depend on low-level modules, but both should depend on abstractions. In other words, the details of implementation should depend on abstractions, not the other way around. This principle helps to create systems that are easy to test, maintain, and extend.
How do SOLID principles help in software development?
SOLID principles help to create software that is easy to maintain, extend, and modify. By following these principles, developers can create systems that are more flexible, scalable, and resilient to change. SOLID principles also help to improve code quality, reduce technical debt, and increase developer productivity.
What are some common violations of SOLID principles?
Some common violations of SOLID principles include:
Classes with multiple responsibilities
Classes that are difficult to extend or modify
Inheritance hierarchies that violate the Liskov Substitution Principle
Interfaces that are too large or too general
Tight coupling between modules or components
How can SOLID principles be applied in practice?
SOLID principles can be applied in practice by:
Designing classes and interfaces with a single responsibility
Using abstraction and polymorphism to enable extension and modification
Avoiding tight coupling between modules or components
Using dependency injection to invert dependencies and improve testability
Refactoring code to remove violations of SOLID principles
What is the relationship between SOLID principles and design patterns?
SOLID principles and design patterns are closely related, as design patterns are often used to implement SOLID principles. Design patterns provide reusable solutions to common software design problems, and many design patterns are based on SOLID principles. By using design patterns, developers can create software that is more flexible, scalable, and maintainable.
Here are some of the top questions about microservices architecture:
What is microservices architecture?
Microservices architecture is an approach to software development that structures an application as a collection of small, independent services that communicate with each other through APIs. Each service is designed to perform a specific business function and can be developed, deployed, and scaled independently.
What are the benefits of microservices architecture?
Microservices architecture provides a number of benefits, including:
Improved scalability and flexibility
Faster time-to-market for new features and updates
Improved fault tolerance and resilience
Better alignment with business goals and customer needs
Improved developer productivity and autonomy
What are the key principles of microservices architecture?
The key principles of microservices architecture include:
Service autonomy and independence
Decentralized data management
API-based communication
Continuous delivery and deployment
DevOps culture and practices
Polyglot programming and technology diversity
What are the challenges of microservices architecture?
Microservices architecture also presents a number of challenges, including:
Increased complexity and management overhead
Distributed system challenges, such as network latency and data consistency
Increased testing and monitoring requirements
Increased security and compliance concerns
Increased operational complexity and cost
What is the role of containers and orchestration in microservices architecture?
Containers and orchestration are critical components of microservices architecture, as they enable services to be deployed and managed at scale. Containers provide a lightweight and portable way to package and deploy services, while orchestration tools such as Kubernetes enable services to be managed and scaled automatically.
What is the role of API gateways in microservices architecture?
API gateways are a critical component of microservices architecture, as they provide a single entry point for clients to access the various services in the system. API gateways can handle authentication, load balancing, caching, and other functions, and can help to simplify the client-side code.
What is the role of service discovery in microservices architecture?
Service discovery is a critical component of microservices architecture, as it enables services to discover and communicate with each other dynamically. Service discovery tools such as Consul or Eureka enable services to register themselves and discover other services, and can help to simplify the configuration and management of the system.
What is the role of event-driven architecture in microservices architecture?
Event-driven architecture is a complementary approach to microservices architecture that emphasizes the use of asynchronous messaging and event-driven patterns to enable loose coupling and scalability. Event-driven architecture can be used to enable real-time processing, event sourcing, and other use cases.
What is the role of testing in microservices architecture?
Testing is a critical component of microservices architecture, as it enables teams to ensure that each service is functioning correctly and communicating with other services as expected. Testing in microservices architecture typically involves unit testing, integration testing, and end-to-end testing.
What is the role of monitoring in microservices architecture?
Monitoring is a critical component of microservices architecture, as it enables teams to detect and diagnose issues in real-time. Monitoring in microservices architecture typically involves collecting and analyzing metrics such as response times, error rates, and resource utilization, and using this data to identify and resolve issues.
Here some of the top questions about creational design patterns:
What are creational design patterns?
Creational design patterns are a set of design patterns that deal with object creation and initialization. Creational design patterns provide a way to create objects in a flexible and reusable way, and can help to improve code quality, maintainability, and scalability.
What are the different types of creational design patterns?
Creational design patterns can be classified into five main categories:
Singleton pattern
Factory pattern
Abstract Factory pattern
Builder pattern
Prototype pattern
What is the Singleton pattern?
The Singleton pattern is a creational pattern that ensures that a class has only one instance and provides a global point of access to that instance. The Singleton pattern is commonly used for objects that need to be shared across the entire application, such as configuration settings or database connections.
What is the Factory pattern?
The Factory pattern is a creational pattern that provides an interface for creating objects in a superclass, but allows subclasses to alter the type of objects that will be created. The Factory pattern is commonly used to encapsulate object creation and improve code maintainability.
What is the Abstract Factory pattern?
The Abstract Factory pattern is a creational pattern that provides an interface for creating families of related or dependent objects without specifying their concrete classes. The Abstract Factory pattern is commonly used to enable the creation of objects that are part of a larger system or framework.
What is the Builder pattern?
The Builder pattern is a creational pattern that separates the construction of a complex object from its representation, allowing the same construction process to create different representations. The Builder pattern is commonly used to create objects that have complex initialization requirements or multiple configuration options.
What is the Prototype pattern?
The Prototype pattern is a creational pattern that allows new objects to be created by cloning or copying existing objects, rather than creating them from scratch. The Prototype pattern is commonly used to create objects that are expensive to create or that require complex initialization.
What are the benefits of using creational design patterns?
