

UPDATE : Thanks for the great response on this article. This article is selected as leetcode's pick. Thanks a lot for the support and Thank you @LeetCode for providing this opportunity.
Note: The proxy being referred to in this article is actually a "reverse proxy" . Thanks to @madno for clearing this out
Hello Leetcoders!
Many companies like media[dot]net, Goldman Sachs, BookMyShow ask questions related to system design. Most questions revolve around designing a highly available system which can process multiple client requests at the same time and has minimal response time.
In this post, I will walk you through the process of arriving to a solution when asked of such a problem. There is no one go to solution for SD problems, you have to communicate with your interviewer to know the requirements.
What are Distributed systems ?
- Multiple entities communicating to each other via network to form a logically coherent system.
- Here, each unit/entity can be considered like a node on a graph. Each node runs its own operations which are fast. Communication may not be so.
- Goals of a Distributed System:
- Transparency -> End user does not know what lies behind and how the system is working internally.
- It has many types like access transparency, location transparency, failure transparency etc., which would out of the scope of this text. You can research them online.
- Scalability - > Refers to the growth of the system.
- Availability -> Refers to the system's uptime. (Note: In a distributed system, this doesn't refer to a node's uptime but the system's uptime as a whole . i.e. Whether the user can access the system for their purpose or not)
- Transparency -> End user does not know what lies behind and how the system is working internally.
The CAP Theorm
- It States that a Distributed system has to make a tradeoff between Consistency(C) and Availability(A) when a Partition(P) occurs. A Distributed system is bound to have partitions in the real world due to network or hardware failures.
- Consistency + Availability + Partition tolerance cannot be simultaneously achieved in a Dsitributed system (Proved in 2002)
- So what should be preferred more ? Availability or Consistency ?
- Ask yourself , would you rather be not accessing a system at all, or access a system which might not be 100% consistent at that moment in time?
- Availability is preferred more and it is hoped that consistency would be achieved eventually. (called eventual consistency)
- Suppose a seller on amazon added a new product but it's data hasn't achieved consistency across all the servers. This is acceptable (you can still buy it after some minutes), but the users not even being able to access amazon, is not.
Highly available System Design with example
I won't be discussing a specific problem statement as I want that this article should help you develop the thinking process behind arriving to a solution. This will be a very high level design involving no code at all. This is just to get you started with SD.
Suppose you are in an interview and the interviewer asks you to design a highly available system which has multiple concurrent read and write requests.
The first thing you should do is to clarify the functionalities required when asked a specific question. For example, if you are asked to design youtube , ask the interviewer what all exactly he/she wants to be implemented and then you design from there.
Lets start with the thought process you would go through:
- First, the most common system you would think of is the one shown below:

There are many problems in this design as you might've guessed.
-
It is a monolithic architecture which can handle less load and has a single point of failure. The DB or server goes down? your app is down.
-
Solutions ?
- Have more than 1 instance of ther server and the database.
- We can use a proxy to load balance the requests and distribute them between the 2 or more servers that we have. Also, you don't want the client to be requesting 2 IPs at different times so , you just point the client to Proxy's IP and let it handle the rest.
-
This would look something like this:

Here, DB replica refers to a copy of the original database. This replica can be used if the main db goes down.
Probelms :
- The main DB can't handle the load of many requests on its own.
Solution : - We make use of the replica DB also. Here the specifications from DB to DB differ as some databases like MySQL, allow you to write to all DB instances. While others like postgreSQL, mongoDB allow to only write on 1 node (Master node) and read from all(replica nodes). But, these details don't matter as this is a very high level design.
To achieve the above mentioned architecture, we need to introduce a load balancer for DBs also as the requests need to be distributed between the DBs.

Now your interviewer is happy with your design. But they question you that what if the proxy itself goes down? After all it is also a software or a hardware proxy depending on what you have implemented , and can fail anyday.
What trick can you think of from the above designs that help us solve the problem of SPOF (single point of failure) ?. If you guessed that we should add more instances of the same proxy then I guess this article is helping you.
The improved design would look like this:

- Here, unlike the servers, only 1 proxy works at a time (active proxy) and the other one (passive proxy) is idle. In case, the active one fails, the system administrator can possibly assign the IP of the active one to passive one so the systems can continue communicating without any change in their configurations.
Now, the interviewer is satisfied that your system doesn't atleast have a single point of failure and can work as a highly available system.
But, as the requests increase, even 2 database servers can't handle the load. What would you do now? Add more replicas? but that still doesn't solve your problem in the long term.
Make use of microservices architecture
- It is where a single application is developed as a set of small services. The services communicate with each other via APIs often over HTTP.
- Suppose that the system you were asked to design had functionalities like payment service , authentication, and placing an order . Currently, our design has a single DB instance as a whole serving all kinds of requests whether it be for payment or authentication. We should think of seperating these.
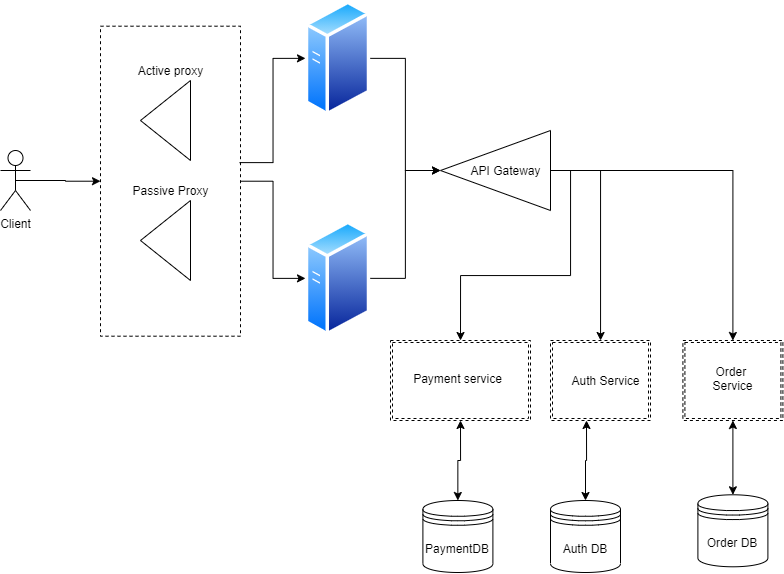
So, is this is finally a good design? NOO!!
- There are various scenarios where your system could go wrong. Network failures, Hardware failures, Natural Disasters, etc.
- But, assuming not everything goes down at once, individually affected components won't affect your whole system's availability.
Improvements ?
- Our system is still synchornous in nature considering that the web servers are doing all the work per request. We need a worker queue to facilitate async processing.
- What if there is a natural disaster and you are running the database servers in a single datacenter which was affected by the disaster? We can add something called a Disaster Recovery servers at a different location which also act as replicas of the main DBs.
Summary
-
We went from a monolithic design to a microservice architecture.
-
I hope the steps and method I followed helped you in understanding how can you tackle a System design problem.
-
System design is a very broad topic and one post alone can't help you crack all kinds of problem statements. I recommend the following posts for different kinds of problems:
-
If you are placed and waiting for your job to start , do read up on this article.
https://leetcode.com/discuss/general-discussion/1122551/What-after-placement-placed-life-set-SDE-9-to-5-Is-DSA-used-in-day-to-day-life
P.S. This was my first article on leetcode. Any and all feedback is appreciated . Thanks!