Creational design patterns provide a number of benefits, including:
Improved code quality and maintainability
Faster development times
Improved scalability and flexibility
Better alignment with industry best practices
Improved communication and collaboration among developers
What are some common use cases for creational design patterns?
Some common use cases for creational design patterns include:
Creating objects that are part of a larger system or framework
Creating objects that have complex initialization requirements or multiple configuration options
Creating objects that are expensive to create or that require complex initialization
Creating objects that need to be shared across the entire application
How can creational design patterns be applied in practice?
Creational design patterns can be applied in practice by:
Identifying areas of code that involve object creation and initialization
Choosing the appropriate creational design pattern for the specific use case
Implementing the creational design pattern using industry best practices and design principles
Refactoring existing code to use creational design patterns where appropriate.
Here are some of the top questions about structural design patterns:
What are structural design patterns?
Structural design patterns are a set of design patterns that deal with object composition and relationships. Structural design patterns provide a way to organize objects in a flexible and reusable way, and can help to improve code quality, maintainability, and scalability.
What are the different types of structural design patterns?
Structural design patterns can be classified into seven main categories:
Adapter pattern
Bridge pattern
Composite pattern
Decorator pattern
Facade pattern
Flyweight pattern
Proxy pattern
What is the Adapter pattern?
The Adapter pattern is a structural pattern that allows incompatible interfaces to work together by wrapping one interface around another. The Adapter pattern is commonly used to integrate legacy code or third-party libraries into a new system.
What is the Bridge pattern?
The Bridge pattern is a structural pattern that separates an object's interface from its implementation, allowing them to vary independently. The Bridge pattern is commonly used to enable the creation of complex objects with multiple variations.
What is the Composite pattern?
The Composite pattern is a structural pattern that allows objects to be composed into tree structures, and allows clients to treat individual objects and groups of objects uniformly. The Composite pattern is commonly used to create hierarchical structures, such as menus or file systems.
What is the Decorator pattern?
The Decorator pattern is a structural pattern that allows behavior to be added to an individual object, either statically or dynamically, without affecting the behavior of other objects in the same class. The Decorator pattern is commonly used to add functionality to existing objects without modifying their underlying code.
What is the Facade pattern?
The Facade pattern is a structural pattern that provides a simplified interface to a complex system or set of objects. The Facade pattern is commonly used to hide the complexity of a system from clients and to provide a more user-friendly interface.
What is the Flyweight pattern?
The Flyweight pattern is a structural pattern that allows objects to be shared across multiple contexts, reducing memory usage and improving performance. The Flyweight pattern is commonly used to create objects that are expensive to create or that have a large memory footprint.
What is the Proxy pattern?
The Proxy pattern is a structural pattern that provides a surrogate or placeholder for another object, allowing clients to interact with the object indirectly. The Proxy pattern is commonly used to provide additional functionality, such as caching or security, without modifying the underlying object.
What are the benefits of using structural design patterns?
Structural design patterns provide a number of benefits, including:
Improved code quality and maintainability
Faster development times
Improved scalability and flexibility
Better alignment with industry best practices
Improved communication and collaboration among developers
What are some common use cases for structural design patterns?
Some common use cases for structural design patterns include:
Creating complex objects with multiple variations
Creating hierarchical structures, such as menus or file systems
Adding functionality to existing objects without modifying their underlying code
Hiding the complexity of a system from clients and providing a more user-friendly interface
Reducing memory usage and improving performance by sharing objects across multiple contexts
How can structural design patterns be applied in practice?
Structural design patterns can be applied in practice by:
Identifying areas of code that involve object composition and relationships
Choosing the appropriate structural design pattern for the specific use case
Implementing the structural design pattern using industry best practices and design principles
Refactoring existing code to use structural design patterns where appropriate.
Here are some of the top questions about behavioral design patterns:
What are behavioral design patterns?
Behavioral design patterns are a set of design patterns that deal with communication and interaction between objects. Behavioral design patterns provide a way to organize objects in a flexible and reusable way, and can help to improve code quality, maintainability, and scalability.
What are the different types of behavioral design patterns?
Behavioral design patterns can be classified into three main categories:
Chain of Responsibility pattern
Command pattern
Interpreter pattern
Iterator pattern
Mediator pattern
Memento pattern
Observer pattern
State pattern
Strategy pattern
Template Method pattern
Visitor pattern
What is the Chain of Responsibility pattern?
The Chain of Responsibility pattern is a behavioral pattern that allows multiple objects to handle a request, without specifying which object will handle the request. The Chain of Responsibility pattern is commonly used to create a chain of objects that can handle different types of requests.
What is the Command pattern?
The Command pattern is a behavioral pattern that encapsulates a request as an object, allowing the request to be parameterized with different arguments, queued, or logged. The Command pattern is commonly used to enable undo/redo functionality, or to implement a transactional system.
What is the Interpreter pattern?
The Interpreter pattern is a behavioral pattern that defines a grammar for a language and provides an interpreter to interpret the language. The Interpreter pattern is commonly used to create domain-specific languages or to implement complex business rules.
What is the Iterator pattern?
The Iterator pattern is a behavioral pattern that provides a way to access the elements of an aggregate object sequentially, without exposing the underlying representation of the object. The Iterator pattern is commonly used to iterate over collections or to provide a uniform interface to different types of data structures.
What is the Mediator pattern?
The Mediator pattern is a behavioral pattern that defines an object that encapsulates how a set of objects interact, without exposing their internal details. The Mediator pattern is commonly used to reduce coupling between objects and to simplify communication between objects.
What is the Memento pattern?
The Memento pattern is a behavioral pattern that provides a way to capture and restore the internal state of an object without violating encapsulation. The Memento pattern is commonly used to enable undo/redo functionality or to implement a checkpoint system.
What is the Observer pattern?
The Observer pattern is a behavioral pattern that defines a one-to-many dependency between objects, so that when one object changes state, all its dependents are notified and updated automatically. The Observer pattern is commonly used to implement event-driven systems or to enable loose coupling between objects.
What is the State pattern?
The State pattern is a behavioral pattern that allows an object to alter its behavior when its internal state changes. The State pattern is commonly used to create objects that have multiple states or to enable dynamic behavior based on changing conditions.
What is the Strategy pattern?
The Strategy pattern is a behavioral pattern that defines a family of algorithms, encapsulates each one, and makes them interchangeable. The Strategy pattern is commonly used to enable dynamic behavior based on changing conditions or to provide a way to switch between different algorithms at runtime.
What is the Template Method pattern?
The Template Method pattern is a behavioral pattern that defines the skeleton of an algorithm in a superclass, but allows subclasses to override specific steps of the algorithm without changing its structure. The Template Method pattern is commonly used to enable code reuse and to provide a way to customize the behavior of an algorithm.
What is the Visitor pattern?
The Visitor pattern is a behavioral pattern that allows new operations to be added to existing object structures without modifying those structures. The Visitor pattern is commonly used to enable the separation of concerns between objects and operations, or to enable the creation of new operations without modifying existing code.
What are the benefits of using behavioral design patterns?
Behavioral design patterns provide a number of benefits, including:
Improved code quality and maintainability
Faster development times
Improved scalability and flexibility
Better alignment with industry best practices
Improved communication and collaboration among developers
What are some common use cases for behavioral design patterns?
Some common use cases for behavioral design patterns include:
Creating objects that have multiple states or behaviors
Enabling dynamic behavior based on changing conditions
Enabling the separation of concerns between objects and operations
Enabling the creation of new operations without modifying existing code
Enabling undo/redo functionality or transactional systems
How can behavioral design patterns be applied in practice?
Behavioral design patterns can be applied in practice by:
Identifying areas of code that involve communication and interaction between objects
Choosing the appropriate behavioral design pattern for the specific use case
Implementing the behavioral design pattern using industry best practices and design principles
Here are some of the top questions about computer networking:
What is computer networking?
Computer networking is the practice of connecting multiple devices together to share resources and communicate with each other. Computer networks can be used for a variety of purposes, including sharing files, accessing the internet, and communicating with other users.
What are the different types of computer networks?
Computer networks can be classified into several different types, including:
Local Area Network (LAN)
Wide Area Network (WAN)
Metropolitan Area Network (MAN)
Storage Area Network (SAN)
Wireless Local Area Network (WLAN)
Virtual Private Network (VPN)
What is a LAN?
A Local Area Network (LAN) is a network that connects devices within a small geographic area, such as a home, office, or school. LANs are typically used to share resources, such as printers or files, and to enable communication between devices.
What is a WAN?
A Wide Area Network (WAN) is a network that connects devices over a large geographic area, such as a city, country, or even the world. WANs are typically used to connect multiple LANs together, and to enable communication between devices that are far apart.
What is a MAN?
A Metropolitan Area Network (MAN) is a network that connects devices within a metropolitan area, such as a city or town. MANs are typically used to connect multiple LANs together, and to enable communication between devices that are located in different parts of the city.
What is a SAN?
A Storage Area Network (SAN) is a network that provides access to storage devices, such as hard drives or tape libraries, over a high-speed network connection. SANs are typically used to provide centralized storage for large organizations or data centers.
What is a WLAN?
A Wireless Local Area Network (WLAN) is a network that uses wireless technology, such as Wi-Fi, to connect devices within a small geographic area. WLANs are typically used to provide wireless access to the internet or to enable communication between devices without the need for cables.
What is a VPN?
A Virtual Private Network (VPN) is a network that provides a secure, encrypted connection over a public network, such as the internet. VPNs are typically used to enable remote access to a private network, or to provide a secure connection between two networks.
What are the different layers of the OSI model?
The OSI (Open Systems Interconnection) model is a conceptual model that describes the communication functions of a network. The OSI model consists of seven layers, including:
Physical layer
Data link layer
Network layer
Transport layer
Session layer
Presentation layer
Application layer
What is TCP/IP?
TCP/IP (Transmission Control Protocol/Internet Protocol) is a set of protocols that are used to enable communication between devices on the internet. TCP/IP consists of two main protocols, TCP (Transmission Control Protocol) and IP (Internet Protocol), and is the foundation of the internet and many other computer networks.
What is DNS?
DNS (Domain Name System) is a system that translates domain names, such as www.example.com, into IP addresses, such as 192.0.2.1. DNS is used to enable communication between devices on the internet, and is a critical component of the internet infrastructure.
What is DHCP?
DHCP (Dynamic Host Configuration Protocol) is a protocol that is used to automatically assign IP addresses and other network configuration information to devices on a network. DHCP is commonly used in LANs and WLANs to simplify network configuration and management.
What is NAT?
NAT (Network Address Translation) is a technique that is used to enable devices on a private network to access the internet using a single public IP address. NAT is commonly used in home and small office networks to enable multiple devices to share a single internet connection.
What is a firewall?
A firewall is a network security device that is used to monitor and control incoming and outgoing network traffic. Firewalls are commonly used to protect networks from unauthorized access, and to prevent malware and other security threats from entering the network.
What are some common network security threats?
Some common network security threats include:
Malware, such as viruses, worms, and Trojan horses
Phishing attacks, which attempt to trick users into revealing sensitive information
Denial of Service (DoS) attacks, which attempt to overwhelm a network with traffic
Man-in-the-middle attacks, which intercept and modify network traffic
Password attacks, which attempt to guess or steal user passwords
How can network security be improved?
Network security can be improved by:
Implementing strong passwords and authentication mechanisms
Keeping software and firmware up-to-date with security patches
Using firewalls and other network security
There is some frustration when people publish their perfect fine-grained algorithms without sharing any information abut how they were derived. This is an attempt to change the situation. There is not much more explanation but it's rather an example of higher level improvements. Converting a solution to the next step shouldn't be as hard as attempting to come up with perfect algorithm at first attempt.
This particular problem and most of others can be approached using the following sequence:
Find recursive relation
Recursive (top-down)
Recursive + memo (top-down)
Iterative + memo (bottom-up)
Iterative + N variables (bottom-up)
Step 1. Figure out recursive relation.
A robber has 2 options: a) rob current house i; b) don't rob current house.
If an option "a" is selected it means she can't rob previous i-1 house but can safely proceed to the one before previous i-2 and gets all cumulative loot that follows.
If an option "b" is selected the robber gets all the possible loot from robbery of i-1 and all the following buildings.
So it boils down to calculating what is more profitable:
robbery of current house + loot from houses before the previous
loot from the previous house robbery and any loot captured before that
rob(i) = Math.max( rob(i - 2) + currentHouseValue, rob(i - 1) )
Step 2. Recursive (top-down)
Converting the recurrent relation from Step 1 shound't be very hard.
public int rob(int[] nums) {
return rob(nums, nums.length - 1);
}
private int rob(int[] nums, int i) {
if (i < 0) {
return 0;
}
return Math.max(rob(nums, i - 2) + nums[i], rob(nums, i - 1));
}
This algorithm will process the same i multiple times and it needs improvement. Time complexity: [to fill]
Step 3. Recursive + memo (top-down).
int[] memo;
public int rob(int[] nums) {
memo = new int[nums.length + 1];
Arrays.fill(memo, -1);
return rob(nums, nums.length - 1);
}
private int rob(int[] nums, int i) {
if (i < 0) {
return 0;
}
if (memo[i] >= 0) {
return memo[i];
}
int result = Math.max(rob(nums, i - 2) + nums[i], rob(nums, i - 1));
memo[i] = result;
return result;
}
Much better, this should run in O(n) time. Space complexity is O(n) as well, because of the recursion stack, let's try to get rid of it.
Step 4. Iterative + memo (bottom-up)
public int rob(int[] nums) {
if (nums.length == 0) return 0;
int[] memo = new int[nums.length + 1];
memo[0] = 0;
memo[1] = nums[0];
for (int i = 1; i < nums.length; i++) {
int val = nums[i];
memo[i+1] = Math.max(memo[i], memo[i-1] + val);
}
return memo[nums.length];
}
Step 5. Iterative + 2 variables (bottom-up)
We can notice that in the previous step we use only memo[i] and memo[i-1], so going just 2 steps back. We can hold them in 2 variables instead. This optimization is met in Fibonacci sequence creation and some other problems [to paste links].
/* the order is: prev2, prev1, num */
public int rob(int[] nums) {
if (nums.length == 0) return 0;
int prev1 = 0;
int prev2 = 0;
for (int num : nums) {
int tmp = prev1;
prev1 = Math.max(prev2 + num, prev1);
prev2 = tmp;
}
return prev1;
}
DSA
java vs c++ vs python
import java.util.*;
// Create a new list
List<Integer> list = new ArrayList<>();
// Add an element to the end of the list
list.add(5);
// Add an element at a specific index
list.add(1, 10);
// Get the element at a specific index
int element = list.get(1);
// Set the element at a specific index
list.set(1, 20);
// Remove an element at a specific index
list.remove(1);
// Remove the first occurrence of an element
list.remove(Integer.valueOf(5));
// Check if the list contains an element
boolean contains = list.contains(5);
// Get the size of the list
int size = list.size();
// Sort the list in ascending order
Collections.sort(list);
// Sort the list in descending order
Collections.sort(list, Collections.reverseOrder());
// Iterate over the elements of the list
for (int i = 0; i < list.size(); i++) {
int element = list.get(i);
// Do something with the element
}
// Iterate over the elements of the list using a for-each loop
for (int element : list) {
// Do something with the element
}
// Convert the list to an array
Integer[] array = list.toArray(new Integer[0]);
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
// Create a new list
vector<int> list;
// Add an element to the end of the list
list.push_back(5);
// Add an element at a specific index
list.insert(list.begin() + 1, 10);
// Get the element at a specific index
int element = list[1];
// Set the element at a specific index
list[1] = 20;
// Remove an element at a specific index
list.erase(list.begin() + 1);
// Remove the first occurrence of an element
list.erase(find(list.begin(), list.end(), 5));
// Check if the list contains an element
bool contains = find(list.begin(), list.end(), 5) != list.end();
// Get the size of the list
int size = list.size();
// Sort the list in ascending order
sort(list.begin(), list.end());
// Sort the list in descending order
sort(list.begin(), list.end(), greater<int>());
// Iterate over the elements of the list
for (int i = 0; i < list.size(); i++) {
int element = list[i];
// Do something with the element
}
// Iterate over the elements of the list using a for-each loop
for (int element : list) {
// Do something with the element
}
// Convert the list to an array
int* array = list.data();
# Create a new list
list = []
# Add an element to the end of the list
list.append(5)
# Add an element at a specific index
list.insert(1, 10)
# Get the element at a specific index
element = list[1]
# Set the element at a specific index
list[1] = 20
# Remove an element at a specific index
list.pop(1)
# Remove the first occurrence of an element
list.remove(5)
# Check if the list contains an element
contains = 5 in list
# Get the size of the list
size = len(list)
# Sort the list in ascending order
list.sort()
# Sort the list in descending order
list.sort(reverse=True)
# Iterate over the elements of the list
for i in range(len(list)):
element = list[i]
# Do something with the element
# Iterate over the elements of the list using a for-each loop
for element in list:
# Do something with the element
# Convert the list to an array
array = list.copy()
Js
// Create a new list
let list = [];
// Add an element to the end of the list
list.push(5);
// Add an element at a specific index
list.splice(1, 0, 10);
// Get the element at a specific index
let element = list[1];
// Set the element at a specific index
list[1] = 20;
// Remove an element at a specific index
list.splice(1, 1);
// Remove the first occurrence of an element
let index = list.indexOf(5);
if (index !== -1) {
list.splice(index, 1);
}
// Check if the list contains an element
let contains = list.includes(5);
// Get the size of the list
let size = list.length;
// Sort the list in ascending order
list.sort((a, b) => a - b);
// Sort the list in descending order
list.sort((a, b) => b- a);
import java.util.*;
// Create a new queue
Queue<Integer> queue = new LinkedList<>();
// Add an element to the end of the queue
queue.add(5);
// Remove and return the element at the front of the queue
int element = queue.remove();
// Return the element at the front of the queue without removing it
int element = queue.peek();
// Check if the queue is empty
boolean isEmpty = queue.isEmpty();
// Get the size of the queue
int size = queue.size();
// Iterate over the elements of the queue
for (int element : queue) {
// Do something with the element
}
c++
#include <iostream>
#include <queue>
using namespace std;
// Create a new queue
queue<int> queue;
// Add an element to the end of the queue
queue.push(5);
// Remove and return the element at the front of the queue
int element = queue.front();
queue.pop();
// Return the element at the front of the queue without removing it
int element = queue.front();
// Check if the queue is empty
bool isEmpty = queue.empty();
// Get the size of the queue
int size = queue.size();
// Iterate over the elements of the queue
while (!queue.empty()) {
int element = queue.front();
queue.pop();
// Do something with the element
}
py
from collections import deque
# Create a new queue
queue = deque()
# Add an element to the end of the queue
queue.append(5)
# Remove and return the element at the front of the queue
element = queue.popleft()
# Return the element at the front of the queue without removing it
element = queue[0]
# Check if the queue is empty
isEmpty = len(queue) == 0
# Get the size of the queue
size = len(queue)
# Iterate over the elements of the queue
for element in queue:
# Do something with the element
js
// Create a new queue
let queue = [];
// Add an element to the end of the queue
queue.push(5);
// Remove and return the element at the front of the queue
let element = queue.shift();
// Return the element at the front of the queue without removing it
let element = queue[0];
// Check if the queue is empty
let isEmpty = queue.length === 0;
// Get the size of the queue
let size = queue.length;
// Iterate over the elements of the queue
for (let i = 0; i < queue.length; i++) {
let element = queue[i];
// Do something with the element
}
map
java
import java.util.*;
// Create a new map
Map<String, Integer> map = new HashMap<>();
// Add a key-value pair to the map
map.put("apple", 5);
// Get the value associated with a key
int value = map.get("apple");
// Check if the map contains a key
boolean containsKey = map.containsKey("apple");
// Check if the map contains a value
boolean containsValue = map.containsValue(5);
// Remove a key-value pair from the map
map.remove("apple");
// Get the size of the map
int size = map.size();
// Iterate over the keys of the map
for (String key : map.keySet()) {
int value = map.get(key);
// Do something with the key and value
}
// Iterate over the key-value pairs of the map
for (Map.Entry<String, Integer> entry : map.entrySet()) {
String key = entry.getKey();
int value = entry.getValue();
// Do something with the key and value
}
c++
#include <iostream>
#include <unordered_map>
using namespace std;
// Create a new map
unordered_map<string, int> map;
// Add a key-value pair to the map
map["apple"] = 5;
// Get the value associated with a key
int value = map["apple"];
// Check if the map contains a key
bool containsKey = map.count("apple") > 0;
// Check if the map contains a value
bool containsValue = find_if(map.begin(), map.end(), [](const auto& entry) { return entry.second == 5; }) != map.end();
// Remove a key-value pair from the map
map.erase("apple");
// Get the size of the map
int size = map.size();
// Iterate over the keys of the map
for (auto& entry : map) {
string key = entry.first;
int value = entry.second;
// Do something with the key and value
}
py
# Create a new map
map = {}
# Add a key-value pair to the map
map["apple"] = 5
# Get the value associated with a key
value = map["apple"]
# Check if the map contains a key
containsKey = "apple" in map
# Check if the map contains a value
containsValue = 5 in map.values()
# Remove a key-value pair from the map
del map["apple"]
# Get the size of the map
size = len(map)
# Iterate over the keys of the map
for key in map:
value = map[key]
# Do something with the key and value
# Iterate over the key-value pairs of the map
for key, value in map.items():
# Do something with the key and value
js
// Create a new map
let map = new Map();
// Add a key-value pair to the map
map.set("apple", 5);
// Get the value associated with a key
let value = map.get("apple");
// Check if the map contains a key
let containsKey = map.has("apple");
// Check if the map contains a value
let containsValue = [...map.values()].includes(5);
// Remove a key-value pair from the map
map.delete("apple");
// Get the size of the map
let size = map.size;
// Iterate over the keys of the map
for (let key of map.keys()) {
let value = map.get(key);
// Do something with the key and value
}
// Iterate over the key-value pairs of the map
for (let [key, value] of map.entries()) {
// Do something with the key and value
}
import heapq
# Create a list
my_list = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
# Get the three smallest elements from the list
smallest = heapq.nsmallest(3, my_list)
# Print the smallest elements
print(smallest) # Output: [1, 1, 2]
import heapq
# Create a list
my_list = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
# Get the three largest elements from the list
largest = heapq.nlargest(3, my_list)
# Print the largest elements
print(largest) # Output: [9, 6, 5]
import heapq
# Create a heap
my_heap = [1, 3, 4]
# Replace the smallest element in the heap with a new element
smallest = heapq.heapreplace(my_heap, 2)
# Print the smallest element and the updated heap
print(smallest) # Output: 1
print(my_heap) # Output: [2, 3, 4]
import heapq
# Create a heap
my_heap = [1, 3, 4]
# Remove the smallest element from the heap
smallest = heapq.heappop(my_heap)
# Print the smallest element and the updated heap
print(smallest) # Output: 1
print(my_heap) # Output: [3, 4]
import heapq
# Create a heap
my_heap = []
# Add some elements to the heap
heapq.heappush(my_heap, 3)
heapq.heappush(my_heap, 1)
heapq.heappush(my_heap, 4)
# Print the heap
print(my_heap) # Output: [1, 3, 4]
import heapq
# Create a list
my_list = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
# Convert the list to a heap
heapq.heapify(my_list)
# Print the heap
print(my_list) # Output: [1, 1, 2, 3, 3, 9, 4, 6, 5, 5, 5]
import bisect
# Define a sorted list
my_list = [1, 3, 4, 5, 7, 8, 10]
# Perform binary search for the value 5
index = bisect.bisect_left(my_list, 5)
# Print the index of the value 5
print(index) # Output: 3
import bisect
# Define a sorted list
my_list = [1, 3, 4, 5, 7, 8, 10]
# Perform lower bound search for the value 6
lower_bound = bisect.bisect_left(my_list, 6)
# Perform upper bound search for the value 6
upper_bound = bisect.bisect_right(my_list, 6)
# Print the lower and upper bounds of the value 6
print(lower_bound) # Output: 4
print(upper_bound) # Output: 4
import java.util.Arrays;
import java.util.Comparator;
public class Main {
public static void main(String[] args) {
// Define a sorted array
int[] myArray = {1, 3, 4, 5, 7, 8, 10};
// Perform lower bound search for the value 6
int lowerBound = Arrays.binarySearch(myArray, 6, Comparator.naturalOrder());
// Perform upper bound search for the value 6
int upperBound = Arrays.binarySearch(myArray, 6, Comparator.naturalOrder().reversed());
// Print the lower and upper bounds of the value 6
System.out.println(lowerBound); // Output: -5
System.out.println(upperBound); // Output: -4
}
}
#include <iostream>
#include <algorithm>
#include <vector>
int main() {
// Define a sorted vector
std::vector<int> myVector = {1, 3, 4, 5, 7, 8, 10};
// Perform lower bound search for the value 6
auto lowerBound = std::lower_bound(myVector.begin(), myVector.end(), 6);
// Perform upper bound search for the value 6
auto upperBound = std::upper_bound(myVector.begin(), myVector.end(), 6);
// Print the lower and upper bounds of the value 6
std::cout << std::distance(myVector.begin(), lowerBound) << std::endl; // Output: 4
std::cout << std::distance(myVector.begin(), upperBound) << std::endl; // Output: 4
}
#include <iostream>
#include <algorithm>
#include <vector>
int main() {
// Define a sorted vector
std::vector<int> myVector = {1, 3, 4, 5, 7, 8, 10};
// Perform binary search for the value 5
bool found = std::binary_search(myVector.begin(), myVector.end(), 5);
// Print whether the value 5 was found
std::cout << found << std::endl; // Output: 1
}
import java.util.concurrent.CompletableFuture;
public class Main {
public static void main(String[] args) {
// Define a CompletableFuture that returns a string
CompletableFuture<String> future1 = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "Hello";
});
// Define a CompletableFuture that returns another string
CompletableFuture<String> future2 = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "World";
});
// Compose the two CompletableFutures using the thenCombine method
CompletableFuture<String> future3 = future1.thenCombine(future2, (s1, s2) -> s1 + " " + s2);
// Print the result of the composed CompletableFuture
future3.thenAccept(System.out::println); // Output: Hello World
// Wait for the CompletableFutures to complete
CompletableFuture.allOf(future1, future2, future3).join();
}
}
The CompletableFuture class is a powerful tool for performing asynchronous operations in Java. It provides a way to chain together asynchronous operations and get the results of those operations in a predictable order.
In the example you provided, two CompletableFuture objects are created using the supplyAsync method. The supplyAsync method takes a lambda expression that defines the asynchronous operation to be performed and returns a CompletableFuture that will eventually contain the result of the operation.
The two CompletableFuture objects are then composed using the thenCombine method. The thenCombine method takes two CompletableFuture objects and a lambda expression that defines how to combine their results. In this case, the lambda expression concatenates the two strings.
Finally, the result of the composed CompletableFuture is printed using the thenAccept method, which takes a lambda expression that defines what to do with the result. The allOf method is used to wait for all three CompletableFuture objects to complete before the program exits.
This example demonstrates how the CompletableFuture class can be used to perform asynchronous operations and compose them in a functional way. The CompletableFuture class provides a powerful and flexible way to work with asynchronous code in Java 8 and beyond.
Here is a more detailed explanation of the example:
The first CompletableFuture object is created to fetch the value of the foo property from a remote server. The supplyAsync method is used to create the CompletableFuture object, and the lambda expression passed to the supplyAsync method defines the asynchronous operation to be performed. The lambda expression uses the get() method of the RemoteService class to fetch the value of the foo property from the remote server.
The second CompletableFuture object is created to fetch the value of the bar property from a remote server. The supplyAsync method is used to create the CompletableFuture object, and the lambda expression passed to the supplyAsync method defines the asynchronous operation to be performed. The lambda expression uses the get() method of the RemoteService class to fetch the value of the bar property from the remote server.
The two CompletableFuture objects are then composed using the thenCombine method. The thenCombine method takes two CompletableFuture objects and a lambda expression that defines how to combine their results. In this case, the lambda expression concatenates the two strings.
The result of the composed CompletableFuture is then printed using the thenAccept method. The thenAccept method takes a lambda expression that defines what to do with the result. In this case, the lambda expression simply prints the result to the console.
The allOf method is used to wait for all three CompletableFuture objects to complete before the program exits. This ensures that the program will not exit until the results of all three asynchronous operations are available.
Here is the complete code for the example:
Java
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutionException;
public class Example {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// Create a CompletableFuture to fetch the value of the `foo` property from a remote server.
CompletableFuture<String> fooFuture = CompletableFuture.supplyAsync(() -> {
RemoteService service = new RemoteService();
return service.getFoo();
});
// Create a CompletableFuture to fetch the value of the `bar` property from a remote server.
CompletableFuture<String> barFuture = CompletableFuture.supplyAsync(() -> {
RemoteService service = new RemoteService();
return service.getBar();
});
// Combine the results of the two CompletableFuture objects and print the result.
CompletableFuture<String> combinedFuture = fooFuture.thenCombine(barFuture, (foo, bar) -> foo + bar);
combinedFuture.thenAccept(result -> System.out.println(result));
// Wait for all three CompletableFuture objects to complete.
CompletableFuture.allOf(fooFuture, barFuture, combinedFuture).join();
}
}
class RemoteService {
public String getFoo() {
// Simulate an asynchronous operation by sleeping for 1 second.
try {
Thread.sleep(1000);
}
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
// Define an array of integers
int[] myArray = {5, 2, 8, 1, 9, 3, 6, 4, 7, 10};
// Sort the array in parallel
Arrays.parallelSort(myArray);
// Print the sorted array
System.out.println(Arrays.toString(myArray)); // Output: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
}
}
filter
: The
filter
method is used to filter the elements of a stream based on a predicate. It takes a lambda expression that defines the filtering condition and returns a new stream that contains only the elements that satisfy the condition.
Copy codeList<Integer> myList = Arrays.asList(1, 2, 3, 4, 5);
Stream<Integer> myStream = myList.stream();
Stream<Integer> filteredStream = myStream.filter(n -> n % 2 == 0);
map
: The
map
method is used to transform the elements of a stream using a function. It takes a lambda expression that defines the transformation and returns a new stream that contains the transformed elements.
Copy codeList<String> myList = Arrays.asList("apple", "banana", "cherry");
Stream<String> myStream = myList.stream();
Stream<Integer> mappedStream = myStream.map(String::length);
flatMap
: The
flatMap
method is used to transform the elements of a stream into other streams and then flatten the resulting streams into a single stream. It takes a lambda expression that returns a stream and returns a new stream that contains the flattened elements.
Copy codeList<List<Integer>> myList = Arrays.asList(
Arrays.asList(1, 2, 3),
Arrays.asList(4, 5, 6),
Arrays.asList(7, 8, 9)
);
Stream<List<Integer>> myStream = myList.stream();
Stream<Integer> flattenedStream = myStream.flatMap(Collection::stream);
distinct
: The
distinct
method is used to remove duplicate elements from a stream. It returns a new stream that contains only the distinct elements.
Copy codeList<Integer> myList = Arrays.asList(1, 2, 3, 2, 1);
Stream<Integer> myStream = myList.stream();
Stream<Integer> distinctStream = myStream.distinct();
sorted
: The
sorted
method is used to sort the elements of a stream in natural order or using a custom comparator. It returns a new stream that contains the sorted elements.
Copy codeList<Integer> myList = Arrays.asList(3, 1, 4, 1, 5, 9, 2, 6, 5, 3);
Stream<Integer> myStream = myList.stream();
Stream<Integer> sortedStream = myStream.sorted();
limit
: The
limit
method is used to limit the number of elements in a stream. It returns a new stream that contains only the first
n
elements.
Copy codeList<Integer> myList = Arrays.asList(1, 2, 3, 4, 5);
Stream<Integer> myStream = myList.stream();
Stream<Integer> limitedStream = myStream.limit(3);
skip
: The
skip
method is used to skip the first
n
elements of a stream. It returns a new stream that contains only the remaining elements.
Copy codeList<Integer> myList = Arrays.asList(1, 2, 3, 4, 5);
Stream<Integer> myStream = myList.stream();
Stream<Integer> skippedStream = myStream.skip(2);
forEach
: The
forEach
method is used to perform an action on each element of a stream. It takes a lambda expression that defines the action to be performed.
Copy codeList<Integer> myList = Arrays.asList(1, 2, 3, 4, 5);
Stream<Integer> myStream = myList.stream();
myStream.forEach(System.out::println);
reduce
: The
reduce
method is used to combine the elements of a stream into a single value using a binary operator. It takes a lambda expression that defines the binary operator and returns the result of the reduction.
Copy codeList<Integer> myList = Arrays.asList(1, 2, 3, 4, 5);
Stream<Integer> myStream = myList.stream();
Optional<Integer> result = myStream.reduce((a, b) -> a + b);
These are just a few examples of the many methods available in the Stream API. The Stream API provides a powerful and flexible way to work with collections of data in Java 8 and beyond, and can help you write more expressive and readable code.
Intermediate methods:
filter
: The
filter
method is used to filter the elements of a stream based on a predicate. It takes a lambda expression that defines the filtering condition and returns a new stream that contains only the elements that satisfy the condition.
Copy codeList<Integer> myList = Arrays.asList(1, 2, 3, 4, 5);
Stream<Integer> myStream = myList.stream();
Stream<Integer> filteredStream = myStream.filter(n -> n % 2 == 0);
map
: The
map
method is used to transform the elements of a stream using a function. It takes a lambda expression that defines the transformation and returns a new stream that contains the transformed elements.
Copy codeList<String> myList = Arrays.asList("apple", "banana", "cherry");
Stream<String> myStream = myList.stream();
Stream<Integer> mappedStream = myStream.map(String::length);
flatMap
: The
flatMap
method is used to transform the elements of a stream into other streams and then flatten the resulting streams into a single stream. It takes a lambda expression that returns a stream and returns a new stream that contains the flattened elements.
Copy codeList<List<Integer>> myList = Arrays.asList(
Arrays.asList(1, 2, 3),
Arrays.asList(4, 5, 6),
Arrays.asList(7, 8, 9)
);
Stream<List<Integer>> myStream = myList.stream();
Stream<Integer> flattenedStream = myStream.flatMap(Collection::stream);
distinct
: The
distinct
method is used to remove duplicate elements from a stream. It returns a new stream that contains only the distinct elements.
Copy codeList<Integer> myList = Arrays.asList(1, 2, 3, 2, 1);
Stream<Integer> myStream = myList.stream();
Stream<Integer> distinctStream = myStream.distinct();
sorted
: The
sorted
method is used to sort the elements of a stream in natural order or using a custom comparator. It returns a new stream that contains the sorted elements.
Copy codeList<Integer> myList = Arrays.asList(3, 1, 4, 1, 5, 9, 2, 6, 5, 3);
Stream<Integer> myStream = myList.stream();
Stream<Integer> sortedStream = myStream.sorted();
limit
: The
limit
method is used to limit the number of elements in a stream. It returns a new stream that contains only the first
n
elements.
Copy codeList<Integer> myList = Arrays.asList(1, 2, 3, 4, 5);
Stream<Integer> myStream = myList.stream();
Stream<Integer> limitedStream = myStream.limit(3);
skip
: The
skip
method is used to skip the first
n
elements of a stream. It returns a new stream that contains only the remaining elements.
Copy codeList<Integer> myList = Arrays.asList(1, 2, 3, 4, 5);
Stream<Integer> myStream = myList.stream();
Stream<Integer> skippedStream = myStream.skip(2);
Terminal methods:
forEach
: The
forEach
method is used to perform an action on each element of a stream. It takes a lambda expression that defines the action to be performed.
Copy codeList<Integer> myList = Arrays.asList(1, 2, 3, 4, 5);
Stream<Integer> myStream = myList.stream();
myStream.forEach(System.out::println);
reduce
: The
reduce
method is used to combine the elements of a stream into a single value using a binary operator. It takes a lambda expression that defines the binary operator and returns the result of the reduction.
Copy codeList<Integer> myList = Arrays.asList(1, 2, 3, 4, 5);
Stream<Integer> myStream = myList.stream();
Optional<Integer> result = myStream.reduce((a, b) -> a + b);
collect
: The
collect
method is used to collect the elements of a stream into a collection or other data structure. It takes a
Collector
object that defines how to collect the elements and returns the collected result.
Copy codeList<Integer> myList = Arrays.asList(1, 2, 3, 4, 5);
Stream<Integer> myStream = myList.stream();
List<Integer> collectedList = myStream.collect(Collectors.toList());
count The
count
method is used to count the number of elements in a stream. It returns a long value that represents the count.
Copy codeList<Integer> myList = Arrays.asList(1, 2, 3, 4, 5);
Stream<Integer> myStream = myList.stream();
long count = myStream.count();
anyMatch
: The
anyMatch
method is used to check whether any element of a stream matches a given predicate. It returns a boolean value that indicates whether any element matches the predicate.
Copy codeList<Integer> myList = Arrays.asList(1, 2, 3, 4, 5);
Stream<Integer> myStream = myList.stream();
boolean anyMatch = myStream.anyMatch(n -> n % 2 == 0);
allMatch
: The
allMatch
method is used to check whether all elements of a stream match a given predicate. It returns a boolean value that indicates whether all elements match the predicate.
Copy codeList<Integer> myList = Arrays.asList(1, 2, 3, 4, 5);
Stream<Integer> myStream = myList.stream();
boolean allMatch = myStream.allMatch(n -> n % 2 == 0);
noneMatch
: The
noneMatch
method is used to check whether none of the elements of a stream match a given predicate. It returns a boolean value that indicates whether none of the elements match the predicate.
Copy codeList<Integer> myList = Arrays.asList(1, 2, 3, 4, 5);
Stream<Integer> myStream = myList.stream();
boolean noneMatch = myStream.noneMatch(n -> n % 2 == 0);
These are just a few examples of the many methods available in the Stream API. It's important to understand the difference between intermediate and terminal methods and how they can be used to process collections of data in a flexible and efficient way.